
Learn how companies like Zillow predict the value of your home. Build a predictive model using Azure machine learning that estimates the real estate sales price of a house.
Ames housing dataset includes 81 features and 1460 observations. Each observation represents the sale of a home and each feature is an attribute describing the house or the circumstance of the sale.
Clone this experiment to build a predictive model
A full copy of this experiment has been posted to the Cortana Intelligence Gallery. Go to the link and click on “open in Studio.”
Preprocessing & data exploration
Drop low-value columns
Begin by identifying features (columns) that add little to no value for predictive modeling. These columns will be dropped using the “select columns from dataset” module.
The following columns were chosen to be “excluded” from the dataset:
Id, Street, Alley, PoolQC, Utilities, Condition2, RoofMatl, MiscVal, PoolArea, 3SsnPorch, LowQualFinSF, MiscFeature, LandSlope, Functional, BsmtHalfBath, ScreenPorch, BsmtFinSF2, EnclosedPorch.
These low-quality features were removed to improve the model’s performance. Low quality includes lack of representative categories, too many missing values, or noisy features.
Define categorical variables
We must now define which values are non-continuous by casting them as categorical. Mathematical approaches for continuous and non-continuous values differ greatly. Nominal categorical features were identified and cast to categorical data types using the metadata editor to ensure proper mathematical treatment by the machine learning algorithm.
The first edit metadata module will cast all strings. The column “MSSubClass” uses numeric integer codes to represent the type of building the house is, and therefore should not be treated as a continuous numeric value but rather a categorical feature. We will use another metadata editor to cast it into a category.
Clean missing data
Most algorithms are unable to account for missing values and some treat it inconsistently from others. To address this, we must make sure our dataset contains no missing, “null,” or “NA” values.
Replacement of missing values is the most versatile and preferred method because it allows us to keep our data. It also minimizes collateral damage to other columns due to one cell’s bad behavior. Numerical values can easily be replaced with statistical values such as mean, median, or mode.
While categories can be commonly dealt with by replacing with the mode or a separate categorical value for unknowns.
For simplicity, all categorical missing values were cleaned with the mode and all numeric features were cleaned using the median. To further improve a model’s performance, custom cleaning functions should be tried and implemented on each individual feature rather than a blanket transformation of all columns.

Machine learning – Model building
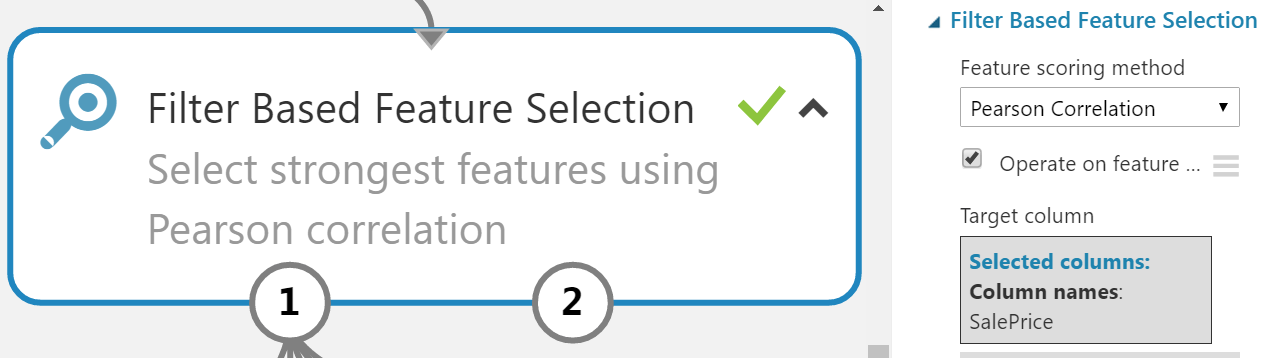
Statistical feature selection
Not every feature in its current form is expected to contain predictive value to the model and may mislead or add noise to the model. To filter these out we will perform a Pearson correlation to test all features against the response class (sales price) as a quick measure of their predictive strength, only picking the top X strongest features from this method, the remaining features will be left behind.
This number can be tuned for further model performance increases.
Select an algorithm
First, we must identify what kind of machine learning problem this is: classification, regression, clustering, etc. Since the response class (sales price) is a continuous numeric value, we can tell that it is a regression problem. We will use a linear regression model with regularization to reduce the over-fitting of the model.
- To ensure a stable convergence of weight and biases, all features except the response class must be normalized to be placed into the same range.

Model training and evaluation
The method of cross-validation will be used to evaluate the predictive performance of the model as well as that performance’s stability in regard to new data. Cross-validation will build ten different models on the same algorithm but with different and non-repeating subsets of the same dataset. The evaluation metrics on each of the ten models will be averaged and a standard deviation will infer the stability of the average performance.
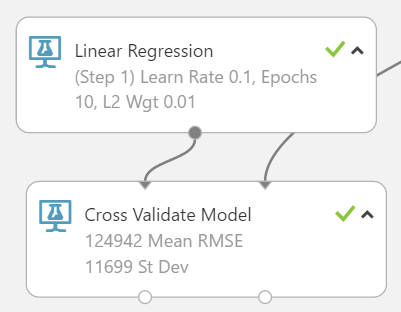
Parameter tuning
This experiment will build a regression model that minimizes the mean RMSE of the cross-validation results with the lowest variance possible(but also considers bias-variance trade-offs).
- The first regression model was built using default parameters and produced a very inaccurate model ($124,942 mean RMSE) and was very unstable (11,699 standard deviation).
- The high bias and high variance of the previous model suggest the model is over-fitting to the outliers and is under-fitting the general population.
- The L2 regularization weight will be decreased to lower the penalty of higher coefficients. After lowering the L2 regularization weight, the model is more accurate with an average cross-validation RMSE of $42,366.
- The previous model is still quite unstable with a standard deviation of $8,121. Since this is a dataset with a small number of observations (1460), it may be better to increase the number of training epochs so that the algorithm has more passes to reach convergence.
- This will increase training times but also increase stability. The third linear model had the number of training epochs increased and saw a better mean cross-validation RMSE of $36,684 and a much more stable standard deviation of $3,849.
- The final model had a slight increase in the learning rate which improved both mean cross-validation RMSE and the standard deviation.

Deployment
The algorithm parameters that yielded the best results will be the ones that are shipped. The best algorithm (the last one) will be retrained using 100% of the data since cross-validation leaves 10% out each time for validation.

Further improvement of this Azure machine learning model
Feature engineering was entirely left out of this experiment. Try engineering more features from the existing dataset to see if the model will improve. Some columns that were originally dropped may become useful when combined with other features. For example, try bucketing the years in which the house was built by decade. Clustering the data may also yield some hidden insights.
Written by Phuc Duong


