

In this blog, we are enhancing our Large Language Model (LLM) experience by adopting the Retrieval-Augmented Generation (RAG) approach! Let’s explore RAG in LLM for enhanced results!
We’ll explore the fundamental architecture of RAG conceptually and delve deeper by implementing it through the LangChain orchestration framework and leveraging an open-source model from Hugging Face for both question-answering and text embedding.
So, let’s get started!
Common Hallucinations in Large Language Models
The most common problem faced by state-of-the-art LLMs is that they produce inaccurate or hallucinated responses. This mostly occurs when prompted with information not present in their training set, despite being trained on extensive data.

This discrepancy between the general knowledge embedded in the LLM’s weights and newer information can be bridged using RAG. The solution provided by RAG eliminates the need for computationally intensive and expertise-dependent fine-tuning, offering a more flexible approach to adapting to evolving information.
Read more about: AI hallucinations and risks associated with large language models
What is RAG?
Retrieval Augmented Generation involves enhancing the output of Large Language Models (LLMs) by providing them with additional information from an external knowledge source.
Explore LLM context augmentation techniques like RAG and fine-tuning in detail with out podcast now!
This method aims to improve the accuracy and contextuality of LLM-generated responses while minimizing factual inaccuracies. RAG empowers language models to sidestep the need for retraining, facilitating access to the most up-to-date information to produce trustworthy outputs through retrieval-based generation.
The Architecture of RAG Approach
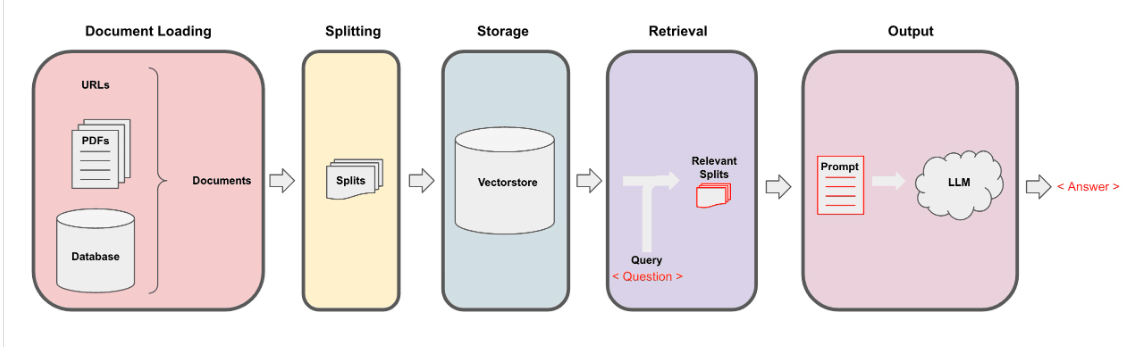
Figure from Lang chain documentation
Prerequisites for Code Implementation
1. HuggingFace Account and LLAMA2 Model Access:
- Create a Hugging Face account (free sign-up available) to access open-source Llama 2 and embedding models.
- Request access to LLAMA2 models using this form (access is typically granted within a few hours).
- After gaining access to Llama 2 models, please proceed to the provided link, select the checkbox to indicate your agreement to the information, and then click ‘Submit’.
2. Google Colab Account:
- Create a Google account if you don’t already have one.
- Use Google Colab for code execution.
3. Google Colab Environment Setup:
- In Google Colab, go to Runtime > Change runtime type > Hardware accelerator > GPU > GPU type > T4 for faster execution of code.
4. Library and Dependency Installation:
- Install necessary libraries and dependencies using the following command:
5. Authentication with HuggingFace:
- Integrate your Hugging Face token into Colab’s environment:
- When prompted, enter your Hugging Face token obtained from the “Access Token” tab in your Hugging Face settings.
A 5-Step Guide to Implement RAG in LLM
Step 1: Document Loading
Loading a document refers to the process of retrieving and storing data as documents in memory from a specified source. This process is typically facilitated by document loaders, which provide a “load” method for accessing and loading documents into the memory.
Another interesting read: RAG in LLM
Lang chain has a number of document loaders in this example we will be using the “WebBaseLoader” class from the “langchain.document_loaders” module to load content from a specific web page.
The code extracts content from the web page “https://lilianweng.github.io/posts/2023-06-23-agent/“. BeautifulSoup (`bs4`) is employed for HTML parsing, focusing on elements with the classes “post-content”, “post-title”, and “post-header.” The loaded content is stored in the variable `docs`.
Step 2: Document Transformation – Splitting/Chunking Document
After loading the data, it can be transformed to fit the application’s requirements or to extract relevant portions. This involves splitting lengthy documents into smaller chunks that are compatible with the model and produce accurate and clear results.
LangChain offers various text splitters, in this implementation we chose the “RecursiveCharacterTextSplitter” for generic text processing.
The code breaks documents into chunks of 1000 characters with a 200-character overlap. This chunking is employed for embedding and vector storage, enabling more focused retrieval of relevant content during runtime.
The recursive splitter ensures chunks maintain contextual integrity by using common separators, like new lines until the desired chunk size is achieved.
Step 3: Storage in Vector Database
After extracting text chunks, we store and index them for future searches using the RAG application. A common approach involves embedding the content of each split and storing these embeddings in a vector store.
When searching, we embed the search query and perform a similarity search to identify stored splits with embeddings most similar to the query embedding. Cosine similarity, which measures the angle between embeddings, is a simple similarity measure.
You might also like: RAG LLM or Fine-tuning
Using the Chroma vector store and open source “HuggingFaceEmbeddings” in the Langchain, we can embed and store all document splits in a single command.
Text Embedding:
Text embedding converts textual data into numerical vectors that capture the semantic meaning of the text. This enables efficient identification of similar text pieces. An embedding model is a variant of Language Models (LLMs) specifically designed for this purpose.
LangChain’s Embeddings class facilitates interaction with various text embedding models. While any model can be used, we opted for “HuggingFaceEmbeddings”.
This code initializes an instance of the HuggingFaceEmbeddings class, configuring it with an open-source pre-trained model located at “sentence-transformers/all-MiniLM-l6-v2“. By doing this text embedding is created for converting textual data into numerical vectors.

