
Graphs play a very important role in the data science workflow. Learn how to create dynamic professional-looking plots with Plotly.py.
We use plots to understand the distribution and nature of variables in the data and use visualizations to describe our findings in reports or presentations to both colleagues and clients. The importance of plotting in a data scientist’s work cannot be overstated.
Learn more about visualizing your data at Data Science Dojo’s Introduction to Python for Data Science!
Plotting with Matplotlib
If you have worked on any kind of data analysis problem in Python you will probably have encountered matplotlib, the default (sort of) plotting library. I personally have a love-hate relationship with it — the simplest plots require quite a bit of extra code but the library does offer flexibility once you get used to its quirks. The library is also used by pandas for its built-in plotting feature. So even if you haven’t heard of matplotlib, if you’ve used df.plot(), then you’ve unknowingly used matplotlib.
Plotting with Seaborn
Another popular library is seaborn, which is essentially a high-level wrapper around matplotlib and provides functions for some custom visualizations, these require quite a bit of code to create in the standard matplotlib. Another nice feature seaborn provides is sensible defaults for most options like axis labels, color schemes, and sizes of shapes.
Introducing Plotly
Plotly might sound like the new kid on the block, but in reality, it’s nothing like that. Plotly originally provided functionality in the form of a JavaScript library built on top of D3.js and later branched out into frontends for other languages like R, MATLAB and, of course, Python. plotly.py is the Python interface to the library.
