

When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source LLMs. Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely.
Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data and break free from the traditional limitations associated with LLMs.
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab.
Prequisites to Chat with Your CSV Files
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign-up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
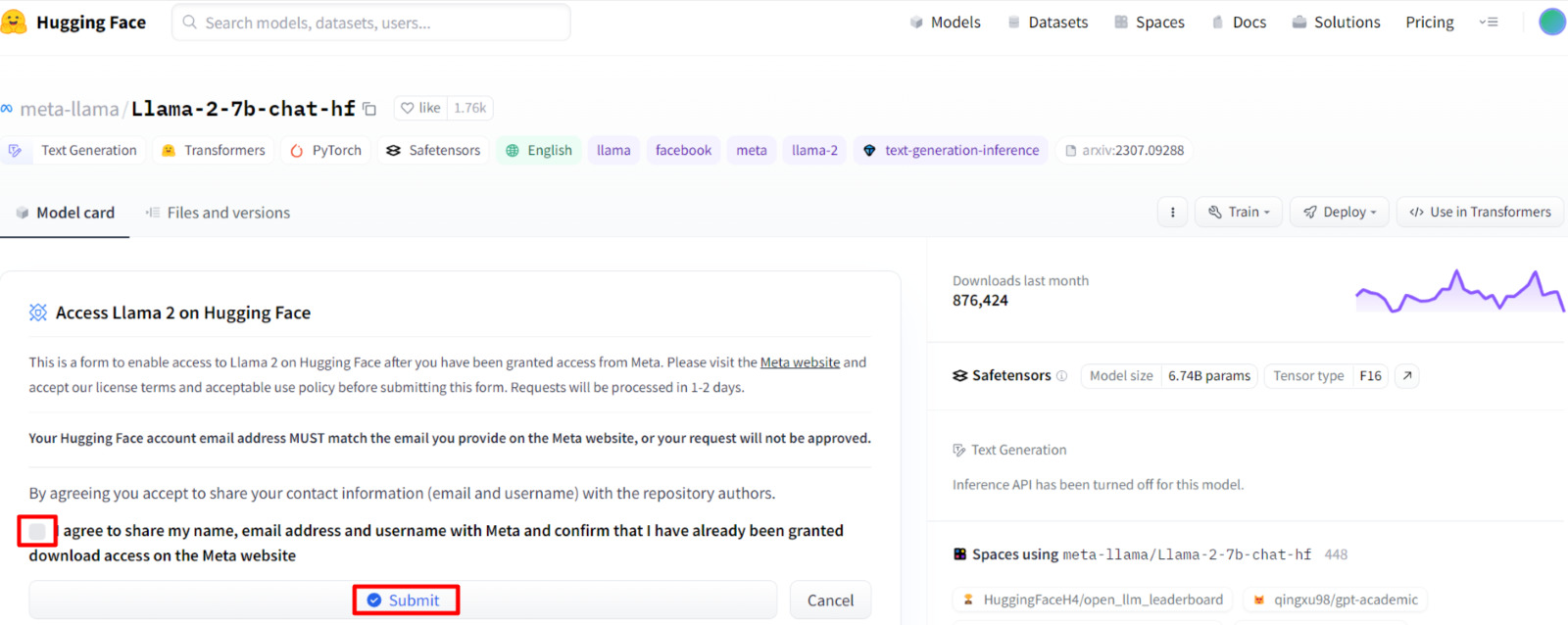
Once you have been granted access to Llama 2 models, visit the following link and select the checkbox shown in the image below and hit ‘Submit. ’
Setting Up a Google Colab Environment
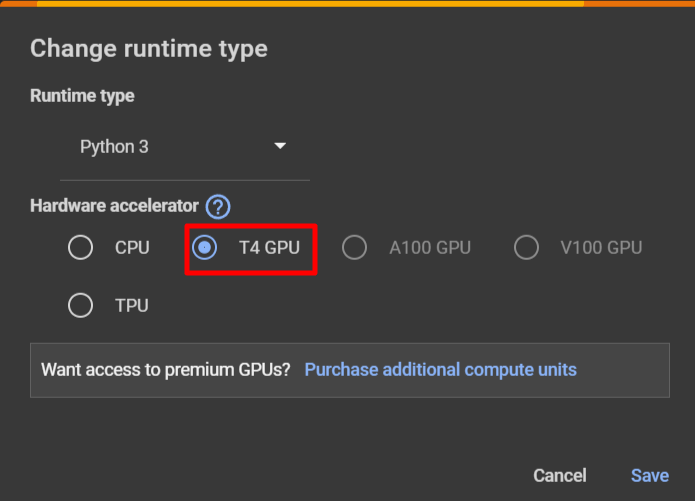
If running on Google Colab, you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
Installing Necessary Libraries and Dependencies
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
Authenticating with HuggingFace
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
Import Relevant Libraries
Initializing the HuggingFace Pipeline
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first:
- An LLM, in this case, will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab, this can take 2-5 minutes to download and initialize the model.
