
The significance of creating and disseminating information has been immensely crucial. In contemporary times, data science elements have emerged as a substantial and progressively expanding domain that has an impact on virtually every sphere of human ingenuity: be it commerce, technology, healthcare, education, governance, and beyond.
The challenge and prospects arise as we endeavor to extract the value embedded in data in a meaningful manner to facilitate the decision-making process.
Data science takes on a comprehensive approach to the concept of scientific inquiry, albeit adhering to certain fundamental regulations and tenets. This piece will concentrate on the elemental constituents constituting data science. However, prior to delving into that, it is prudent to precisely comprehend the essence of data science.

Essential data science elements: A comprehensive overview
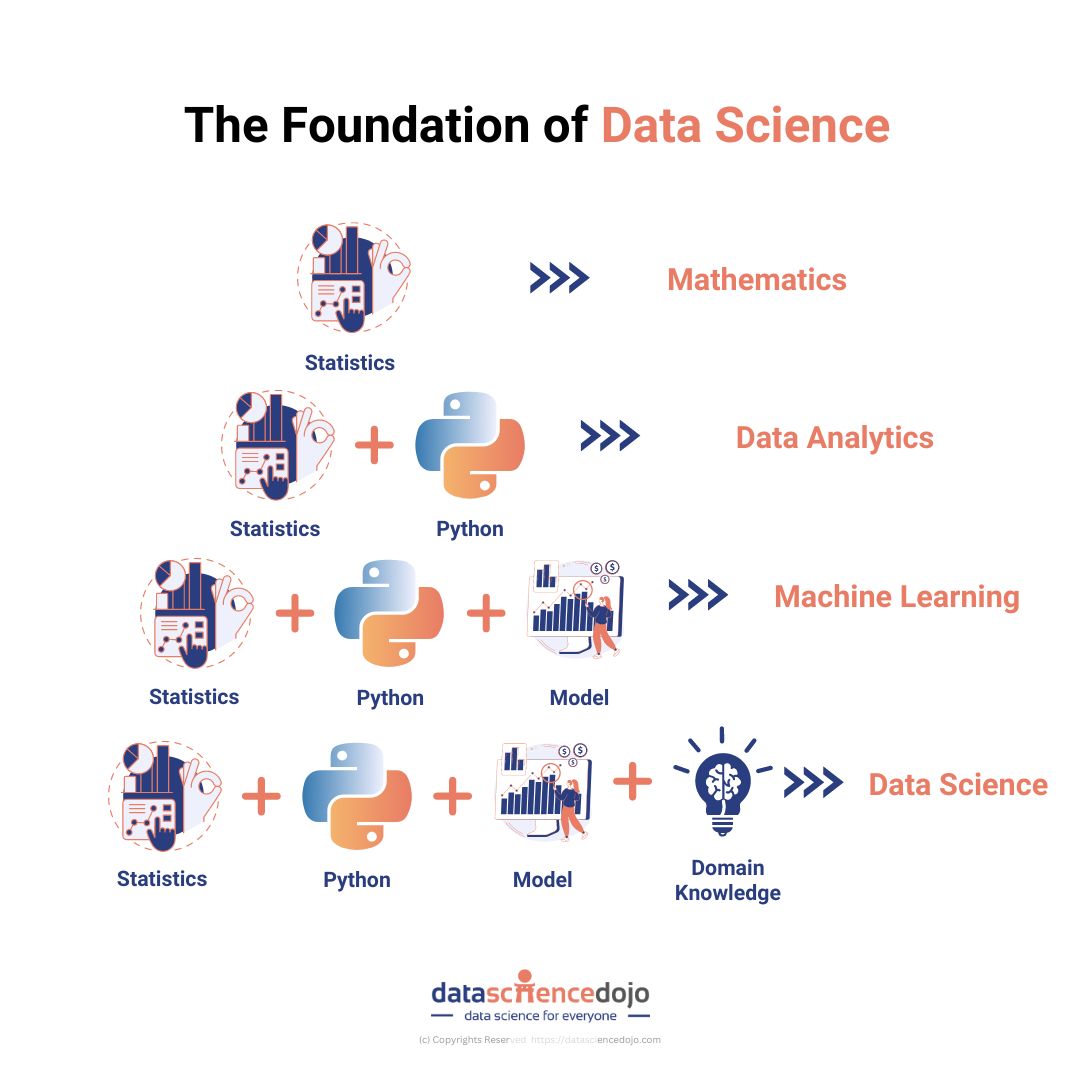
Data science has emerged as a critical field in today’s data-driven world, enabling organizations to glean valuable insights from vast amounts of data. At the heart of this discipline lie four key building blocks that form the foundation for effective data science: statistics, Python programming, models, and domain knowledge.