As for usability, in my experience Plotly falls in between matplotlib and seaborn. It provides a lot of the same high-level plots as seaborn but also has extra options right there for you to tweak, such as matplotlib. It also has generally much better defaults than matplotlib.
Plotly’s interactivity
The most fascinating feature of Plotly is the interactivity. Plotly is fundamentally different from both matplotlib and seaborn because plots are rendered as static images by both of them while Plotly uses the full power of JavaScript to provide interactive controls like zooming in and panning out of the visual panel. This functionality can also be extended to create powerful dashboards and responsive visualizations that could convey so much more information than a static picture ever could.
First, let’s see how the three libraries differ in their output and complexity of code. I’ll use common statistical plots as examples.
To have a relatively even playing field, I’ll use the built-in seaborn theme that matplotlib comes with so that we don’t have to deduct points because of the plot’s looks.
fig, ax = plt.subplots(figsize=(8,6))
for species, species_df in iris.groupby('species'):
ax.scatter(species_df['sepal_length'], species_df['sepal_width'], label=species);
ax.set(xlabel='Sepal Length', ylabel='Sepal Width', title='A Wild Scatterplot appears');
ax.legend();fig, ax = plt.subplots(figsize=(8,6))
sns.scatterplot(data=iris, x='sepal_length', y='sepal_width', hue='species', ax=ax);
ax.set(xlabel='Sepal Length', ylabel='Sepal Width', title='A Wild Scatterplot appears');
