
Generative AI applications like ChatGPT and Gemini are becoming indispensable in today’s world. However, these powerful tools come with significant risks that need careful mitigation.
Among these challenges is the potential for models to generate biased responses based on their training data or to produce harmful content, such as instructions on making a bomb. Reinforcement Learning from Human Feedback (RLHF) has emerged as the industry’s leading technique to address these issues.
What is RLHF?
Explore top 5 LLM Leaderboard and their Impact on AI Development
1. Enhancing AI Performance
- Human-Centric Optimization: RLHF incorporates human feedback directly into the training process, allowing the model to perform tasks more aligned with human goals, wants, and needs. This ensures that the AI system is more accurate and relevant in its outputs.
- Improved Accuracy: By integrating human feedback loops, RLHF significantly enhances model performance beyond its initial state, making the AI more adept at producing natural and contextually appropriate responses.
2. Addressing Subjectivity and Nuance
- Complex Human Values: Human communication and preferences are subjective and context-dependent. Traditional methods struggle to capture qualities like creativity, helpfulness, and truthfulness. RLHF allows models to align better with these complex human values by leveraging direct human feedback.
- Subjectivity Handling: Since human feedback can capture nuances and subjective assessments that are challenging to define algorithmically, RLHF is particularly effective for tasks that require a deep understanding of context and user intent.
3. Applications in Generative AI
- Wide Range of Applications: RLHF is recognized as the industry standard technique for ensuring that large language models (LLMs) produce content that is truthful, harmless, and helpful. Applications include chatbots, image generation, music creation, and voice assistants.
- User Satisfaction: For example, in natural language processing applications like chatbots, RLHF helps generate responses that are more engaging and satisfying to users by sounding more natural and providing appropriate contextual information.
Understand Natural Language Processing and its applications
4. Mitigating Limitations of Traditional Metrics
- Beyond BLEU and ROUGE: Traditional metrics like BLEU and ROUGE focus on surface-level text similarities and often fail to capture the quality of text in terms of coherence, relevance, and readability. RLHF provides a more nuanced and effective way to evaluate and optimize model outputs based on human preferences.

The Process of Reinforcement Learning from Human Feedback
Fine-tuning a model with Reinforcement Learning from Human Feedback involves a multi-step process designed to align the model with human preferences.
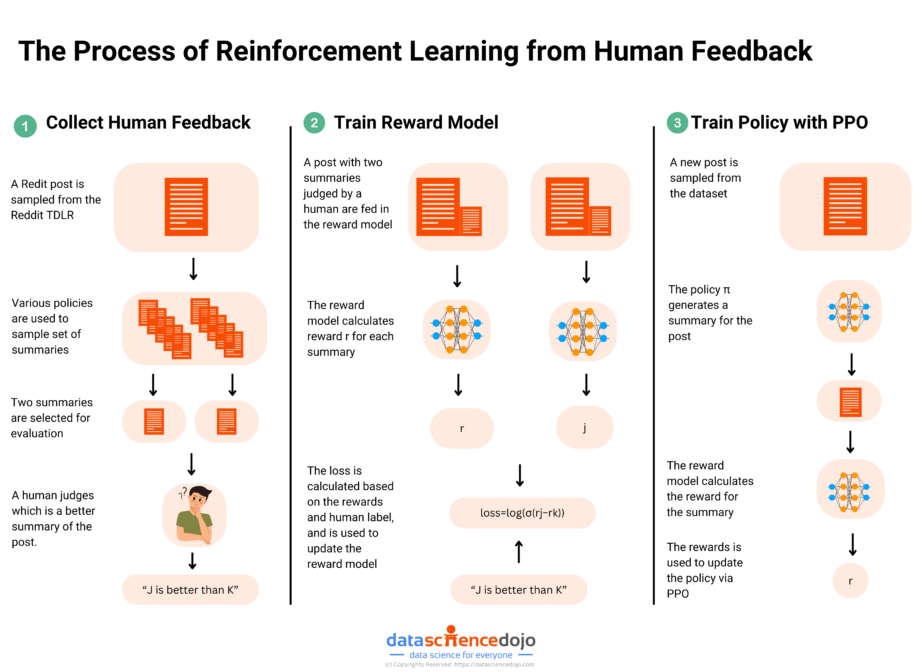
Step 1: Creating a Preference Dataset
A preference dataset is a collection of data that captures human preferences regarding the outputs generated by a language model. This dataset is fundamental in the Reinforcement Learning from Human Feedback process, where it aligns the model’s behavior with human expectations and values.