In this comprehensive overview, we will delve into each of these building blocks, exploring their significance and how they synergistically contribute to the field of data science.
1. Statistics: Unveiling the patterns within data
Statistics serves as the bedrock of data science, providing the tools and techniques to collect, analyze, and interpret data. It equips data scientists with the means to uncover patterns, trends, and relationships hidden within complex datasets. By applying statistical concepts such as central tendency, variability, and correlation, data scientists can gain insights into the underlying structure of data.
Moreover, statistical inference empowers them to make informed decisions and draw meaningful conclusions based on sample data.
There are many different statistical techniques that can be used in data science. Some of the most common techniques include:
- Descriptive statistics are used to summarize data. They can be used to describe the central tendency, spread, and shape of a data set.
- Inferential statistics are used to make inferences about a population based on a sample. They can be used to test hypotheses, estimate parameters, and make predictions.
- Machine learning is a field of computer science that uses statistical techniques to build models from data. These models can be used to predict future outcomes or to classify data into different categories.
The ability to understand the principles of probability, hypothesis testing, and confidence intervals enables data scientists to validate their findings and ascertain the reliability of their analyses. Statistical literacy is essential for discerning between random noise and meaningful signals in data, thereby guiding the formulation of effective strategies and solutions.
2. Python: Versatile data scientist’s toolkit
Python has emerged as a prominent programming language in the data science realm due to its versatility, readability, and an expansive ecosystem of libraries. Its simplicity makes it accessible to both beginners and experienced programmers, facilitating efficient data manipulation, analysis, and visualization.
Some of the most popular Python libraries for data science include:
- NumPy is a library for numerical computation. It provides a fast and efficient way to manipulate data arrays.
- SciPy is a library for scientific computing. It provides a wide range of mathematical functions and algorithms.
- Pandas is a library for data analysis. It provides a high-level interface for working with data frames.
- Matplotlib is a library for plotting data. It provides a wide range of visualization tools.
The flexibility of Python extends to its ability to integrate with other technologies, enabling data scientists to create end-to-end data pipelines that encompass data ingestion, preprocessing, modeling, and deployment. The language’s widespread adoption in the data science community fosters collaboration, knowledge sharing, and the development of best practices.
3. Models: Bridging data and predictive insights
Models, in the context of data science, are mathematical representations of real-world phenomena. They play a pivotal role in predictive analytics and machine learning, enabling data scientists to make informed forecasts and decisions based on historical data patterns.
By leveraging models, data scientists can extrapolate trends and behaviors, facilitating proactive decision-making.
Supervised machine learning algorithms, such as linear regression and decision trees, are fundamental models that underpin predictive modeling. These algorithms learn patterns from labeled training data and generalize those patterns to make predictions on unseen data. Unsupervised learning models, like clustering and dimensionality reduction, aid in uncovering hidden structures within data.
There are many different types of models that can be used in data science. Some of the most common types of models include:
- Linear regression models are used to predict a continuous outcome from a set of independent variables.
- Logistic regression models are used to predict a categorical outcome from a set of independent variables.
- Decision trees are used to classify data into different categories.
- Support vector machines are used to classify data and to predict continuous outcomes.
Models serve as an essential bridge between data and insights. By selecting, training, and fine-tuning models, data scientists can unlock the potential to automate decision-making processes, enhance business strategies, and optimize resource allocation.
4. Domain knowledge: Contextualizing data insights
While statistics, programming, and models provide the technical foundation for data science, domain knowledge adds a crucial contextual layer. Domain knowledge involves understanding the specific industry or field to which the data pertains. This contextual awareness aids data scientists in framing relevant questions, identifying meaningful variables, and interpreting results accurately.
Domain knowledge guides the selection of appropriate models and features, ensuring that data analyses align with the nuances of the subject matter. It enables data scientists to discern anomalies that might be of strategic importance, detect potential biases, and validate the practical relevance of findings.
Collaboration between data scientists and domain experts fosters a holistic approach to problem-solving. Data scientists contribute their analytical expertise, while domain experts offer insights that can refine data-driven strategies. This synergy enhances the quality and applicability of data science outcomes within the broader business or research context.
Conclusion: Synergy of four pillars
In the realm of data science, success hinges on the synergy of four essential building blocks: statistics, Python programming, models, and domain knowledge. Together, these pillars empower data scientists to collect, analyze, and interpret data, unlocking valuable insights and driving informed decision-making.
By harnessing statistical techniques, leveraging the versatility of Python, harnessing the power of models, and contextualizing findings within domain knowledge, data scientists can navigate the complexities of data-driven challenges and contribute meaningfully to their respective fields.
Written by Murk Sindhya Memon