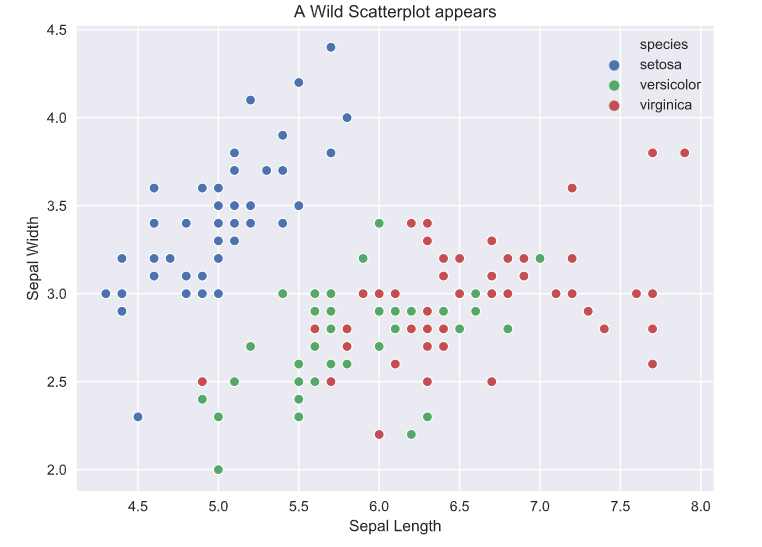
fig = go.FigureWidget()
for species, species_df in iris.groupby('species'):
fig.add_scatter(x=species_df['sepal_length'], y=species_df['sepal_width'],
mode='markers', name=species);
fig.layout.hovermode = 'closest'
fig.layout.xaxis.title = 'Sepal Length'
fig.layout.yaxis.title = 'Sepal Width'
fig.layout.title = 'A Wild Scatterplot appears'
fig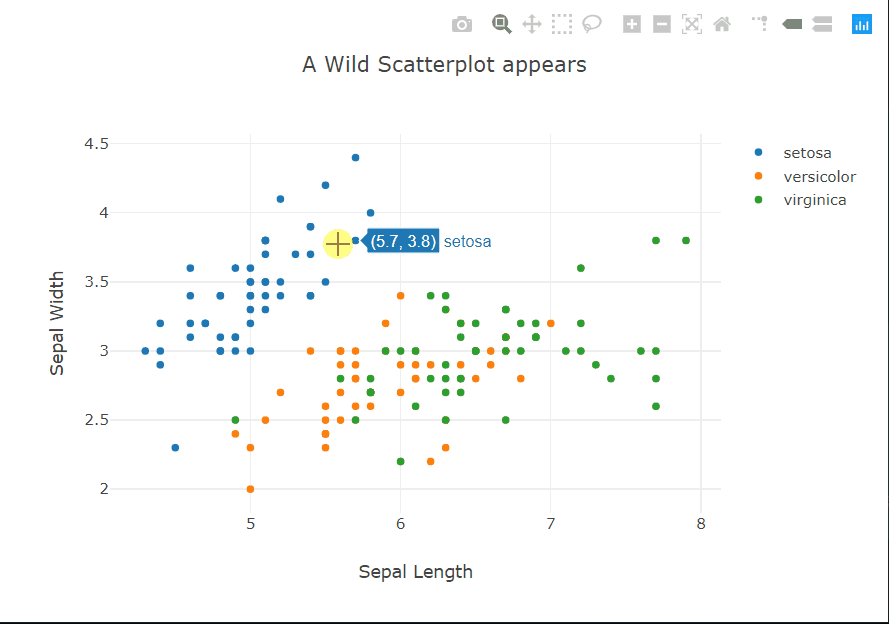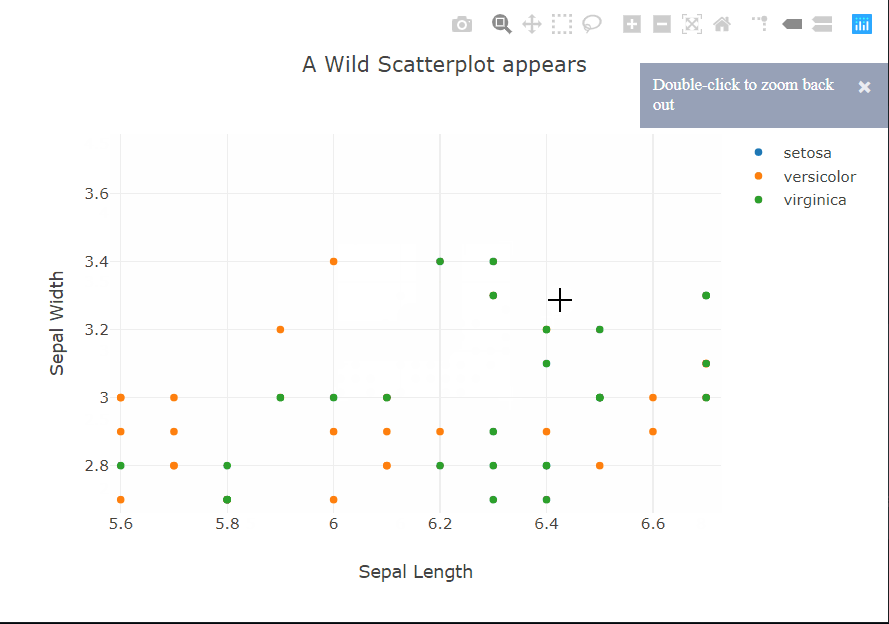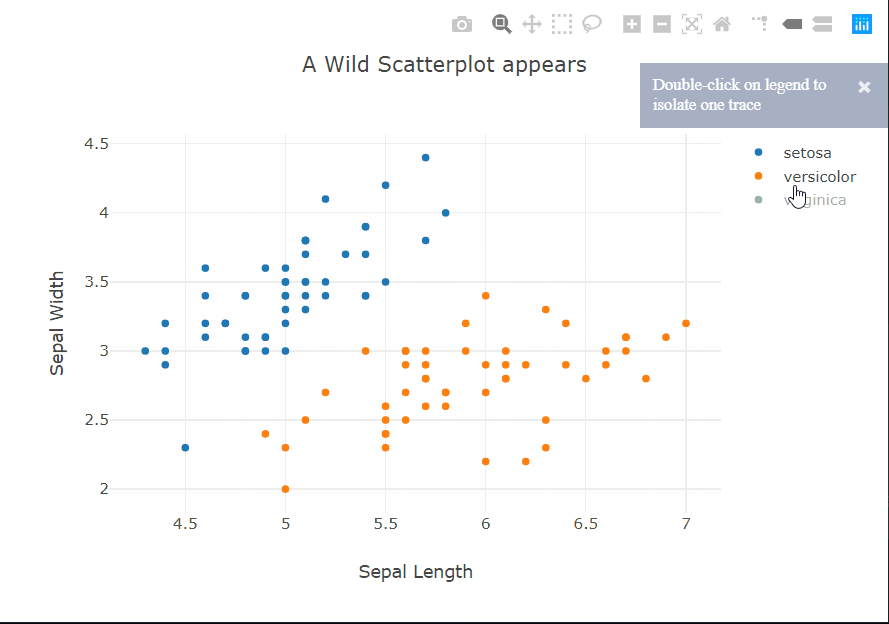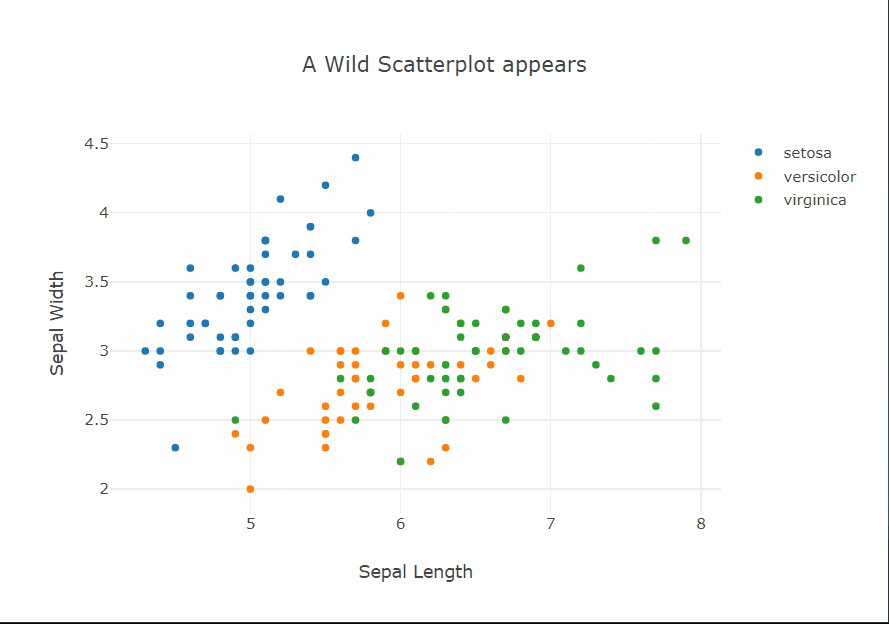
Looking at the plots, the matplotlib and seaborn plots are basically identical, the only difference is in the amount of code. The seaborn library has a nice interface to generate a colored scatter plot based on the hue argument, but in matplotlib we are basically creating three scatter plots on the same axis. The different colors are automatically assigned in both (default color cycle but can also be specified for customization). Other relatively minor differences are in the labels and legend, where seaborn creates these automatically. This, in my experience, is less useful than it seems because very rarely do datasets have nicely formatted column names. Usually, they contain abbreviations or symbols so you still have to assign ‘proper’ labels.
But we really want to see what Plotly has done, don’t we? This time I’ll start with the code. It’s eerily similar to matplotlib, apart from not sharing the exact syntax of course, and the hovermode option. Hovering? Does that mean…? Yes, yes it does. Moving the cursor over a point reveals a tooltip showing the coordinates of the point and the class label.