Vector Stores:
Vector stores are specialized databases designed to efficiently store and search for high-dimensional vectors, such as text embeddings. They enable the retrieval of the most similar embedding vectors based on a given query vector. LangChain integrates with various vector stores, and we are using the “Chroma” vector store for this task.
This code utilizes the Chroma class to create a vector store (vectorstore) from the previously split documents (splits) using the specified embeddings (embeddings). The Chroma vector store facilitates efficient storage and retrieval of document vectors for further processing.
Step 4: Retrieval of Text Chunks
After storing the data, preparing the LLM model, and constructing the pipeline, we need to retrieve the data. Retrievers serve as interfaces that return documents based on a query.
Retrievers cannot store documents; they can only retrieve them. Vector stores form the foundation of retrievers. LangChain offers a variety of retriever algorithms, here is the one we implement.
Step 5: Generation of Answer with RAG Approach
Preparing the LLM Model:
In the context of Retrieval Augmented Generation (RAG), an LLM model plays a crucial role in generating comprehensive and informative responses to user queries. By leveraging its ability to process and understand natural language, the LLM model can effectively combine retrieved documents with the given query to produce insightful and relevant outputs.
These lines import the necessary libraries for handling pre-trained models and tokenization. The specific model “meta-llama/Llama-2-7b-chat-hf” is chosen for its question-answering capabilities.
This code defines a transformer pipeline, which encapsulates the pre-trained HuggingFace model and its associated configuration. It specifies the task as “text-generation” and sets various parameters to optimize the pipeline’s performance.
This line creates a Lang Chain pipeline (HuggingFace Pipeline) that wraps the transformer pipeline. The model_kwargs parameter adjusts the model’s “temperature” to control its creativity and randomness.
Retrieval QA Chain:
To combine question-answering with a retrieval step, we employ the RetrievalQA chain, which utilizes a language model and a vector database as a retriever. By default, we process all data in a single batch and set the chain type to “stuff” when interacting with the language model.
This code initializes a RetrievalQA instance by specifying a chain type (“stuff”), a HuggingFacePipeline (llm), and a retriever (retriever-initialize previously in the code from vectorstore). The return_source_documents parameter is set to True to include source documents in the output, enhancing contextual information retrieval.
Finally, we call this QA chain with the specific question we want to ask.
The result will be:
We can print source documents to see which document chunks the model used to generate the answer to this specific query.
In this output, only 2 out of 4 document contents are shown as an example, that were retrieved to answer the specific question.
Conclusion
In conclusion, by embracing the Retrieval-Augmented Generation (RAG) approach, we have elevated our Language Model (LLM) experience to new heights.
Through a deep dive into the conceptual foundations of RAG and practical implementation using the Lang Chain orchestration framework, coupled with the power of an open-source model from Hugging Face, we have enhanced the question-answering capabilities of LLMs.

This journey exemplifies the seamless integration of innovative technologies to optimize LLM capabilities, paving the way for a more efficient and powerful language processing experience. Cheers to the exciting possibilities that arise from combining innovative approaches with open-source resources!