Here’s a detailed explanation of what a preference dataset is and why it is created:
What is a Preference Dataset?
A preference dataset consists of pairs or sets of prompts and the corresponding responses generated by a language model, along with human annotations that rank these responses based on their quality or preferability. Some of the major components of a preference dataset include:
1. Prompts
Prompts are the initial queries or tasks posed to the language model. They serve as the starting point for generating responses.
These prompts are sampled from a predefined dataset and are designed to cover a wide range of scenarios and topics to ensure comprehensive training of the language model.
Example:
A prompt could be a question like “What is the capital of France?” or a more complex instruction such as “Write a short story about a brave knight”.

2. Generated Text Outputs
These are the responses generated by the language model when given a prompt.
The text outputs are the subject of evaluation and ranking by human annotators. They form the basis on which preferences are applied and learned.
Example:
For the prompt “What is the capital of France?”, the generated text output might be “The capital of France is Paris”.
3. Human Annotations
Human annotations involve the evaluation and ranking of the generated text outputs by human annotators.
Master LLM Evaluation Metrics and their applications
Annotators compare different responses to the same prompt and rank them based on their quality or preferability. This helps in creating a more regularized and reliable dataset as opposed to direct scalar scoring, which can be noisy and uncalibrated.
Example:
Given two responses to the prompt “What is the capital of France?”, one saying “Paris” and another saying “Lyon,” annotators would rank “Paris” higher.
4. Preparing the Dataset:
Objective: Format the collected feedback for training the reward model.
Process:
- Organize the feedback into a structured format, typically as pairs of outputs with corresponding preference labels.
- This dataset will be used to teach the reward model to predict which outputs are more aligned with human preferences.

Step 2 – Training the Reward Model
Training the reward model is a pivotal step in the RLHF process, transforming human feedback into a quantitative signal that guides the learning of an AI system.
Below, we dive deeper into the key steps involved, including an introduction to model architecture selection, the training process, and validation and testing.
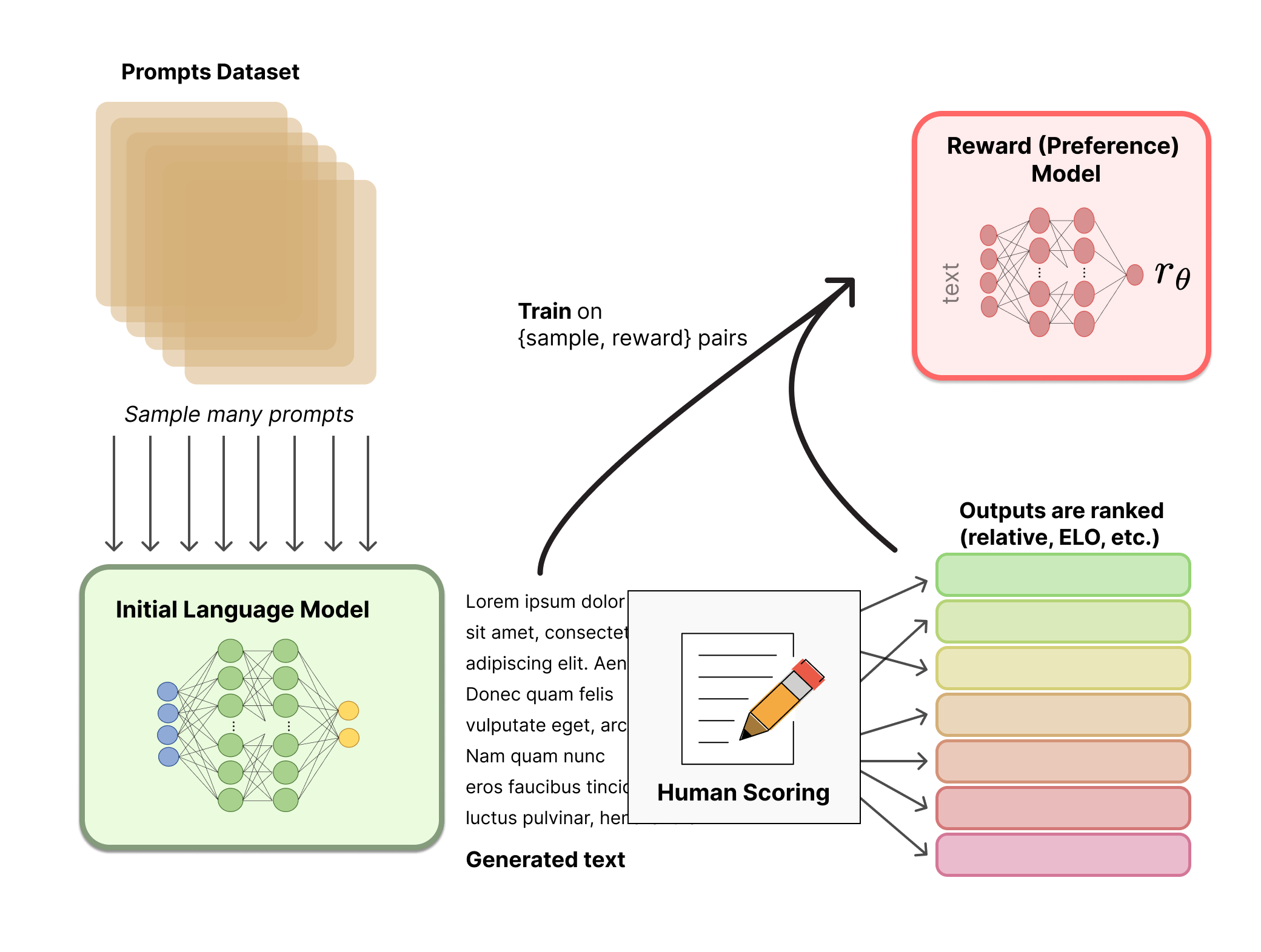
1. Model Architecture Selection