Load HuggingFace Open-Source Embeddings Models
Embeddings are crucial for language models because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
Load CSV Data Using LangChain CSV Loader
The LangChain CSV loader loads CSV data in a single row per document. For this demo, we are using an employee sample data CSV file, which is uploaded in Colab’s environment.
Creating Vectorstore
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
Initializing Retrieval QA Chain and Testing Sample Query
We are now going to use the Retrieval QA chain of LangChain, which combines vector store with a question answering chain to do question answering.
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
Learn all about retrieval augmented generation
Building a Gradio App
Now, we are going to merge the above code snippets to create a gradio application

Function Definitions
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating an FAISS vector store, and returning the first 5 rows of the dataset.
Gradio Interface Setup
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column(): Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data, qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.

Launching the Gradio Interface
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real time. The interface also showcases a sample dataset and questions for user guidance.
Output
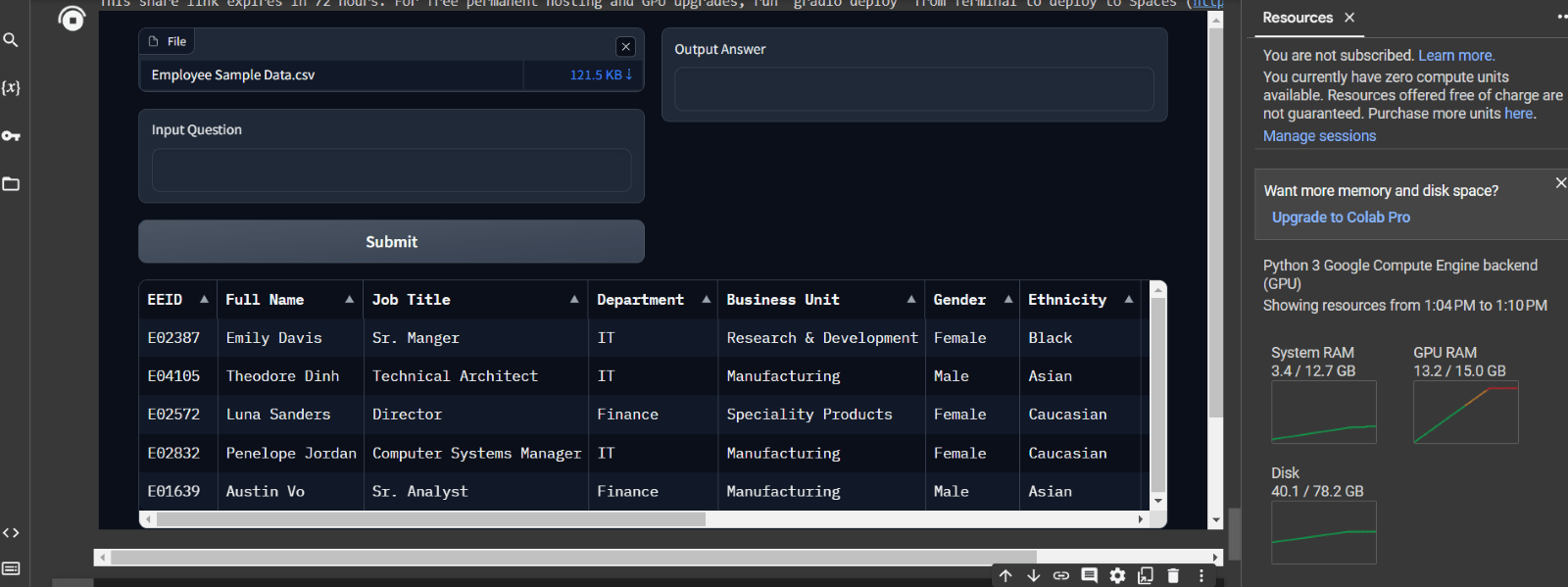
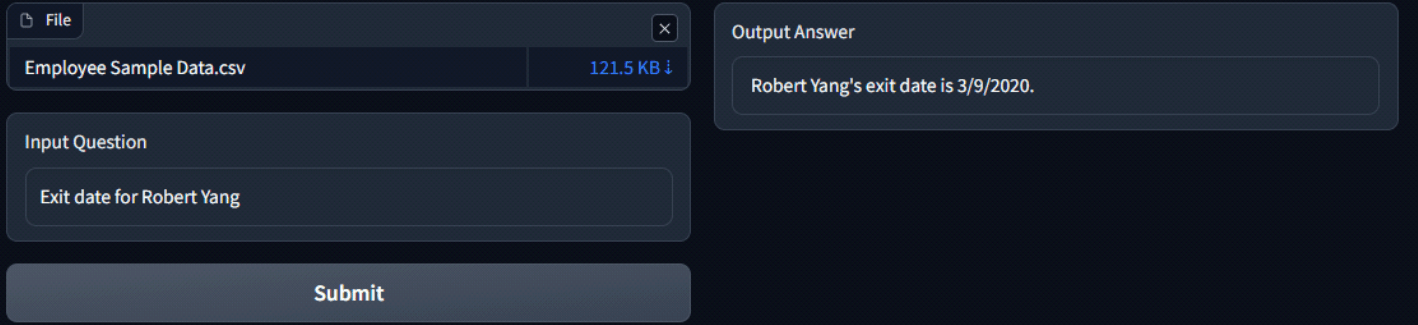
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a CSV file, which is then passed through the embeddings model to generate embeddings. Once this process is done, the first 5 rows of the file are displayed for preview.
Now the user can input the question and Hit ‘Submit’ to generate an answer.
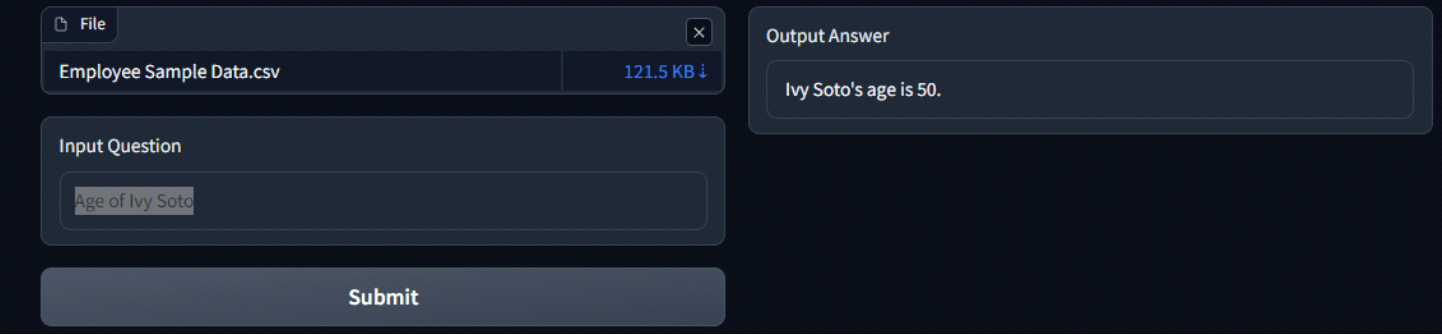

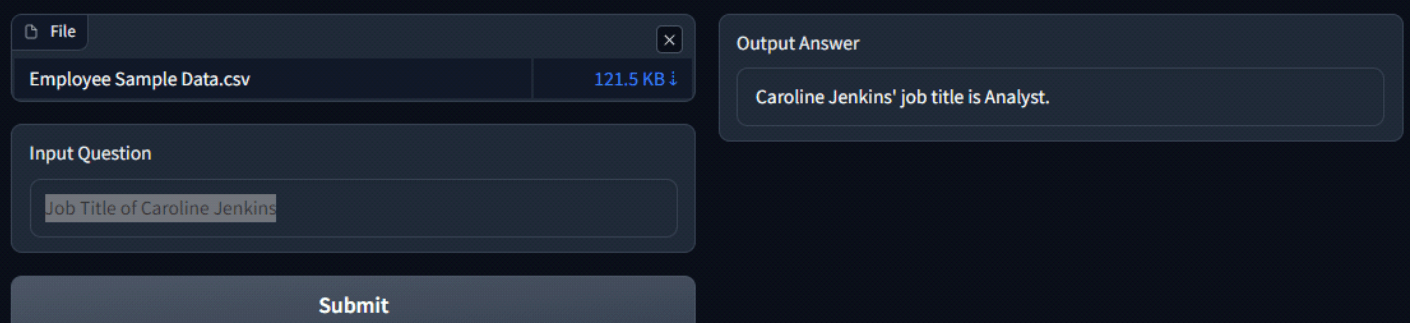
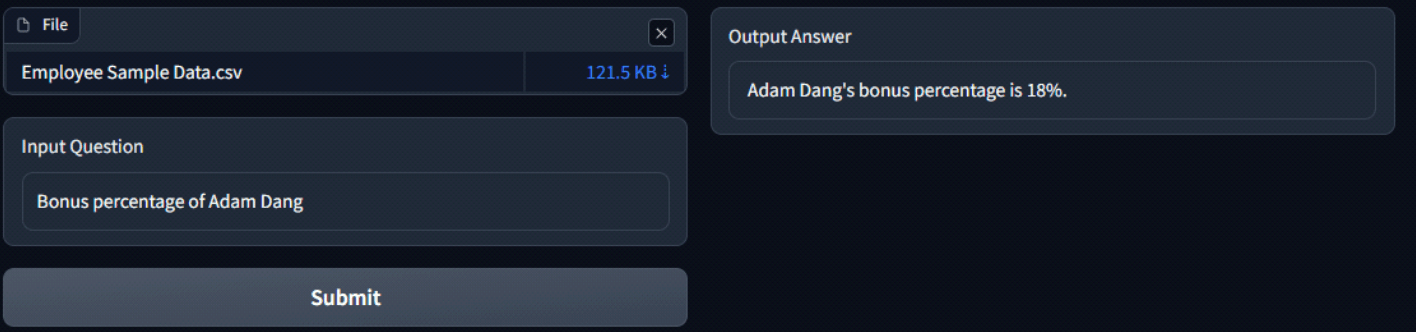
Conclusion
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab.
By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.

As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.
Converse with Your Data: Chatting with CSV Files Using Open-Source Tools
Explore a step-by-step journey in crafting dynamic chatbot experiences tailored to your CSV data using Gradio, LLAMA2, and Hugging Face on Google Colab
“When diving into the world of Language Model usage, one often encounters barriers such as the necessity for a paid API or the need for a robust computing system when working with open-source Language Models (LLMs). Eager to overcome these constraints, I embarked on a journey to develop a Gradio App using open-source tools completely. Harnessing the power of the free Colab T4 GPU and an open-source LLM, this blog will guide you through the process, empowering you to effortlessly chat with your own CSV data, breaking free from the traditional limitations associated with LLMs.”
