

Machine learning (ML) is a field where both art and science converge to create models that can predict outcomes based on data. One of the most effective strategies employed in ML to enhance model performance is ensemble methods.
Rather than relying on a single model, ensemble methods combine multiple models to produce better results. This approach can significantly boost accuracy, reduce overfitting, and improve generalization.
In this blog, we’ll explore various ensemble techniques, their working principles, and their applications in real-world scenarios.

What Are Ensemble Methods?
Ensemble methods are techniques that create multiple models and then combine them to produce a more accurate and robust final prediction. The idea is that by aggregating the predictions of several base models, the ensemble can capture the strengths of each individual model while mitigating their weaknesses.
Also explore this: Azure Machine Learning in 5 Simple Steps
Why Use Ensemble Methods?
Ensemble methods are used to improve the robustness and generalization of machine learning models by combining the predictions of multiple models. This can reduce overfitting and improve performance on unseen data.
Read more Gini Index and Entropy
Types of Ensemble Methods
There are three primary types of ensemble methods: Bagging, Boosting, and Stacking.
Bagging (Bootstrap Aggregating)
Bagging involves creating multiple subsets of the original dataset using bootstrap sampling (random sampling with replacement). Each subset is used to train a different model, typically of the same type, such as decision trees. The final prediction is made by averaging (for regression) or voting (for classification) the predictions of all models.
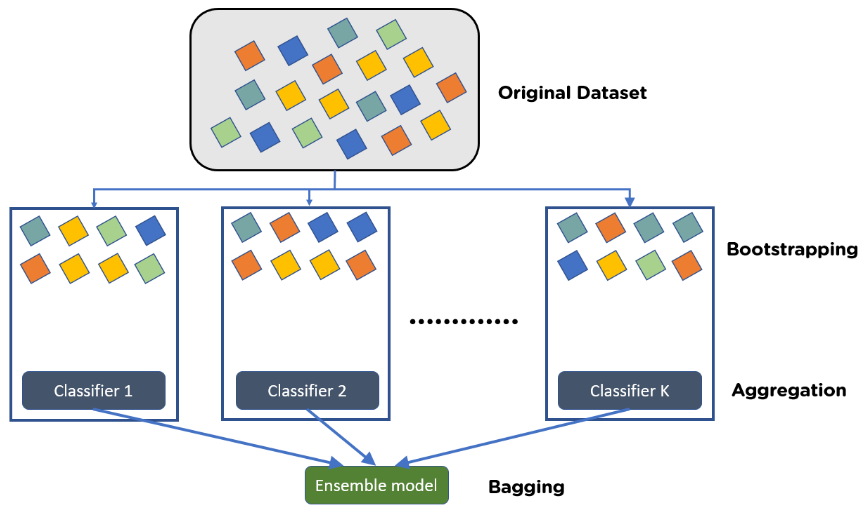
How Bagging Works:
- Bootstrap Sampling: Create multiple subsets from the original dataset by sampling with replacement.
- Model Training: Train a separate model on each subset.
- Aggregation: Combine the predictions of all models by averaging (regression) or majority voting (classification).
Random Forest
Random Forest is a popular bagging method where multiple decision trees are trained on different subsets of the data, and their predictions are averaged to get the final result.
Boosting
Boosting is a sequential ensemble method where models are trained one after another, each new model focusing on the errors made by the previous models. The final prediction is a weighted sum of the individual model’s predictions.
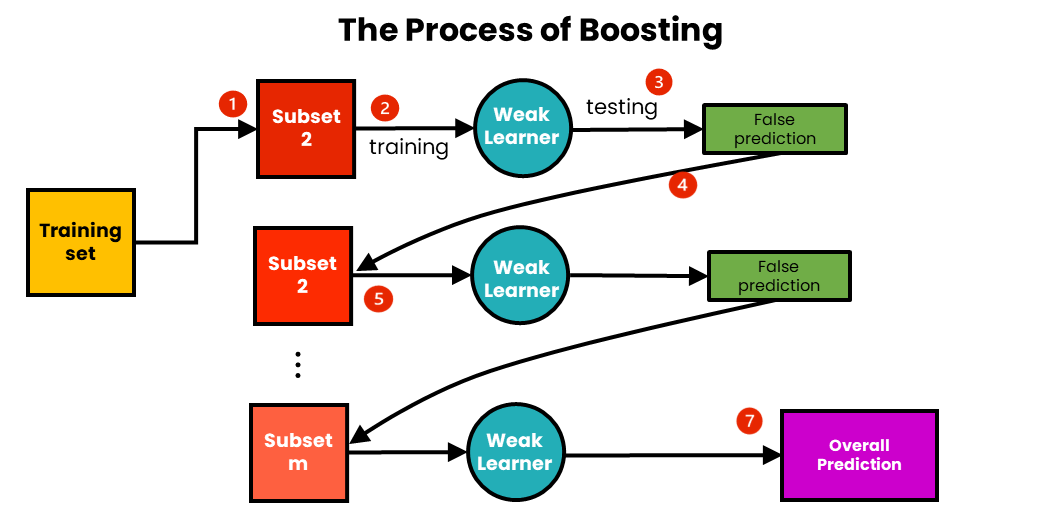
How Boosting Works:
- Initialize Weights: Start with equal weights for all data points.
- Sequential Training: Train a model and adjust weights to focus more on misclassified instances.
- Aggregation: Combine the predictions of all models using a weighted sum.
AdaBoost (Adaptive Boosting)
It assigns weights to each instance, with higher weights given to misclassified instances. Subsequent models focus on these hard-to-predict instances, gradually improving the overall performance.
You might also like: ML using Python in Cloud
Gradient Boosting
It builds models sequentially, where each new model tries to minimize the residual errors of the combined ensemble of previous models using gradient descent.
XGBoost (Extreme Gradient Boosting)
An optimized version of Gradient Boosting, known for its speed and performance, is often used in competitions and real-world applications.
Stacking
Stacking, or stacked generalization, involves training multiple base models and then using their predictions as inputs to a higher-level meta-model. This meta-model is responsible for making the final prediction.
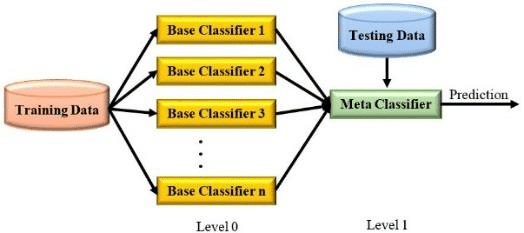
How Stacking Works:
- Base Model Training: Train multiple base models on the training data.
- Meta-Model Training: Use the predictions of the base models as features to train a meta-model.
Example:
A typical stacking ensemble might use logistic regression as the meta-model and decision trees, SVMs, and KNNs as base models.