The tooltip can also be customized to show other information about a particular point. To the top right of the panel, there are controls to zoom, select, and pan across the plot. The legend is also interactive, it acts sort of like checkboxes. You can click on a class to hide/show all the points of that class.
Since the amount or complexity of code isn’t that drastically different from the other two options and we get all these interactivity options, I’d argue this is basically free benefits.
fig, ax = plt.subplots(figsize=(8,6))
grouped_df = iris.groupby('species').mean()
ax.bar(grouped_df.index.values,
grouped_df['sepal_length'].values);
ax.set(xlabel='Species', ylabel='Average Sepal Length', title='A Wild Barchart appears');
fig, ax = plt.subplots(figsize=(8,6))
sns.barplot(data=iris, x='species', y='sepal_length', estimator=np.mean, ax=ax);
ax.set(xlabel='Species', ylabel='Average Sepal Length', title='A Wild Barchart appears');
fig = go.FigureWidget()
grouped_df = iris.groupby('species').mean()
fig.add_bar(x=grouped_df.index, y=grouped_df['sepal_length']);
fig.layout.xaxis.title = 'Species'
fig.layout.yaxis.title = 'Average Sepal Length'
fig.layout.title = 'A Wild Barchart appears'
fig
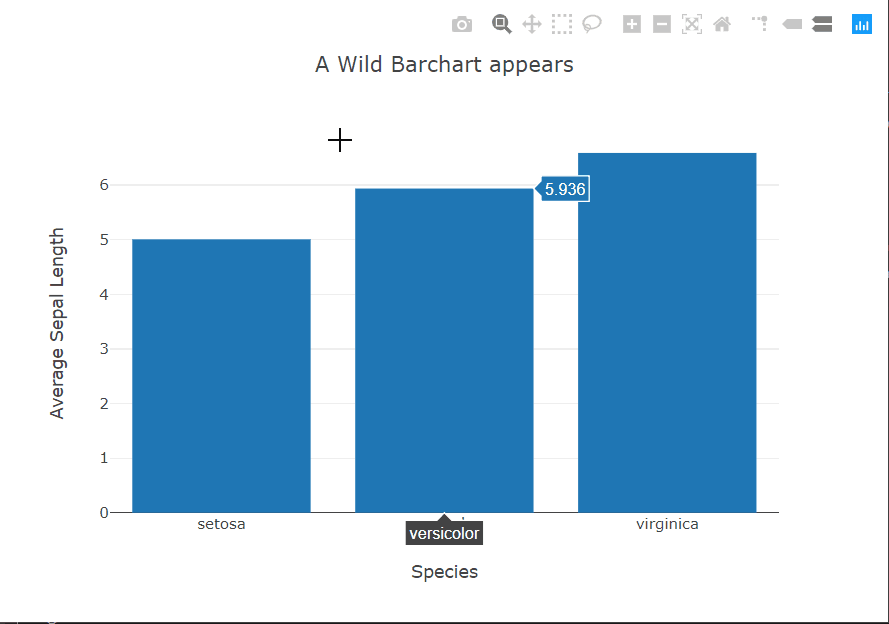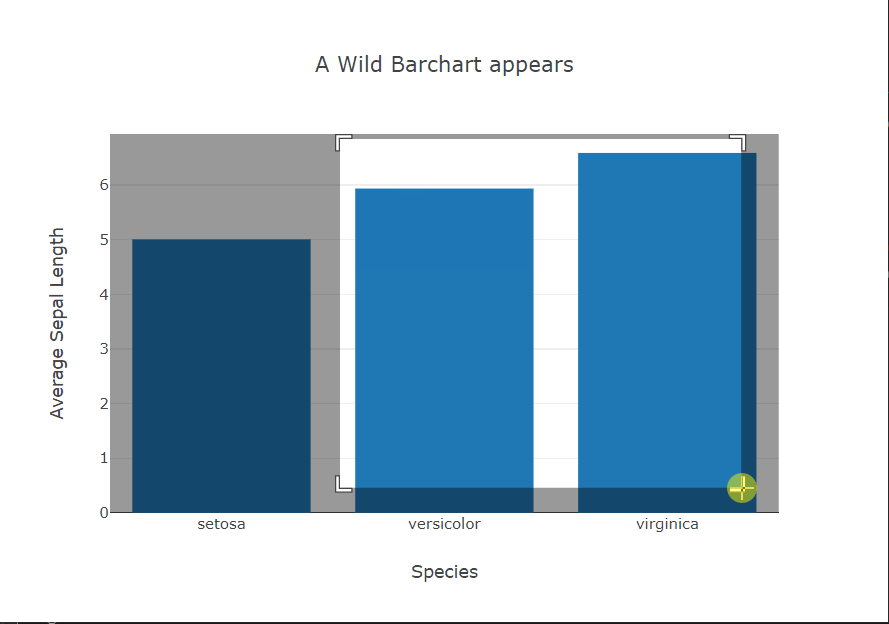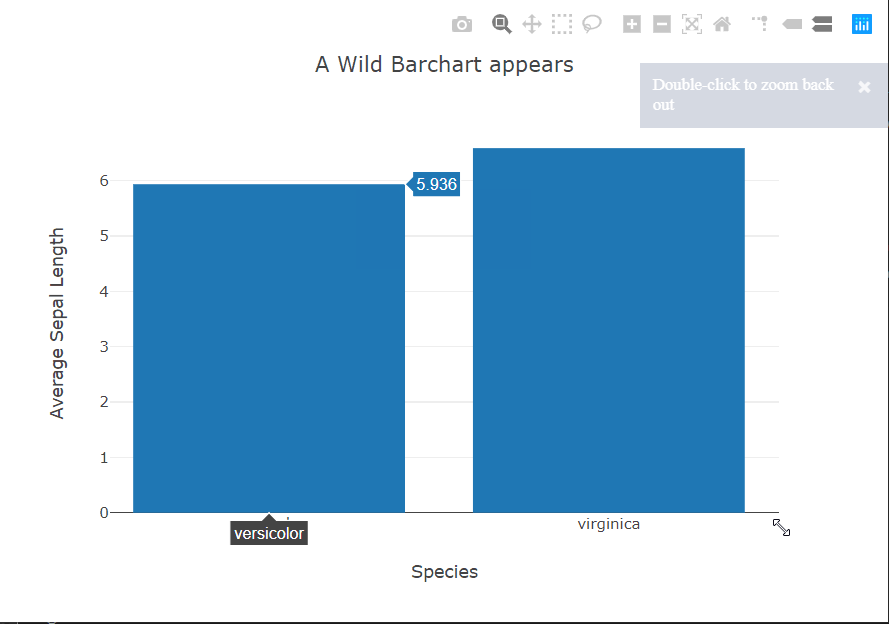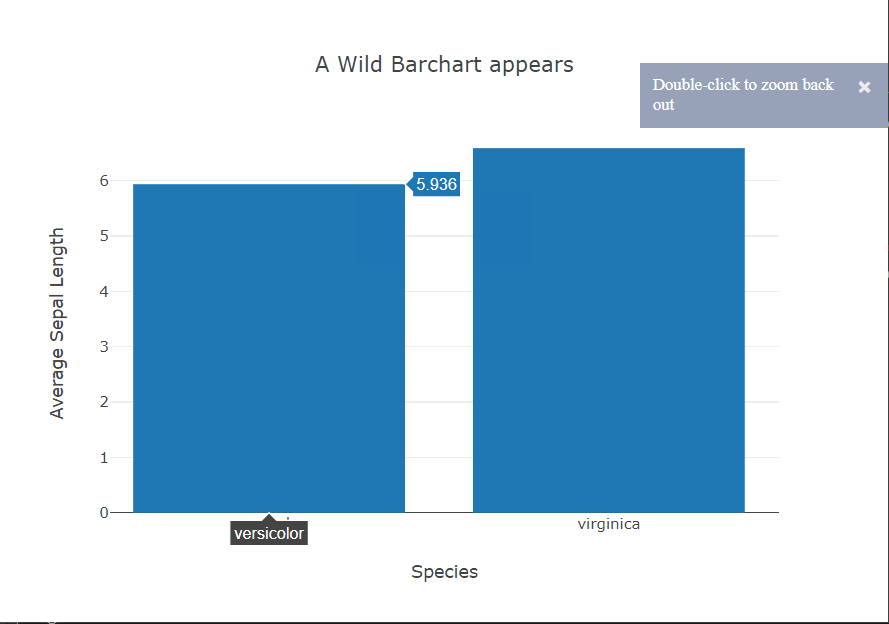
The bar chart story is similar to the scatter plots. In this case, again, seaborn provides the option within the function call to specify the metric to be shown on the y-axis using the x variable as the grouping variable. For the other two, we have to do this ourselves using pandas. Plotly still provides interactivity out of the box.