PREREQUISITES
- A Hugging Face account to access open-source Llama 2 and embedding models (free sign up available if you don’t have one).
- Access to LLAMA2 models, obtainable through this form (access is typically granted within a few hours).
- A Google account for using Google Colab.
Once you have been granted access to Llama 2 models visit the following link and select the checkbox shown in the image below and hit ‘Submit’.
SETTING UP GOOGLE COLAB ENVIRONMENT
If running on Google Colab you go to **Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4. Our code will require ~15GB of GPU RAM.
INSTALLING NECESSARY LIBRARIES AND DEPENDENCIES
The following snippet streamlines the installation process, ensuring that all necessary components are readily available for our project
!pip install –q transformers einops accelerate langchain bitsandbytes sentence_transformers faiss–cpu gradio pypdf sentencepiece
AUTHENTICATING WITH HUGGING FACE
To integrate your Hugging Face token into Colab’s environment, follow these steps.
- Execute the following code in a Colab cell:
!huggingface–cli login
- After running the cell, a prompt will appear, requesting your Hugging Face token.
- Obtain your Hugging Face token by navigating to the Hugging Face settings. Look for the “Access Token” tab, where you can easily copy your token.
IMPORTING RELEVANT LIBRARIES
from langchain import HuggingFacePipeline
from transformers import AutoTokenizer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders.csv_loader import CSVLoader
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import transformers
import torch
import gradio
import textwrap
INITIALIZING THE HUGGING FACE PIPELINE
The first thing we need to do is initialize a text-generation pipeline with Hugging Face transformers. The Pipeline requires three things that we must initialize first, those are:
- An LLM, in this case it will be meta-llama/Llama-2-7b-chat-hf.
- The respective tokenizer for the model.
We initialize the model and move it to our CUDA-enabled GPU. Using Colab this can take 2-5 minutes to download and initialize the model.
model = “meta-llama/Llama-2-7b-chat-hf”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”, #task
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=“auto”,
max_length=1000,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0})
LOAD HUGGING FACE OPEN-SOURCE EMBEDDINGS MODEL
Embeddings are crucial for Language Model (LM) because they transform words or tokens into numerical vectors, enabling the model to understand and process them mathematically. In the context of LLMs:
- Semantic Representation: Embeddings encode semantic relationships, placing similar words close in vector space for the model to understand nuanced language context.
- Numerical Input for Models: Transforming words into numerical vectors, embeddings provide a mathematical foundation for neural networks, ensuring effective processing within the model.
- Dimensionality Reduction: Embeddings condense high-dimensional word representations, enhancing computational efficiency while preserving essential linguistic features.
- Transfer Learning: Pre-trained embeddings capture general language patterns, facilitating knowledge transfer to specific tasks, boosting model performance on diverse datasets.
- Contextual Information: Embeddings, considering adjacent words, capture contextual nuances, enabling Language Models to generate coherent and contextually relevant language.
embeddings = HuggingFaceEmbeddings(model_name=‘sentence-transformers/all-MiniLM-L6-v2’,model_kwargs={‘device’: ‘cpu’})
LOAD CSV DATA USING LANGCHAIN CSV LOADER
LangChain CSV loader loads csv data with a single row per document. For this demo we are using employee sample data csv file which is uploaded in colab’s environment.
loader = CSVLoader(‘/content/Employee Sample Data.csv’, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
CREATING VECTORSTORE
For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
vectorstore = FAISS.from_documents(data, embeddings)
INITIALIZING RETRIEVAL QA CHAIN AND TESTING SAMPLE QUERY
We are now going to use Retrieval QA chain of LangChain which combines vector store with a question answering chain to do question answering.
