

Zero-shot, one-shot, and few-shot learning is redefining how machines adapt and learn, promising a future where adaptability and generalization reach unprecedented levels. In the dynamic field of artificial intelligence, traditional machine learning, reliant on extensive labeled datasets, has given way to transformative learning paradigms.
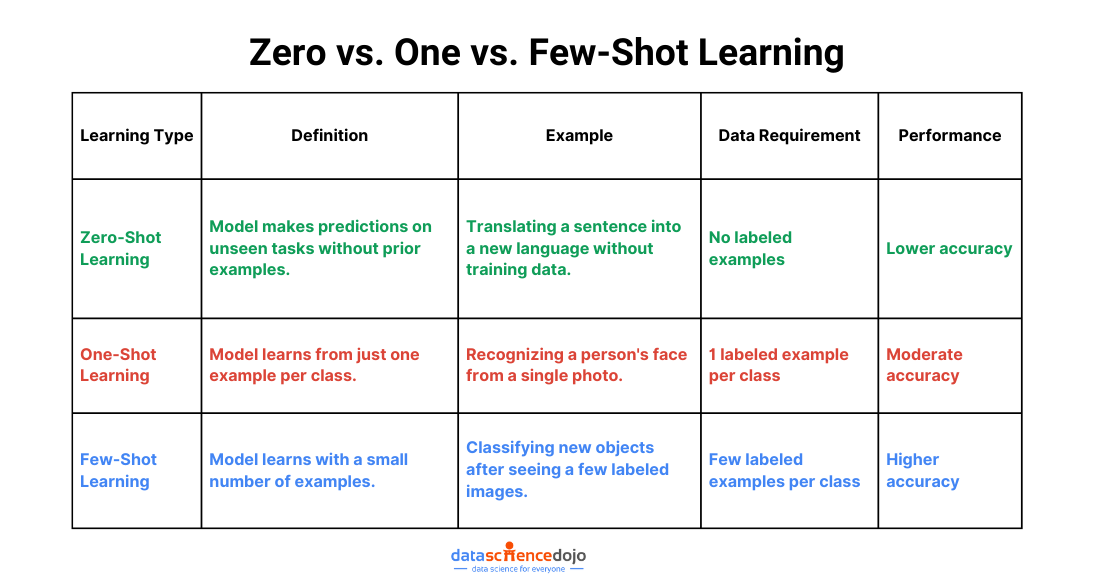
In this exploration, we navigate from the basics of supervised learning to the forefront of adaptive models. These approaches enable machines to recognize the unfamiliar, learn from a single example, and thrive with minimal data.
Join us as we uncover the potential of zero-shot, one-shot, and few-shot learning to revolutionize how machines acquire knowledge, promising insights for beginners and seasoned practitioners alike. Welcome to the frontier of machine learning innovation!
Traditional Learning Approaches
Traditional machine learning predominantly relied on supervised learning, a process where models were trained using labeled datasets. In this approach, the algorithm learns patterns and relationships between input features and corresponding output labels. For instance, in image recognition, a model might be trained on thousands of labeled images to correctly identify objects like cats or dogs.
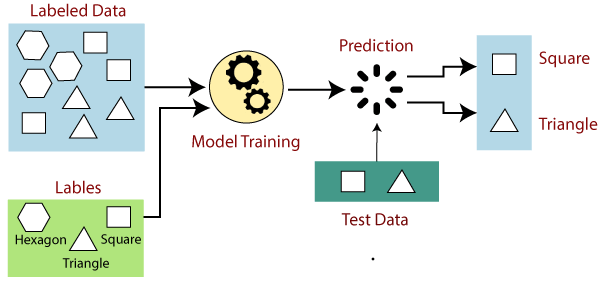
Source: Javatpoint
However, the Achilles’ heel of this method is its hunger for massive, labeled datasets. The model’s effectiveness is directly tied to the quantity and quality of data it encounters during training. Consider it as a student learning from textbooks; the more comprehensive and varied the textbooks, the better the student’s understanding.
Yet, this posed a limitation: what happens when faced with new, unencountered scenarios or when labeled data is scarce? This is where the narrative shifts to the frontier of zero-shot, one-shot, and few-shot learning, promising solutions to these very challenges.
A detailed guide on how to master prompt engineering
Zero-Shot Learning
Zero-shot learning is a revolutionary approach in machine learning where models are empowered to perform tasks for which they have had no specific training examples.
Unlike traditional methods that heavily rely on extensive labeled datasets, zero-shot learning enables models to generalize and make predictions in the absence of direct experience with a particular class or scenario.
In practical terms, zero-shot learning operates on the premise of understanding semantic relationships and attributes associated with classes during training. Instead of memorizing explicit examples, the model learns to recognize the inherent characteristics that define a class. These characteristics, often represented as semantic embeddings, serve as a bridge between known and unknown entities.