Now that we’ve seen that Plotly can hold its own against our usual plotting options, let’s see what other benefits it can bring to the table. I will showcase some trace types in Plotly that are useful in a data science workflow, and how interactivity can make them more informative.
Heatmaps
fig = go.FigureWidget()
cor_mat = car_crashes.corr()
fig.add_heatmap(z=cor_mat,
x=cor_mat.columns,
y=cor_mat.columns,
showscale=True)
fig.layout.width = 500
fig.layout.height = 500
fig.layout.yaxis.automargin = True
fig.layout.title = 'A Wild Heatmap appears'
fig
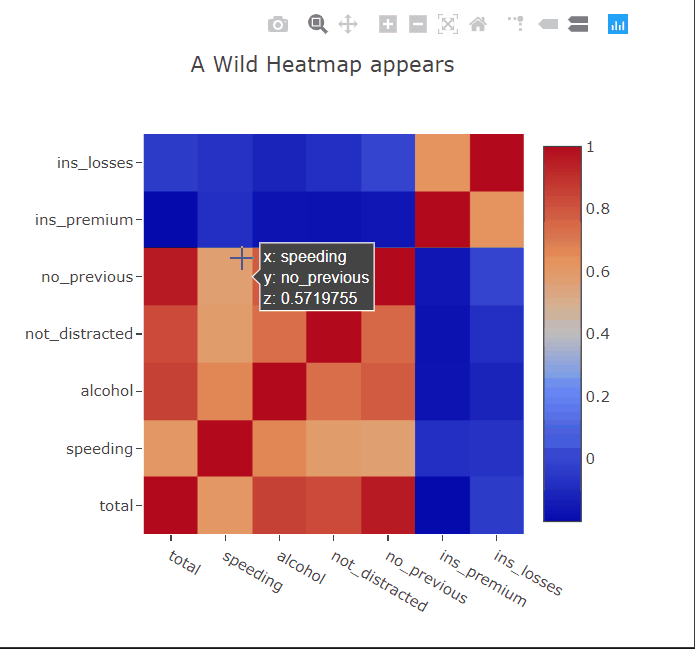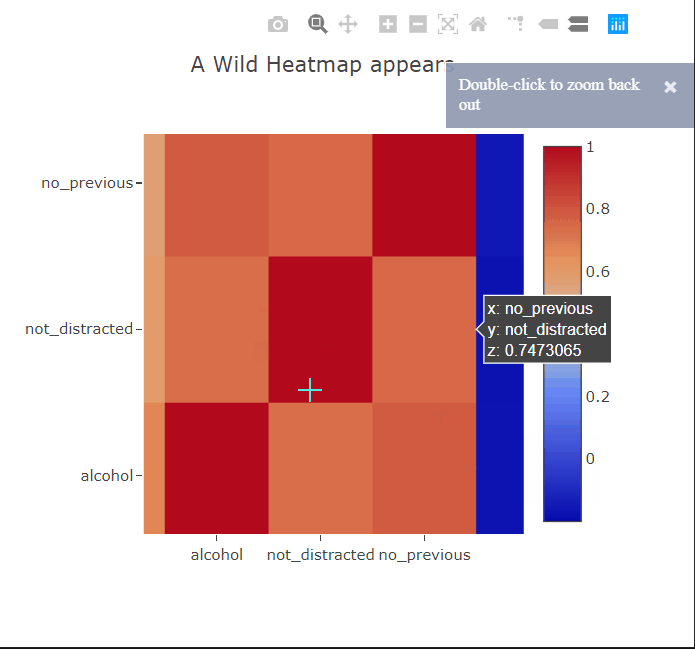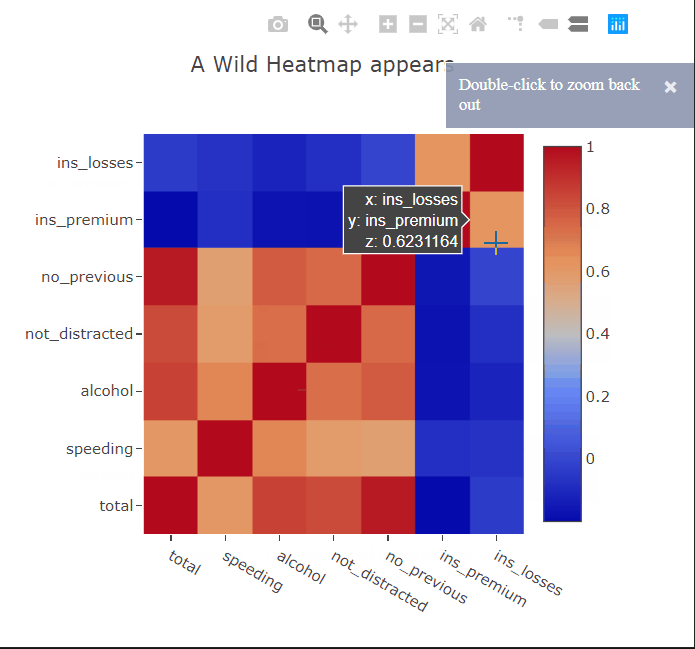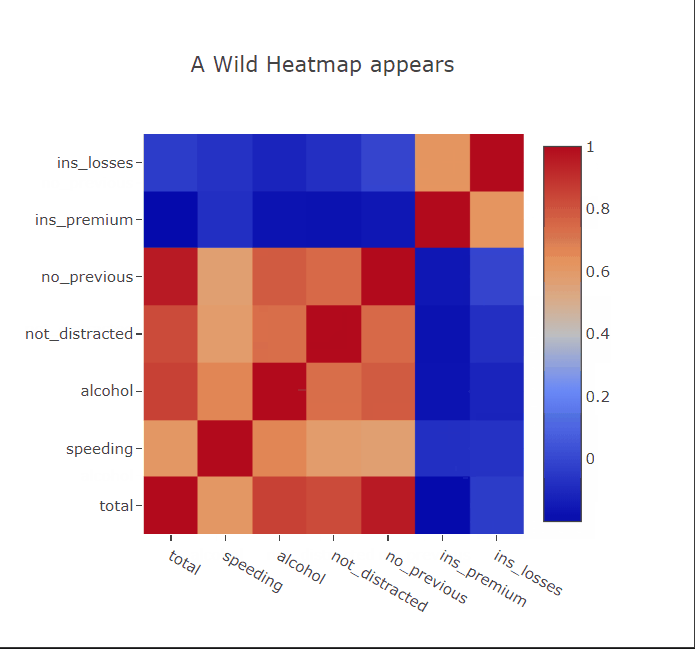
Heatmaps are commonly used to plot correlation or confusion matrices. As expected, we can hover over the squares to get more information about the variables. I’ll paint a picture for