Objective: Choose an appropriate neural network architecture for the reward model.
Process:
- Select a Neural Network Architecture: The architecture should be capable of effectively learning from the feedback dataset, capturing the nuances of human preferences.
- Feedforward Neural Networks: Simple and straightforward, these networks are suitable for basic tasks where the relationships in the data are not highly complex.
- Transformers: These architectures, which power models like GPT-3, are particularly effective for handling sequential data and capturing long-range dependencies, making them ideal for language-related tasks.
- Considerations: The choice of architecture depends on the complexity of the data, the computational resources available, and the specific requirements of the task. Transformers are often preferred for language models due to their superior performance in understanding context and generating coherent outputs.
2. Training the Reward Model
Objective: Train the reward model to predict human preferences accurately.
Process:
- Input Preparation:
- Pairs of Outputs: Use pairs of outputs generated by the language model, along with the preference labels provided by human evaluators.
- Feature Representation: Convert these pairs into a suitable format that the neural network can process.
- Supervised Learning:
- Loss Function: Define a loss function that measures the difference between the predicted rewards and the actual human preferences. Common choices include mean squared error or cross-entropy loss, depending on the nature of the prediction task.
- Optimization: Use optimization algorithms like stochastic gradient descent (SGD) or Adam to minimize the loss function. This involves adjusting the model’s parameters to improve its predictions.
- Training Loop:
- Forward Pass: Input the data into the neural network and compute the predicted rewards.
- Backward Pass: Calculate the gradients of the loss function with respect to the model’s parameters and update the parameters accordingly.
- Iteration: Repeat the forward and backward passes over multiple epochs until the model’s performance stabilizes.
- Evaluation during Training: Monitor metrics such as training loss and accuracy to ensure the model is learning effectively and not overfitting the training data.
3. Validation and Testing
Objective: Ensure the reward model accurately predicts human preferences and generalizes well to new data.
Process:
- Validation Set:
- Separate Dataset: Use a separate validation set that was not used during training to evaluate the model’s performance.