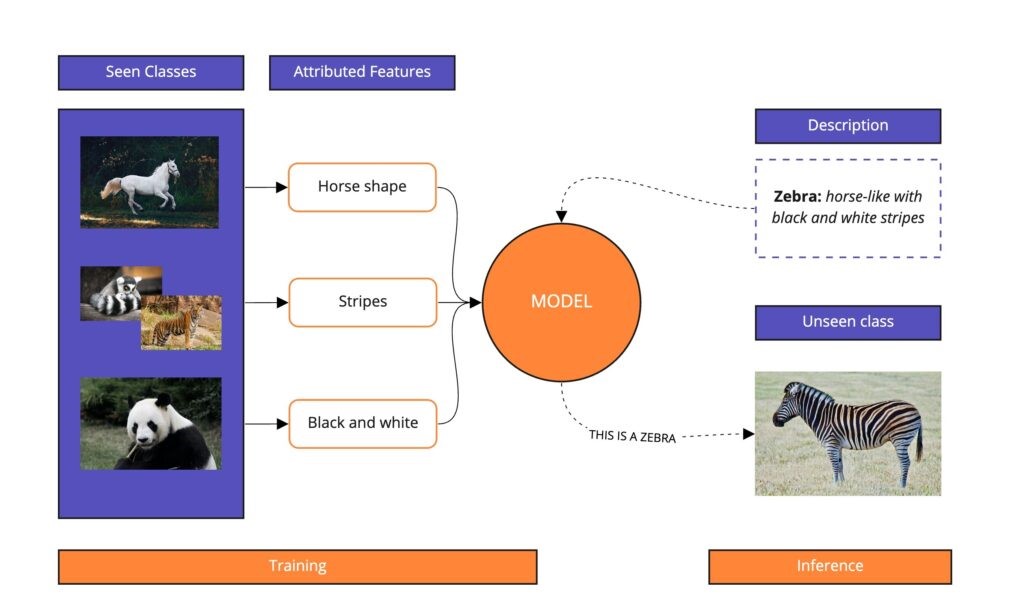
Source: Modulai.io
Imagine a model trained on various animals but deliberately excluding zebras. In a traditional setting, recognizing a zebra without direct training examples might pose a challenge. However, a zero-shot learning model excels in this scenario. During training, it grasps the semantic attributes of a zebra, such as the horse-like shape and tiger-like stripes.
When presented with an image of a zebra during testing, the model leverages its understanding of these inherent features. Even without explicit zebra examples, it confidently identifies the creature based on its acquired semantic knowledge.
This exemplifies how zero-shot learning transcends conventional limitations, showcasing the model’s ability to comprehend and generalize across classes without the need for exhaustive training datasets.
You might also like: Myths and Facts of Prompt Engineering
At its technical foundation, zero-shot learning draws inspiration from seminal research, as exemplified by “Zero-Shot Learning – A Comprehensive Evaluation of the Good, the Bad, and the Ugly” by Xian et al. (2017).
This comprehensive evaluation sheds light on the landscape of zero-shot learning methodologies, exploring the strengths and challenges across various approaches. The findings emphasize the importance of semantic embeddings and attribute-based learning in achieving robust zero-shot learning outcomes.

For instance, in natural language processing, a model trained in various languages might be tasked with translating a language it has never seen before. By understanding the semantic relationships between languages, the model can make informed translations even in the absence of explicit training data.
Zero-shot learning thus empowers models to extend their capabilities beyond the confines of predefined classes, marking a significant stride towards more flexible and adaptable artificial intelligence. This shift from rote memorization to semantic understanding sets the stage for a new era in machine learning innovation.
Give it a read too: Prompting techniques to use AI video generators
One-Shot Learning
One-shot learning represents a remarkable advancement in machine learning, allowing models to grasp new concepts and generalize from just a single example. In contrast to traditional approaches that demand extensive labeled datasets, one-shot learning opens the door to rapid adaptation and knowledge acquisition with minimal training instances.
In practical terms, one-shot learning acknowledges that learning from a single example requires a different strategy. Models designed for one-shot learning often employ techniques that focus on effective feature extraction and rapid adaptation. These approaches enable the model to generalize swiftly, making informed decisions even when faced with sparse data.
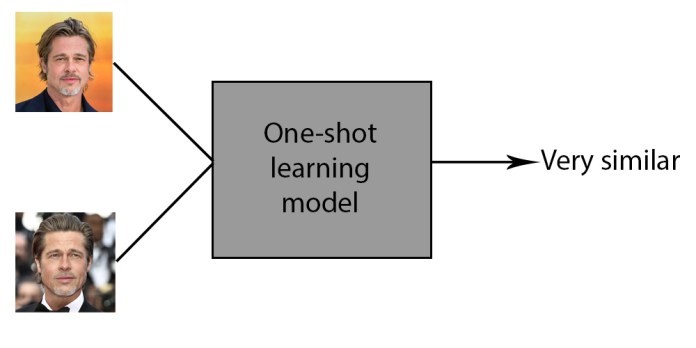
Source: bdtechtalks.com
Consider a scenario where a model is tasked with recognizing a person’s face after being trained with only a single image of that individual. Traditional models might struggle to generalize from such limited examples, requiring a multitude of images for robust recognition. However, a one-shot learning model takes a more efficient route.
