

In the vast forest of machine learning algorithms, one algorithm stands tall like a sturdy tree – Random Forest. It’s an ensemble learning method that’s both powerful and flexible, widely used for classification and regression tasks.
But what makes the random forest algorithm so effective? How does it work?
In this blog, we’ll explore the inner workings of Random Forest, its advantages, limitations, and practical applications.
What is a Random Forest Algorithm?
Imagine a dense forest with numerous trees, each offering a different path to follow. Random Forest Algorithm is like that: an ensemble of decision trees working together to make more accurate predictions.
By combining the results of multiple trees, the algorithm improves the overall model performance, reducing errors and variance.

Why the Name ‘Random Forest’?
The name “Random Forest” comes from the combination of two key concepts: randomness and forests. The “random” part refers to the random selection of data samples and features during the construction of each tree, while the “forest” part refers to the ensemble of decision trees.
This randomness is what makes the algorithm robust and less prone to overfitting.
Common Use Cases of Random Forest Algorithm
Random Forest Algorithm is highly versatile and is used in various applications such as:
- Classification: Spam detection, disease prediction, customer segmentation.
- Regression: Predicting stock prices, house values, and customer lifetime value.
Also learn about Linear vs Logistic regression
Understanding the Basics
Before diving into Random Forest, let’s quickly revisit the concept of Decision Trees.
Decision Trees Recap
A decision tree is a flowchart-like structure where internal nodes represent decisions based on features, branches represent the outcomes of these decisions, and leaf nodes represent final predictions. While decision trees are easy to understand and interpret, they can be prone to overfitting, especially when the tree is deep and complex.
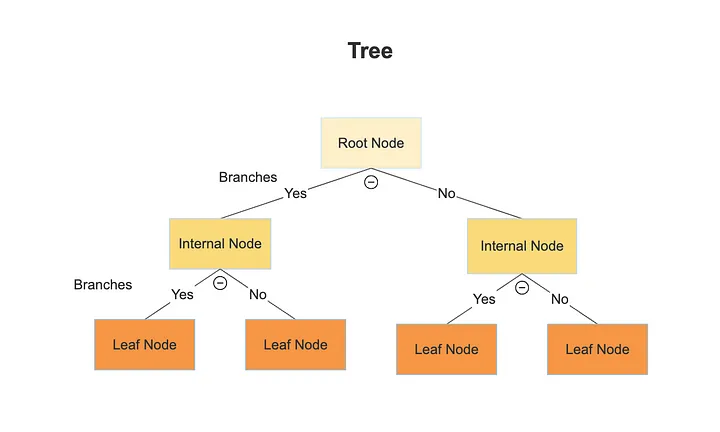
Key Concepts in Random Forest
- Ensemble Learning: This technique combines multiple models to improve performance. Random Forest is an example of ensemble learning where multiple decision trees work together to produce a more accurate and stable prediction.
Read in detail about ensemble methods in machine learning
- Bagging (Bootstrap Aggregating): In Random Forest, the algorithm creates multiple subsets of the original dataset by sampling with replacement (bootstrapping). Each tree is trained on a different subset, which helps in reducing variance and preventing overfitting.
- Feature Randomness: During the construction of each tree, Random Forest randomly selects a subset of features to consider at each split. This ensures that the trees are diverse and reduces the likelihood that a few strong predictors dominate the model.
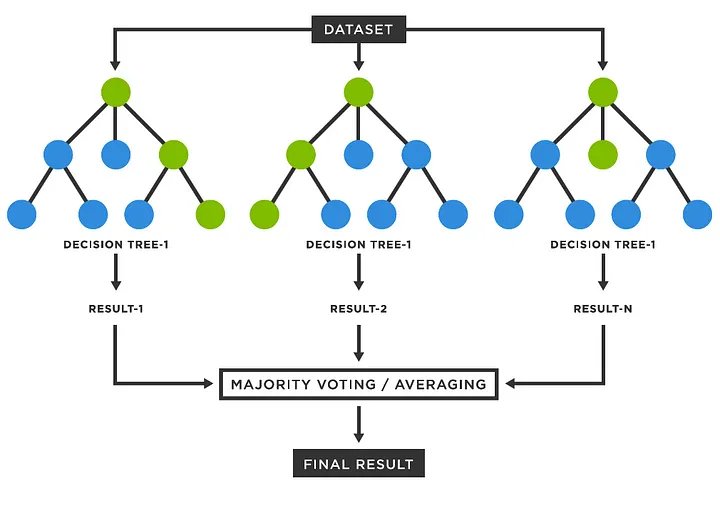
How Does Random Forest Work?
Let’s break down the process into two main phases: training and prediction.
Training Phase
- Creating Bootstrapped Datasets: The algorithm starts by creating multiple bootstrapped datasets by randomly sampling the original data with replacement. This means some data points may be repeated, while others may be left out.
- Building Multiple Decision Trees: For each bootstrapped dataset, a decision tree is constructed. However, instead of considering all features at each split, the algorithm randomly selects a subset of features. This randomness ensures that the trees are different from each other, leading to a more generalized model.
Prediction Phase
- Voting in Classification: When it’s time to make predictions, each tree in the forest casts a vote for the class label. The final prediction is determined by the majority vote among the trees.
- Averaging in Regression: For regression tasks, instead of voting, the predictions from all the trees are averaged to get the result.
Another interesting read: Sustainability Data and Machine Learning
Advantages of Random Forest
Random Forest is popular for good reasons. Some of these include:
High Accuracy
By aggregating the predictions of multiple trees, Random Forest often achieves higher accuracy than individual decision trees. The ensemble approach reduces the impact of noisy data and avoids overfitting, making the model more reliable.
Robustness to Overfitting
Overfitting occurs when a model performs well on the training data but poorly on unseen data. Random Forest combats overfitting by averaging the predictions of multiple trees, each trained on different parts of the data. This ensemble approach helps the model generalize better.
Handles Missing Data
Random Forest can handle missing values naturally by using the split with the majority of the data and by averaging the outputs from trees trained on different parts of the data.
Feature Importance
One of the perks of Random Forest is its ability to measure the importance of each feature in making predictions. This is done by evaluating the impact of each feature on the model’s performance, providing insights into which features are most influential.

