




Metrics Used in LLM Evaluation
After defining what LLM evaluation is and exploring key benchmarks, it’s time to dive into metrics—the tools that score and quantify model performance.
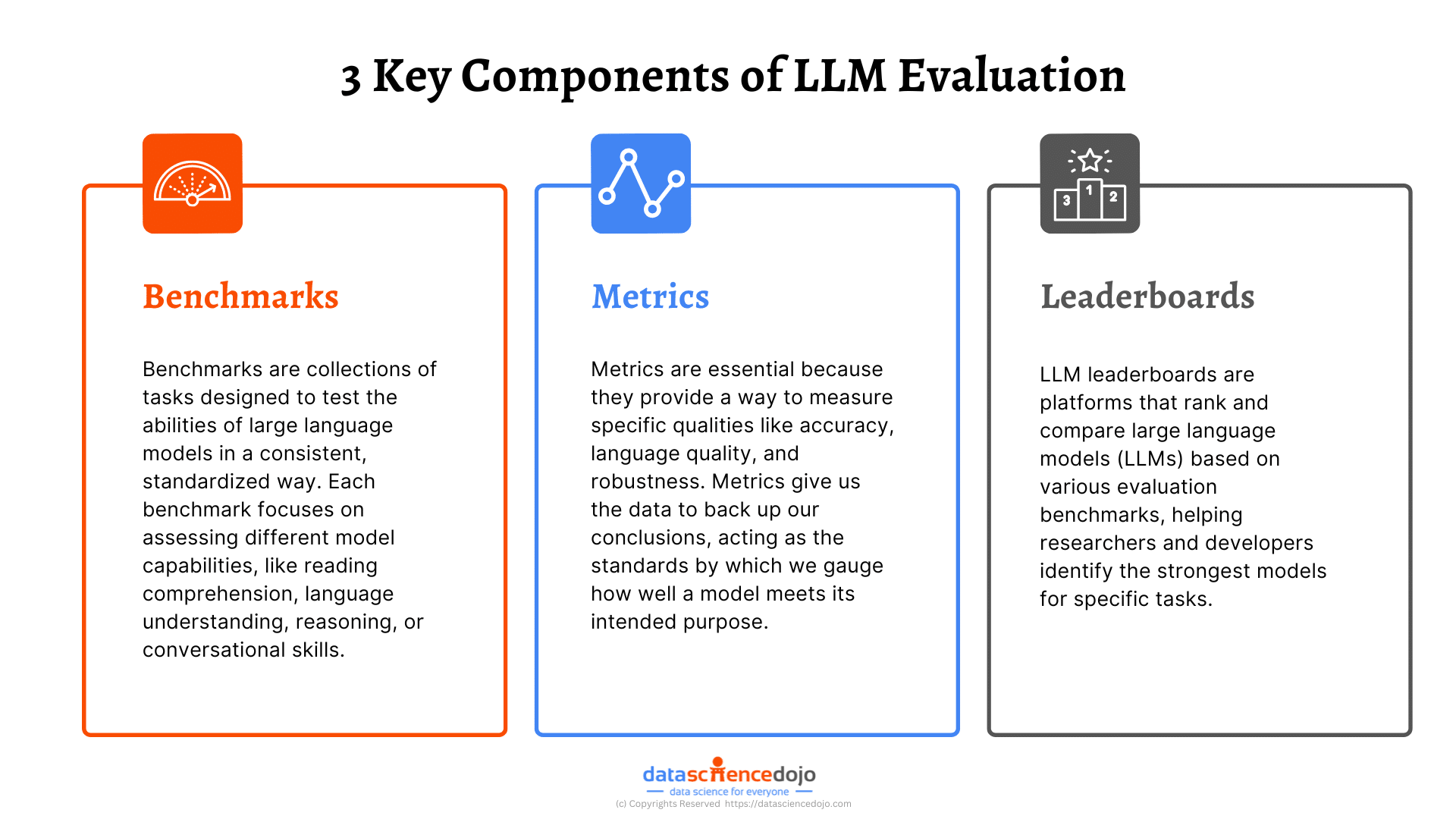
In LLM evaluation, metrics are essential because they provide a way to measure specific qualities like accuracy, language quality, and robustness. Without metrics, we’d only have subjective opinions on model performance, making it difficult to objectively compare models or track improvements.
Metrics give us the data to back up our conclusions, acting as the standards by which we gauge how well a model meets its intended purpose.
These metrics can be organized into three primary categories based on the type of performance they assess:
- Language Quality and Coherence
- Semantic Understanding and Contextual Relevance
- Robustness, Safety, and Ethical Alignment
Explore the list of leading LLM evaluation metrics you must know
1. Language Quality and Coherence Metrics
Purpose
Language quality and coherence metrics evaluate the fluency, clarity, and readability of generated text. In tasks like translation, summarization, and open-ended text generation, these metrics assess whether a model’s output is well-structured, natural, and easy to understand, helping us determine if a model’s language production feels genuinely human-like.
Key Metrics
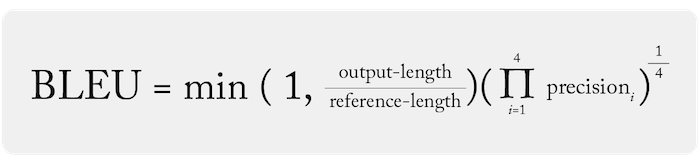
- BLEU (Bilingual Evaluation Understudy): BLEU measures the overlap between generated text and a reference text, focusing on how well the model’s phrasing matches the expected answer. It’s widely used in machine translation and rewards precision in word choice, offering insights into how well a model generates accurate language.