you. Suppose you have trained a linear regression model to predict something from this dataset. You can then show the appropriate coefficients in the hover tooltips to get a better idea of which correlations in the data the model has captured.
Parallel coordinates plot
fig = go.FigureWidget()
parcords = fig.add_parcoords(dimensions=[{'label':n.title(),
'values':iris[n],
'range':[0,8]} for n in iris.columns[:-2]])
fig.data[0].dimensions[0].constraintrange = [4,8]
parcords.line.color = iris['species_id']
parcords.line.colorscale = make_plotly(cl.scales['3']['qual']['Set2'], repeat=True)
parcords.line.colorbar.title = ''
parcords.line.colorbar.tickvals = np.unique(iris['species_id']).tolist()
parcords.line.colorbar.ticktext = np.unique(iris['species']).tolist()
fig.layout.title = 'A Wild Parallel Coordinates Plot appears'
fig
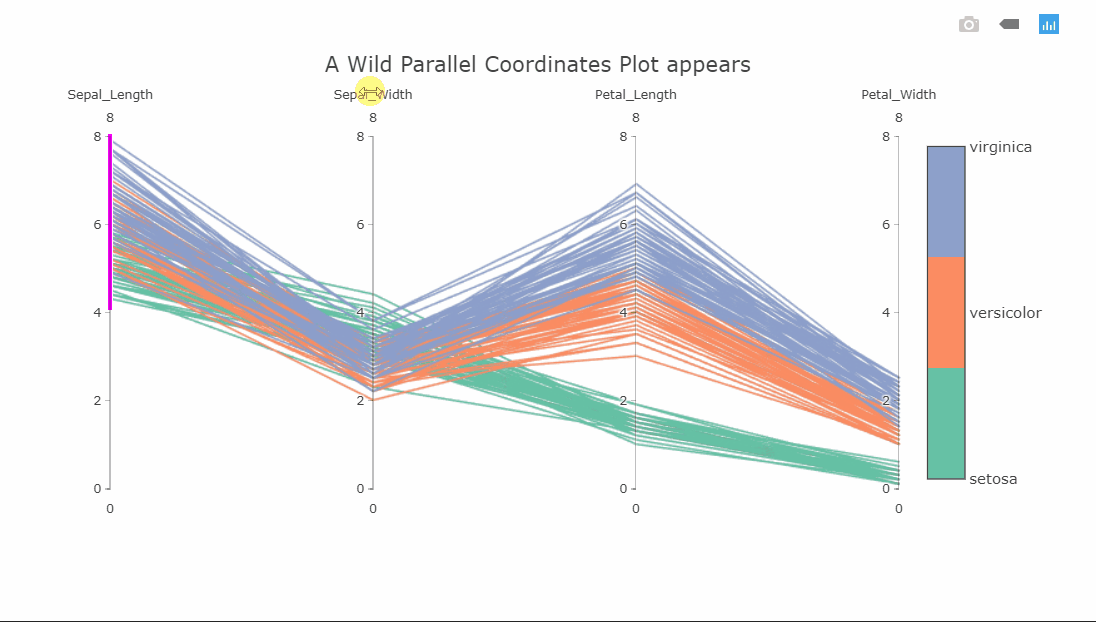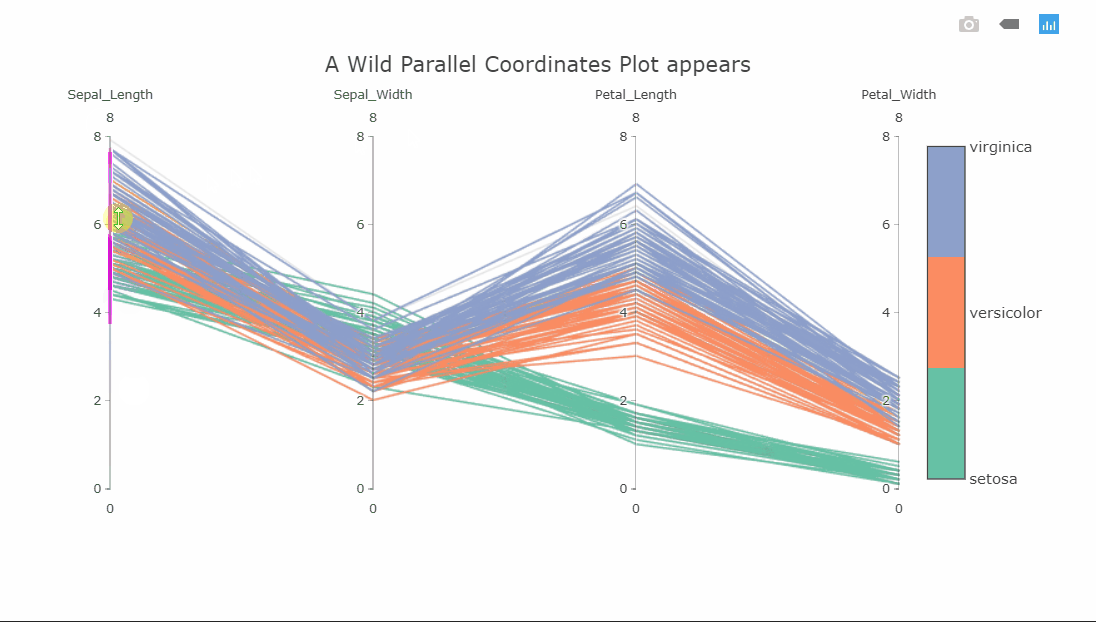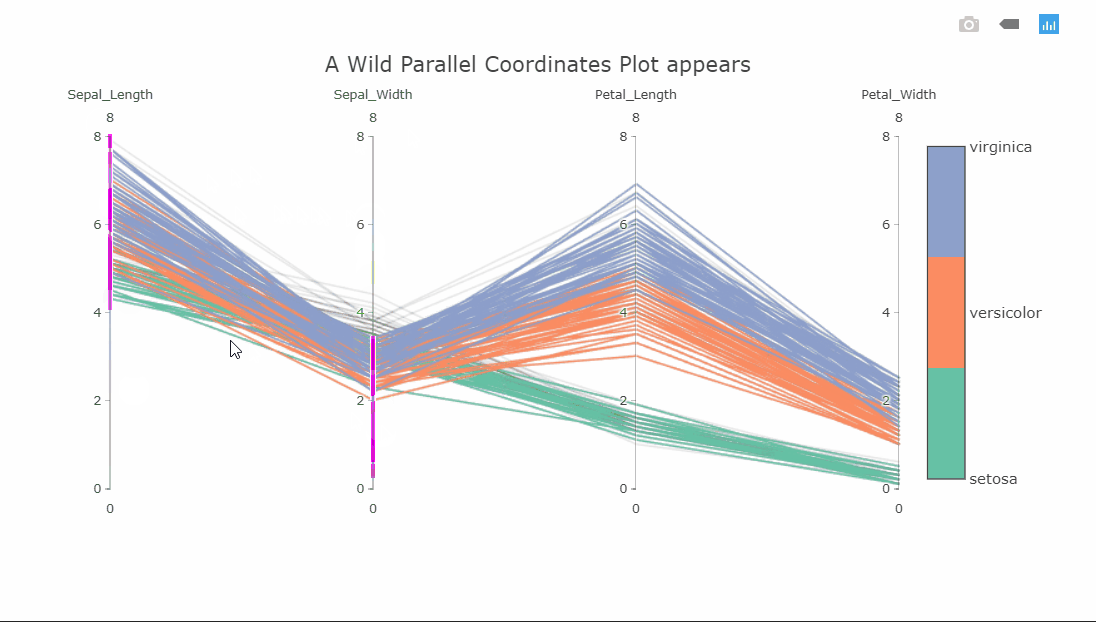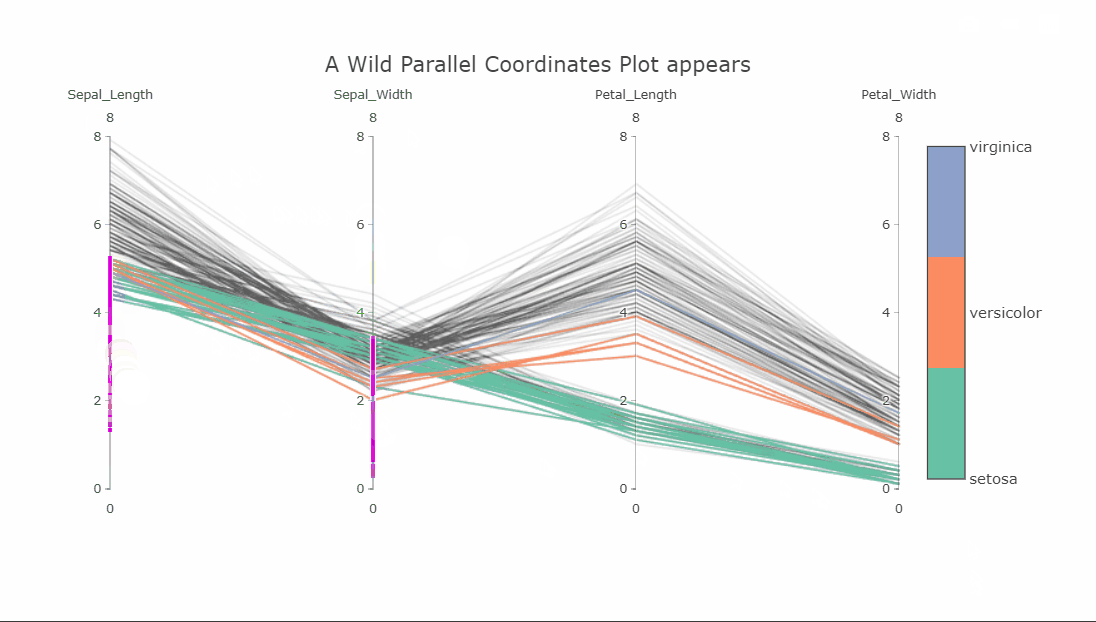
I suspect some of you might not yet be familiar with this visualization, as I wasn’t a few months ago. This is a parallel coordinates plot of four variables. Each variable is shown on a separate vertical axis. Each line corresponds to a row in the dataset and the color obviously shows which class that row belongs to. A thing that should jump out at you is that the class separation in each variable axis is clearly visible. For instance, the Petal_Length variable can be used to classify all the Setosa flowers very well.
Since the plot is interactive, the axes can be reordered by dragging to explore the interconnectedness between the classes and how it affects the class separations. Another interesting interaction is the constrained range widget (the bright pink object on the Sepal_Length axis).