- Performance Metrics: Assess the model using metrics like accuracy, precision, recall, F1 score, and AUC-ROC to understand how well it predicts human preferences.
- Testing:
- Test Set: After validation, test the model on an unseen dataset to evaluate its generalization ability.
- Real-world Scenarios: Simulate real-world scenarios to further validate the model’s predictions in practical applications.
- Model Adjustment:
- Hyperparameter Tuning: Adjust hyperparameters such as learning rate, batch size, and network architecture to improve performance.
- Regularization: Apply techniques like dropout, weight decay, or data augmentation to prevent overfitting and enhance generalization.
- Iterative Refinement:
- Feedback Loop: Continuously refine the reward model by incorporating new human feedback and retraining the model.
- Model Updates: Periodically update the reward model and re-evaluate its performance to maintain alignment with evolving human preferences.
By iteratively refining the reward model, AI systems can be better aligned with human values, leading to more desirable and acceptable outcomes in various applications.
Step 3 – Fine-Tuning with Reinforcement Learning
Fine-tuning with RL is a sophisticated method used to enhance the performance of a pre-trained language model.
This method leverages human feedback and reinforcement learning techniques to optimize the model’s responses, making them more suitable for specific tasks or user interactions. The primary goal is to refine the model’s behavior to meet desired criteria, such as helpfulness, truthfulness, or creativity.
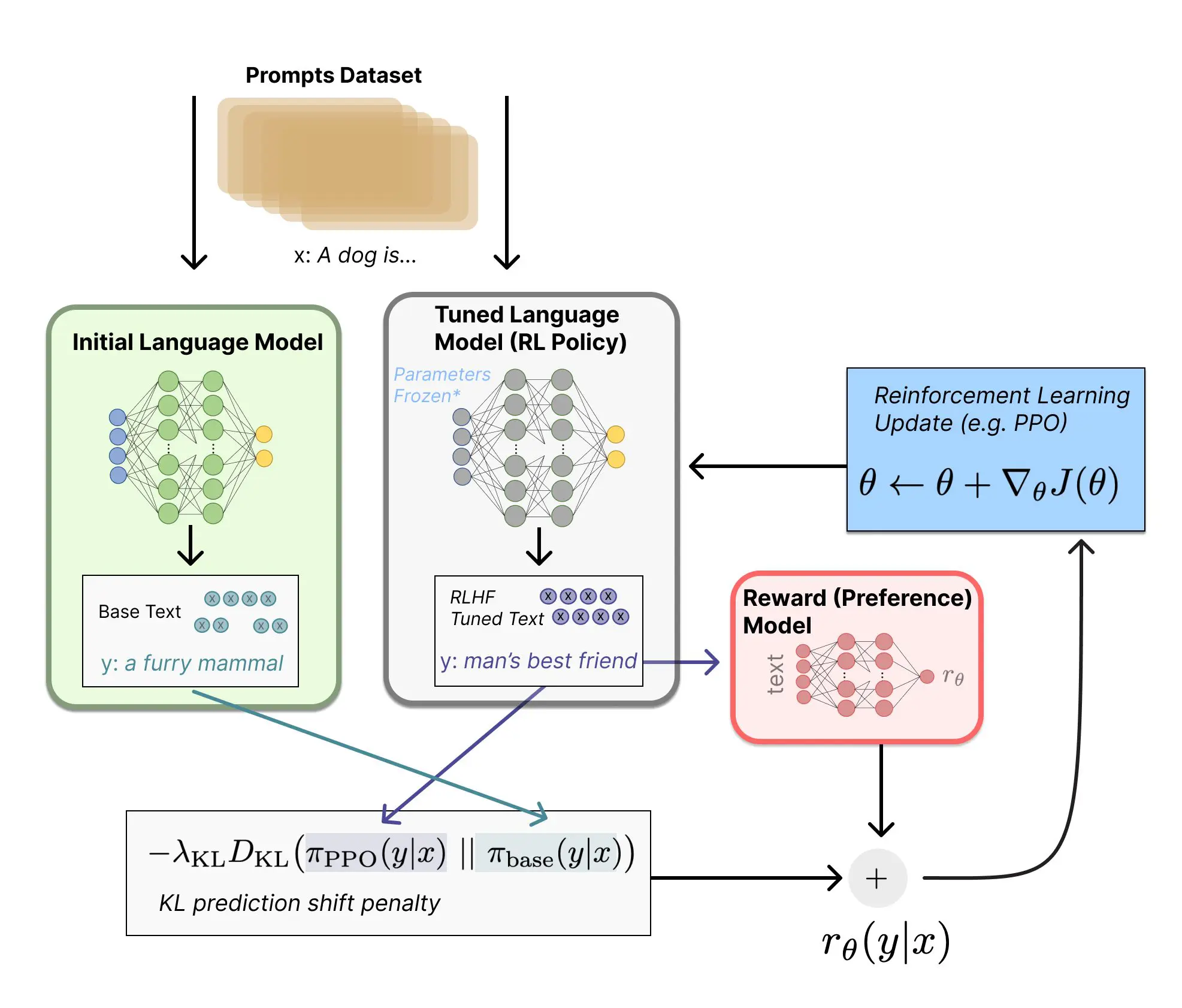
Process of Fine-Tuning with Reinforcement Learning
Reinforcement Learning Fine-Tuning:
- Policy Gradient Algorithm: Use a policy-gradient RL algorithm, such as Proximal Policy Optimization (PPO), to fine-tune the language model. PPO is favored for its relative simplicity and effectiveness in handling large-scale models.
- Policy Update: The language model’s parameters are adjusted to maximize the reward function, which combines the preference model’s output and a constraint on policy shift to prevent drastic changes. This ensures the model improves while maintaining coherence and stability.
- Constraint on Policy Shift: Implement a penalty term, typically the Kullback–Leibler (KL) divergence, to ensure the updated policy does not deviate too far from the pre-trained model. This helps maintain the model’s original strengths while refining its outputs.
Validation and Iteration:
- Performance Evaluation: Evaluate the fine-tuned model using a separate validation set to ensure it generalizes well and meets the desired criteria. Metrics like accuracy, precision, and recall are used for assessment.