Source: Arize AI - ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE measures how much of the content from the original text is preserved in the generated summary. Commonly used in summarization, ROUGE captures recall over precision, meaning it’s focused on ensuring the model includes the essential ideas of the original text, rather than mirroring it word-for-word.
- Perplexity: Perplexity measures the model’s ability to predict a sequence of words. A lower perplexity score indicates the model generates more fluent and natural-sounding language, which is critical for ensuring readability in generated content. It’s particularly helpful in assessing language models intended for storytelling, dialogue, and other open-ended tasks where coherence is key.
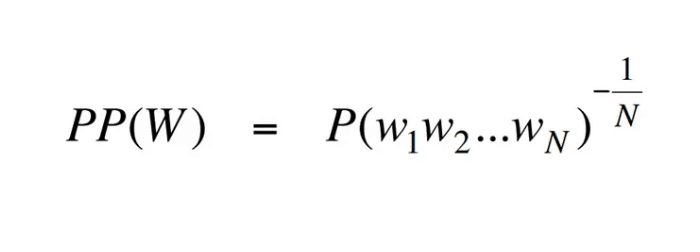
2. Semantic Understanding and Contextual Relevance Metrics
Purpose
Semantic understanding and contextual relevance metrics assess how well a model captures the intended meaning and stays contextually relevant. These metrics are particularly valuable in tasks where the specific words used are less important than conveying the correct overall message, such as paraphrasing and sentence similarity.
Key Metrics
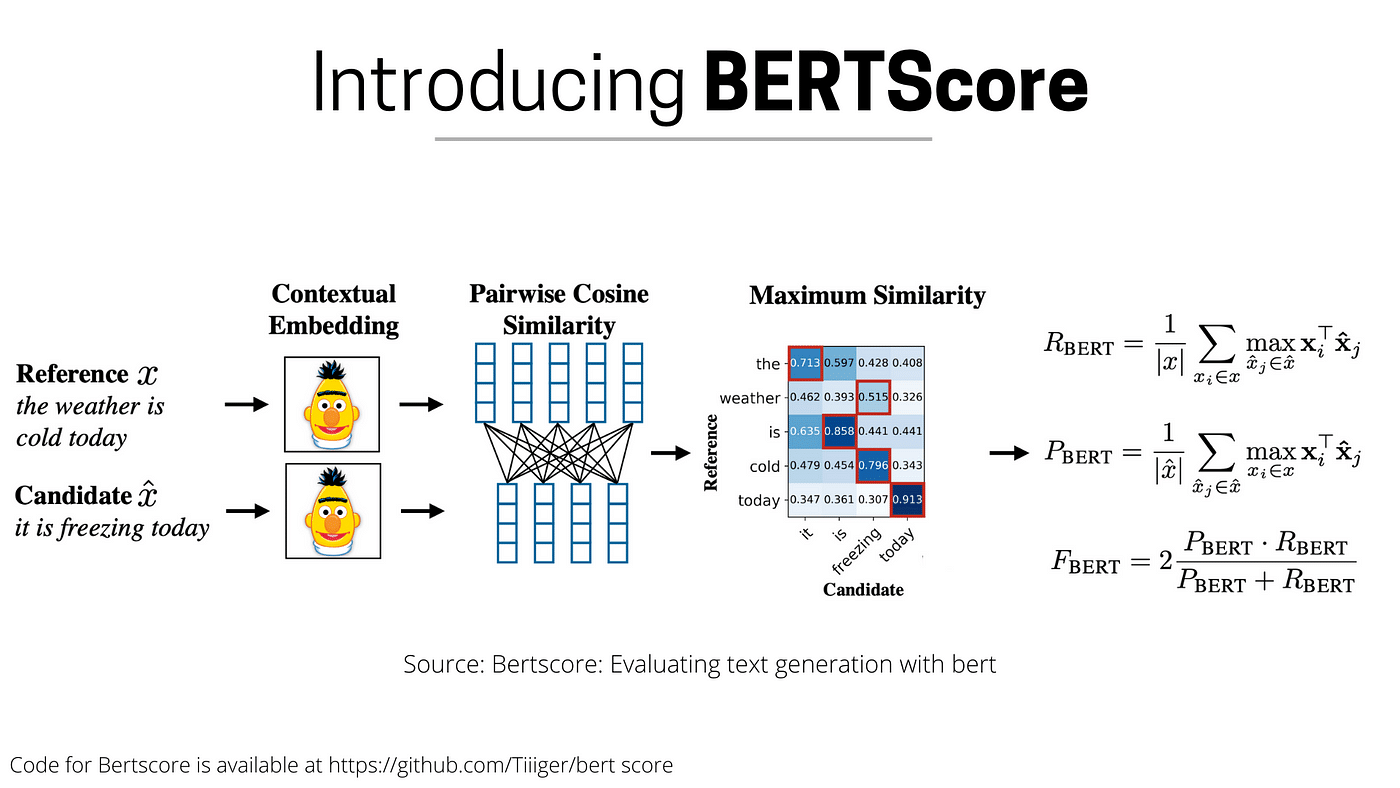
- BERTScore: BERTScore uses embeddings from pre-trained language models (like BERT) to measure the semantic similarity between the generated text and reference text. By focusing on meaning rather than exact wording, BERTScore is ideal for tasks where preserving meaning is more important than matching words exactly.