Limitations of Random Forest
While Random Forest is a powerful tool, it’s not without its drawbacks. A few limitations associated with random forests are:
Computational Cost
Training multiple decision trees can be computationally expensive, especially with large datasets and a high number of trees. The algorithm’s complexity increases with the number of trees and the depth of each tree, leading to longer training times.
Interpretability
While decision trees are easy to interpret, Random Forest, being an ensemble of many trees, is more complex and harder to interpret. The lack of transparency can be a disadvantage in situations where model interpretability is crucial.
Bias-Variance Trade-off
Random Forest does a good job managing the bias-variance trade-off, but it’s not immune to it. If not carefully tuned, the model can still suffer from bias or variance issues, though typically less so than a single decision tree.
Hyperparameter Tuning in Random Forest
While we understand the benefits and limitations of Random Forest, let’s take a deeper look into working with the algorithm. Understanding and working with relevant hyperparameters is a crucial part of the process.
It is an important aspect because tuning the hyperparameters of a Random Forest can significantly impact its performance. Here are some key hyperparameters to consider:
Master hyperparameter tuning for machine learning models
Key Hyperparameters
- Number of Trees (n_estimators): The number of trees in the forest. Increasing this generally improves performance but with diminishing returns and increased computational cost.
- Maximum Depth (max_depth): The maximum depth of each tree. Limiting the depth can help prevent overfitting.
- Number of Features (max_features): The number of features to consider when looking for the best split. Lower values increase diversity among trees but can also lead to underfitting.
Techniques for Tuning
- Grid Search: This exhaustive search technique tries every combination of hyperparameters within a specified range to find the best combination. While thorough, it can be time-consuming.
- Random Search: Instead of trying every combination, Random Search randomly selects combinations of hyperparameters. It’s faster than Grid Search and often finds good results with less computational effort.
- Cross-Validation: Cross-validation is essential in hyperparameter tuning. It splits the data into several subsets and uses different combinations for training and validation, ensuring that the model’s performance is not dependent on a specific subset of data.
Practical Implementation
To understand how Random Forest works in practice, let’s look at a step-by-step implementation using Python.
Setting Up the Environment
You’ll need the following Python libraries: scikit-learn for the Random Forest implementation, pandas for data handling, and numpy for numerical operations.
Example Dataset
For this example, we’ll use the famous Iris dataset, a simple yet effective dataset for demonstrating classification algorithms.
Step-by-Step Code Walkthrough
- Data Preprocessing: Start by loading the data and handling any missing values, though the Iris dataset is clean and ready to use.
- Training the Random Forest Model: Instantiate the Random Forest classifier and fit it to the training data.
- Evaluating the Model: Use the test data to evaluate the model’s performance.
- Hyperparameter Tuning: Use Grid Search or Random Search to find the optimal hyperparameters.
Comparing Random Forest with Other Algorithms
Random Forest vs. Decision Trees
While a single decision tree is easy to interpret, it’s prone to overfitting, especially with complex data. Random Forest reduces overfitting by averaging the predictions of multiple trees, leading to better generalization.
Explore the boosting algorithms used to enhance ML model accuracy
Random Forest vs. Gradient Boosting
Both are ensemble methods, but they differ in approach. Random Forest builds trees independently, while Gradient Boosting builds trees sequentially, where each tree corrects the errors of the previous one. Gradient Boosting often achieves better accuracy but at the cost of higher computational complexity and longer training times.
Random Forest vs. Support Vector Machines (SVM)
SVMs are powerful for high-dimensional data, especially when the number of features exceeds the number of samples. However, SVMs are less interpretable and more sensitive to parameter tuning compared to Random Forest. Random Forest tends to be more robust and easier to use out of the box.

Explore the Impact of Random Forest Algorithm
Random Forest is a powerful and versatile algorithm, capable of handling complex datasets with high accuracy. Its ensemble nature makes it robust against overfitting and capable of providing valuable insights into feature importance.
As you venture into the world of machine learning, remember that a well-tuned Random Forest can be the key to unlocking insights hidden deep within your data. Keep experimenting, stay curious, and let your models grow as robust as the forest itself!