In this blog, we’re diving into a new approach called rank-based encoding that promises not just to shake things up but to guarantee top-notch results.
Rank-Based Encoding – A Breakthrough?
Say hello to rank-based encoding – a technique you probably haven’t heard much about yet, but one that’s about to change the game.
In the vast world of machine learning, getting your data ready is like laying the groundwork for success. One key step in this process is encoding – a way of turning non-numeric information into something our machine models can understand. This is particularly important for categorical features – data that is not in numbers.
Join us as we explore the tricky parts of dealing with non-numeric features, and how rank-based encoding steps in as a unique and effective solution. Get ready for a breakthrough that could redefine your machine-learning adventures – making them not just smoother but significantly more impactful.
Here’s a list of common data analyst interview questions for you
Problem Under Consideration
In our blog, we’re utilizing a dataset focused on House Price Prediction to illustrate various encoding techniques with examples. In this context, we’re treating the city categorical feature as our input, while the output feature is represented by the price.

Some Common Techniques
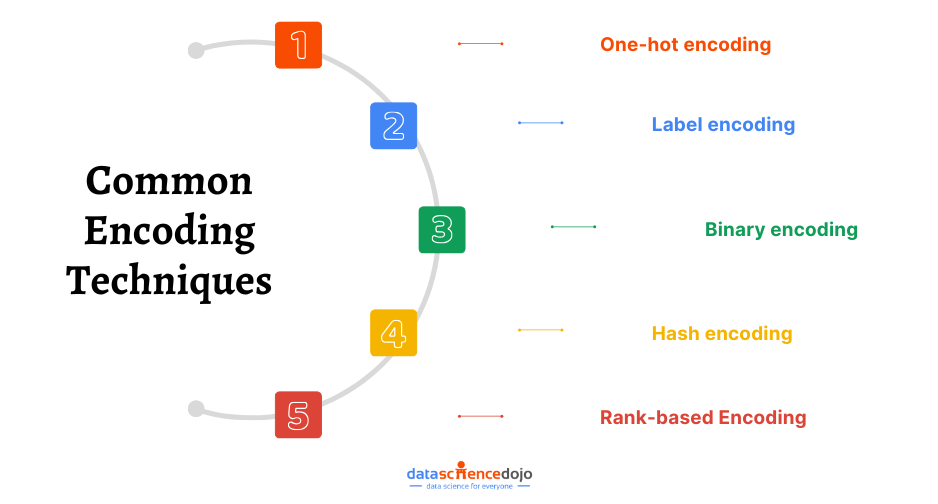
The following section will cover some of the commonly used techniques and their challenges. We will conclude by digging deeper into rank-based encoding and how it overcomes these challenges.
- One-Hot Encoding
In One-hot encoding, each category value is represented as an n-dimensional, sparse vector with zero entries except for one of the dimensions. For example, if there are three values for the categorical feature City, i.e. Chicago, Boston, Washington DC, the one-hot encoded version of the city will be as depicted in Table 1.
If there is a wide range of categories present in a categorical feature, one-hot encoding increases the number of columns(features) linearly which requires high computational power during the training phase.
| City | City Chicago | City Boston | Washington DC |
| Chicago | 1 | 0 | 0 |
| Boston | 0 | 1 | 0 |
| Washington DC | 0 | 0 | 1 |
Table 1
- Label encoding
This technique assigns a label to each value of a categorical column based on alphabetical order. For example, if there are three values for the categorical feature City, i.e. Chicago, Boston, Washington DC, the label encoded version will be as depicted in Table 2.
Since B comes first in alphabetical order, this technique assigns Boston the label 0, which leads to meaningless learning of parameters.
| City | City Label Encoding |
| Chicago | 1 |
| Boston | 0 |
| Washington DC | 2 |
Table 2
- Binary encoding
It involves converting each category into a binary code and then splitting the resulting binary string into columns. For example, if there are three values for the categorical feature City, i.e. Chicago, Boston, Washington DC, the binary encoded version of a city can be observed from Table 3.
Since there are 3 cities, two bits would be enough to uniquely represent each category. Therefore, two columns will be constructed which increases dimensions. However, this is not meaningful learning as we are assigning more weightage to one category than others.
Chicago is assigned 00, so our model would give it less weightage during the learning phase. If any categorical column has a wide range of unique values, this technique requires a large amount of computational power, as an increase in the number of bits results in an increase in the number of dimensions (features) significantly.
| City | City 0 | City 1 |
| Chicago | 0 | 0 |
| Boston | 0 | 1 |
| Washington DC | 1 | 0 |
Table 3
- Hash encoding
It uses the hashing function to convert category data into numerical values. Using hashed functions solves the problem of a high number of columns if the categorical feature has a large number of categories. We can define how many numerical columns we want to encode our feature into.
However, in the case of high cardinality of a categorical feature, while mapping it into a lower number of numerical columns, loss of information is inevitable. If we use a hash function with one-to-one mapping, the result would be the same as one-hot encoding.
You can also explore different types of statistical distributions
- Rank-based Encoding
In this blog, we propose rank-based encoding which aims to encode the data in a meaningful manner with no increase in dimensions. Thus, eliminating the increased computational complexity of the algorithm as well as preserving all the information of the feature.
Rank-based encoding works by computing the average of the target variable against each category of the feature under consideration. This average is then sorted in decreasing order from high to low and each category is assigned a rank based on the corresponding average of a target variable. An example is illustrated in Table 4 which is explained below:
The average price of Washington DC = (60 + 55)/2 = 57.5 Million
The average price of Boston = (20 +12+18)/3 = 16.666 Million
The average price of Chicago = (40 + 35)/2 = 37.5 Million
In the rank-based encoding process, each average value is assigned a rank in descending order.
For instance, Washington DC is given rank 1, Chicago gets rank 2, and Boston is assigned rank 3. This technique significantly enhances the correlation between the city (input feature) and price variable (output feature), ensuring more efficient model learning.

In my evaluation, I assessed model metrics such as R2 and RMSE. The results demonstrated significantly lower values compared to other techniques discussed earlier, affirming the effectiveness of this approach in improving overall model performance.
| City | Price | City Rank |
| Washington DC | 60 Million | 1 |
| Boston | 20 Million | 3 |
| Chicago | 40 Million | 2 |
| Chicago | 35 Million | 2 |
| Boston | 12 Million | 3 |
| Washington DC | 55 Million | 1 |
| Boston | 18 Million | 3 |
Table 4
Dig deeper into understanding what is categorical data encoding
Results
We summarize the pros and cons of each technique in Table 5. Rank-based encoding emerges to be the best in all aspects. Effective data preprocessing is crucial for the optimal performance of machine learning models. Among the various techniques, rank-based encoding is a powerful method that contributes to enhanced model learning.
The rank-based encoding technique facilitates a stronger correlation between input and output variables, leading to improved model performance. The positive impact is evident when evaluating the model using metrics like RMSE and R2 etc. In our case, these enhancements reflect a notable boost in overall model performance.
| Encoding Technique | Meaningful Learning | Loss of Information | Increase in Dimensionality |
| One-hot | ✓ | x | ✓ |
| Label | x | x | ✓ |
| Binary | x | x | ✓ |
| Hash | ✓ | ✓ | x |
| Rank-based | ✓ | x | x |
Table 5