Benefits of Ensemble Methods
Improved Accuracy
By combining multiple models, ensemble methods can significantly enhance prediction accuracy.
Robustness
Ensemble models are less sensitive to the peculiarities of a particular dataset, making them more robust and reliable.
Reduction of Overfitting
By averaging the predictions of multiple models, ensemble methods reduce the risk of overfitting, especially in high-variance models like decision trees.
Versatility
Ensemble methods can be applied to various types of data and problems, from classification to regression tasks.
Applications of Ensemble Methods
Ensemble methods have been successfully applied in various domains, including:
- Healthcare: Improving the accuracy of disease diagnosis by combining different predictive models.
- Finance: Enhancing stock price prediction by aggregating multiple financial models.
- Computer Vision: Boosting the performance of image classification tasks with ensembles of CNNs.
Here’s a list of the top 7 books to master your learning on computer vision
Implementing Random Forest in Python
Now let’s walk through the implementation of a Random Forest classifier in Python using the popular scikit-learn library. We’ll use the Iris dataset, a well-known dataset in the machine learning community, to demonstrate the steps involved in training and evaluating a Random Forest model.
Explanation of the Code
Import Necessary Libraries
We start by importing the necessary libraries. numpy is used for numerical operations, train_test_split for splitting the dataset, RandomForestClassifier for building the model, accuracy_score for evaluating the model, and load_iris to load the Iris dataset.
Load the Iris Dataset
The Iris dataset is loaded using load_iris(). The dataset contains four features (sepal length, sepal width, petal length, and petal width) and three classes (Iris setosa, Iris versicolor, and Iris virginica).
Split the Dataset
We split the dataset into training and testing sets using train_test_split(). Here, 30% of the data is used for testing, and the rest is used for training. The random_state parameter ensures the reproducibility of the results.
Initialize the RandomForestClassifier
We create an instance of the RandomForestClassifier with 100 decision trees (n_estimators=100). The random_state parameter ensures that the results are reproducible.
Train the Model
We train the Random Forest classifier on the training data using the fit() method.
Make Predictions
After training, we use the predict() method to make predictions on the testing data.
Evaluate the Model
Finally, we evaluate the model’s performance by calculating the accuracy using the accuracy_score() function. The accuracy score is printed to two decimal places.
Output Analysis
When you run this code, you should see an output similar to:
This output indicates that the Random Forest classifier achieved 100% accuracy on the testing set. This high accuracy is expected for the Iris dataset, as it is relatively small and simple, making it easy for many models to achieve perfect or near-perfect performance.
In practice, the accuracy may vary depending on the complexity and nature of the dataset, but Random Forests are generally robust and reliable classifiers.
By following this guided practice, you can see how straightforward it is to implement a Random Forest model in Python. This powerful ensemble method can be applied to various datasets and problems, offering significant improvements in predictive performance.

Summing it Up
To sum up, Ensemble methods are powerful tools in the machine learning toolkit, offering significant improvements in predictive performance and robustness. By understanding and applying techniques like bagging, boosting, and stacking, you can create models that are more accurate and reliable.
Ensemble methods are not just theoretical constructs; they have practical applications in various fields. By leveraging the strengths of multiple models, you can tackle complex problems with greater confidence and precision.