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=True, retriever=vectorstore.as_retriever())
query = “What is the annual salary of Sophie Silva?”
result=chain(query)
wrapped_text = textwrap.fill(result[‘result’], width=500)
wrapped_text
The above code utilizes the RetrievalQA module to answer a specific query about the annual salary of Sophie Silva, including the retrieval of source documents. The result is then formatted for better readability by wrapping the text to a maximum width of 500 characters.
BUILDING A GRADIO APP
Now we are going to merge the above code snippets to create a gradio application
import gradio as gr
import pandas as pd
def main(dataset,qs):
#df = pd.read_csv(dataset.name)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type = “stuff”,return_source_documents=False, retriever=vectorstore.as_retriever())
#query = “What is the annual salary of Sophie Silva?”
result=chain(qs)
wrapped_text = textwrap.fill(result[‘result’], width=500)
return wrapped_text
def dataset_change(dataset):
global vectorstore
loader = CSVLoader(dataset.name, encoding=“utf-8”, csv_args={‘delimiter’: ‘,’})
data = loader.load()
vectorstore = FAISS.from_documents(data, embeddings)
df = pd.read_csv(dataset.name)
return df.head(5)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
data = gr.File()
qs = gr.Text(label=“Input Question”)
submit_btn = gr.Button(“Submit”)
with gr.Column():
answer = gr.Text(label=“Output Answer”)
with gr.Row():
dataframe = gr.Dataframe()
submit_btn.click(main, inputs=[data,qs], outputs=[answer])
data.change(fn=dataset_change,inputs = data,outputs=[dataframe])
gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs])
demo.launch(debug=True)
The above code sets up a Gradio interface on Colab for a question-answering application using LLAMA2 and FAISS. Here’s a brief overview:
- Function Definitions:
- main: Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
- dataset_change: Changes in the dataset trigger this function, loading the dataset, creating a FAISS vector store, and returning the first 5 rows of the dataset.
- Gradio Interface Setup:
- with gr.Blocks() as demo: Initializes a Gradio interface block.
- with gr.Row(): and with gr.Column():: Defines the layout of the interface with file input, text input for the question, a button to submit the question, and a text box to display the answer.
- with gr.Row(): and dataframe = gr.Dataframe(): Includes a row for displaying the first 5 rows of the dataset.
- submit_btn.click(main, inputs=[data,qs], outputs=[answer]): Associates the main function with the click event of the submit button, taking inputs from the file and question input and updating the answer text box.
- data.change(fn=dataset_change,inputs=data,outputs=[dataframe]): Calls the dataset_change function when the dataset changes, updating the dataframe display accordingly.
- gr.Examples([[“What is the Annual Salary of Theodore Dinh?”], [“What is the Department of Parker James?”]], inputs=[qs]): Provides example questions for users to input.
- Launching the Gradio Interface:
- demo.launch(debug=True): Launches the Gradio interface in debug mode.
In summary, this code creates a user-friendly Gradio interface for interacting with a question-answering system. Users can input a CSV dataset, ask questions about the data, and receive answers displayed in real-time. The interface also showcases a sample dataset and questions for user guidance.
OUTPUT
Attached below are some screenshots of the app and the responses of LLM. The process kicks off by uploading a csv file, which is then passed through the embeddings model to generate embeddings. Once this process is done the first 5 rows of the file are displayed for preview. Now the user can input the question and Hit ‘Submit’ to generate answer.
CONCLUSION
In conclusion, this blog has demonstrated the empowerment of language models through the integration of LLAMA2, Gradio, and Hugging Face on Google Colab. By overcoming the limitations of paid APIs and compute-intensive open-source models, we’ve successfully created a dynamic Gradio app for personalized interactions with CSV data. Leveraging LangChain question-answering chains and Hugging Face’s model integration, this hands-on guide enables users to build chatbots that comprehend and respond to their own datasets.
As technology evolves, this blog encourages readers to explore, experiment, and continue pushing the boundaries of what can be achieved in the realm of natural language processing.