During training, the one-shot learning model learns to extract crucial features from a single image, understanding distinctive facial characteristics and patterns.
When presented with a new image of the same person during testing, the model leverages its acquired knowledge to make accurate identifications. This ability to adapt and generalize from minimal data exemplifies the efficiency and agility that one-shot learning brings to the table.
In essence, one-shot learning propels machine learning into scenarios where data is scarce, showcasing the model’s capacity to learn quickly and effectively from a limited number of examples. This paradigm shift marks a crucial step towards more resource-efficient and adaptable artificial intelligence systems.

The technical genesis of one-shot learning finds roots in seminal research, prominently illustrated by the paper “Siamese Neural Networks for One-shot Image Recognition” by Koch, Zemel, and Salakhutdinov (2015).
This foundational work introduces Siamese networks, a class of neural architectures designed to learn robust embeddings for individual instances. The essence lies in imparting models with the ability to recognize similarities and differences between instances, enabling effective one-shot learning.
Few-Shot Learning
Few-shot learning represents a pragmatic compromise between traditional supervised learning and the extremes of zero-shot and one-shot learning. In this approach, models are trained with a small number of examples per class, offering a middle ground that addresses the challenges posed by both data scarcity and the need for robust generalization.
Another interesting read on dynamic few-shot prompting
In practical terms, few-shot learning recognizes that while a limited dataset may not suffice for traditional supervised learning, it still provides valuable insights. Techniques within few-shot learning often leverage data augmentation, transfer learning, and meta-learning to enhance the model’s ability to generalize from sparse examples.
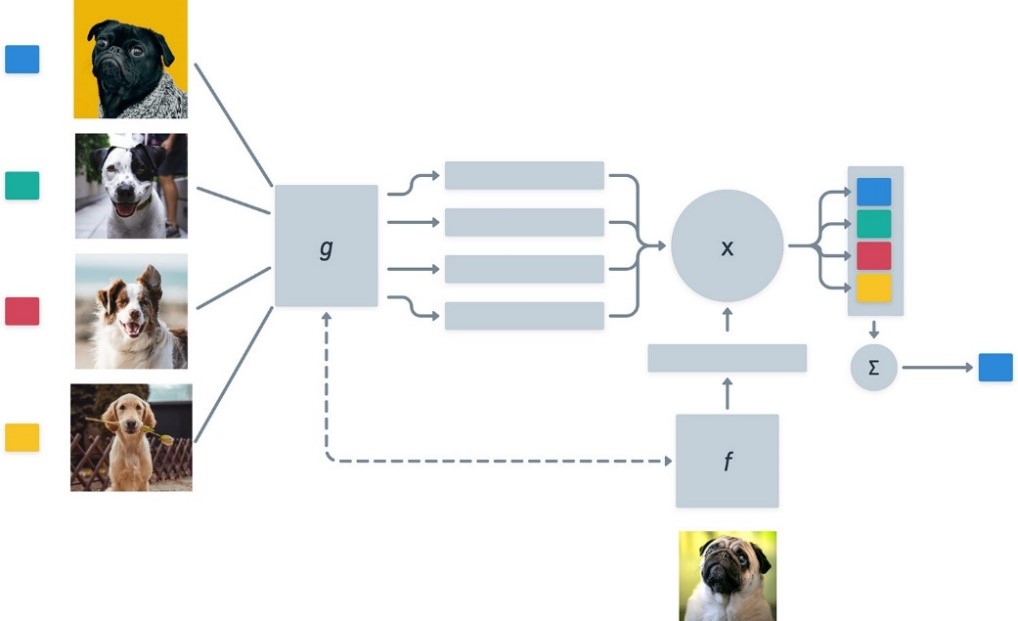
Let’s delve into a specific example in the context of image classification:
Imagine training a model to recognize dogs but with only a handful of examples for each digit. Traditional approaches might struggle with such limited data, leading to poor generalization. However, a few-shot learning model embraces the challenge.
Few-shot learning excels in recognizing dog images with minimal labeled data, utilizing just a few examples per breed. Employing techniques like data augmentation and transfer learning, the model generalizes effectively during testing, showcasing adaptability.
Also explore: Fine-tuning LLMs
By effectively utilizing small datasets and incorporating advanced strategies, few-shot learning proves to be valuable for recognizing diverse dog breeds, particularly in scenarios with limited, comprehensive datasets.
The conceptual underpinnings of few-shot learning draw from landmark research, notably exemplified in the paper “Matching Networks for One Shot Learning” by Vinyals et al. (2016).
This pioneering work introduces matching networks, leveraging attention mechanisms for meta-learning. The essence lies in endowing models with the ability to rapidly adapt to new tasks with minimal examples. The findings underscore the potential of few-shot learning in scenarios demanding swift adaptation to novel tasks.