Source: Towards Data Science - Faithfulness: Faithfulness measures the factual consistency of the generated answer relative to the given context. It evaluates whether the model’s response remains accurate to the provided information, making it essential for applications that prioritize factual accuracy, like summarization and factual reporting.

Source: Towards Data Science - Answer Relevance: Answer Relevance assesses how well an answer aligns with the original question. This metric is often calculated by averaging the cosine similarities between the original question and several paraphrased versions. Answer Relevance is crucial in question-answering tasks where the response should directly address the user’s query.

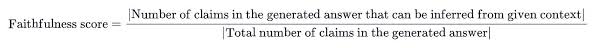

3. Robustness, Safety, and Ethical Alignment Metrics
Purpose
Robustness, safety, and ethical alignment metrics measure a model’s resilience to challenging inputs and ensure it produces responsible, unbiased outputs. These metrics are critical for models deployed in real-world applications, as they help ensure that the model won’t generate harmful, offensive, or biased content and that it will respond appropriately to various user inputs.
Key Metrics
- Demographic Parity: Ensures that positive outcomes are distributed equally across demographic groups. This means the probability of a positive outcome should be the same across all groups. It’s essential for fair treatment in applications where equal access to benefits is desired.
- Equal Opportunity: Ensures fairness in true positive rates by making sure that qualified individuals across all demographic groups have equal chances for positive outcomes. This metric is particularly valuable in scenarios like hiring, where equally qualified candidates from different backgrounds should have the same likelihood of being selected.
- Counterfactual Fairness: Measures whether the outcome remains the same for an individual if only their demographic attribute changes (e.g., gender or race). This ensures the model’s decisions aren’t influenced by demographic features irrelevant to the outcome.