Learn about LLM Benchmarks for Comprehensive Model Evaluation
- Iterative Updates: Continue iterating the process, using updated human feedback to refine the reward model and further fine-tune the language model. This iterative approach helps in continuously improving the model’s performance
Applications of RLHF
Reinforcement Learning from Human Feedback (RLHF) is essential for aligning AI systems with human values and enhancing their performance in various applications, including chatbots, image generation, music generation, and voice assistants.
1. Improving Chatbot Interactions
RLHF significantly improves chatbot tasks like summarization and question-answering. For summarization, human feedback on the quality of summaries helps train a reward model that guides the chatbot to produce more accurate and coherent outputs.
In question-answering, feedback on the relevance and correctness of responses trains a reward model, leading to more precise and satisfactory interactions. Overall, RLHF enhances user satisfaction and trust in chatbots.
2. AI Image Generation
In AI image generation, RLHF enhances the quality and artistic value of generated images. Human feedback on visual appeal and relevance trains a reward model that predicts the desirability of new images.
Fine-tuning the image generation model with reinforcement learning leads to more visually appealing and contextually appropriate images, benefiting digital art, marketing, and design.
3. Music Generation
RLHF improves the creativity and appeal of AI-generated music. Human feedback on harmony, melody, and enjoyment trains a reward model that predicts the quality of musical pieces.
The music generation model is fine-tuned to produce compositions that resonate more closely with human tastes, enhancing applications in entertainment, therapy, and personalized music experiences.
4. Voice Assistants
Voice assistants benefit from RLHF by improving the naturalness and usefulness of their interactions. Human feedback on response quality and interaction tone trains a reward model that predicts user satisfaction.
Fine-tuning the voice assistant ensures more accurate, contextually appropriate, and engaging responses, enhancing user experience in home automation, customer service, and accessibility support.
In Summary
RLHF is a powerful technique that enhances AI performance and user alignment across various applications. By leveraging human feedback to train reward models and using reinforcement learning for fine-tuning, RLHF ensures that AI-generated content is more accurate, relevant, and satisfying.
This leads to more effective and enjoyable AI interactions in chatbots, image generation, music creation, and voice assistants.