It can be dragged up or down to decolor the plot. Imagine having these on all axes and finding a sweet spot where only one class is visible. As a side note, the decolored plot has a transparency effect on the lines so the density of values can be seen.
A version of this type of visualization also exists for categorical variables in Plotly. It is called Parallel Categories.
Choropleth plot
fig = go.FigureWidget()
choro = fig.add_choropleth(locations=gdp['CODE'],
z=gdp['GDP (BILLIONS)'],
text = gdp['COUNTRY'])
choro.marker.line.width = 0.1
choro.colorbar.tickprefix = '$'
choro.colorbar.title = 'GDP<br>Billions US$'
fig.layout.geo.showframe = False
fig.layout.geo.showcoastlines = False
fig.layout.title = 'A Wild Choropleth appears<br>Source:\
<a href="https://www.cia.gov/library/publications/the-world-factbook/fields/2195.html">\
CIA World Factbook</a>'
fig
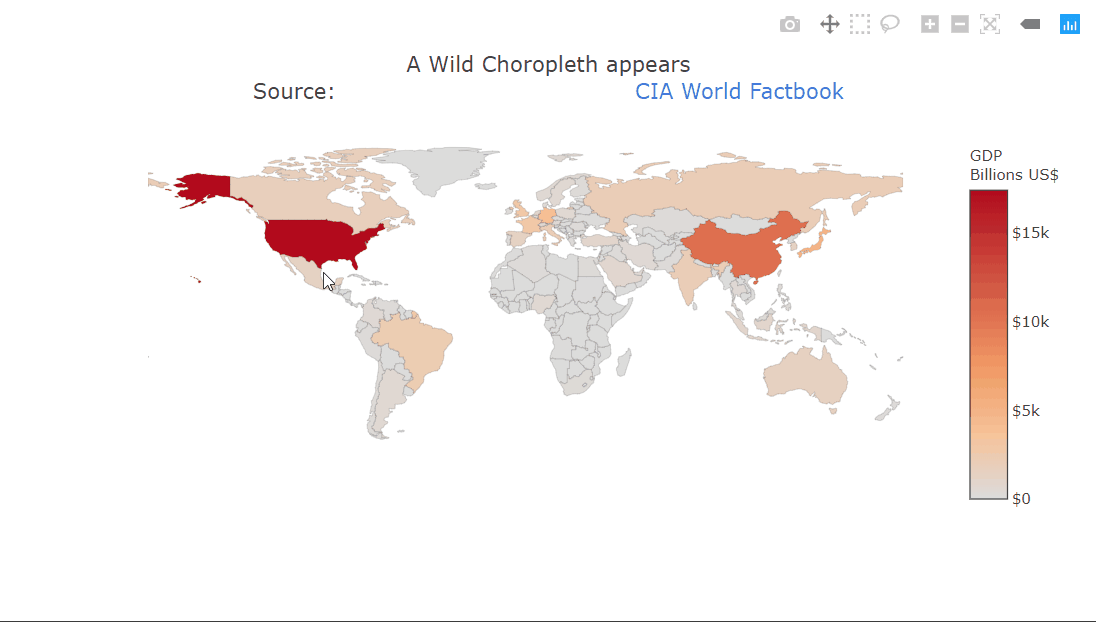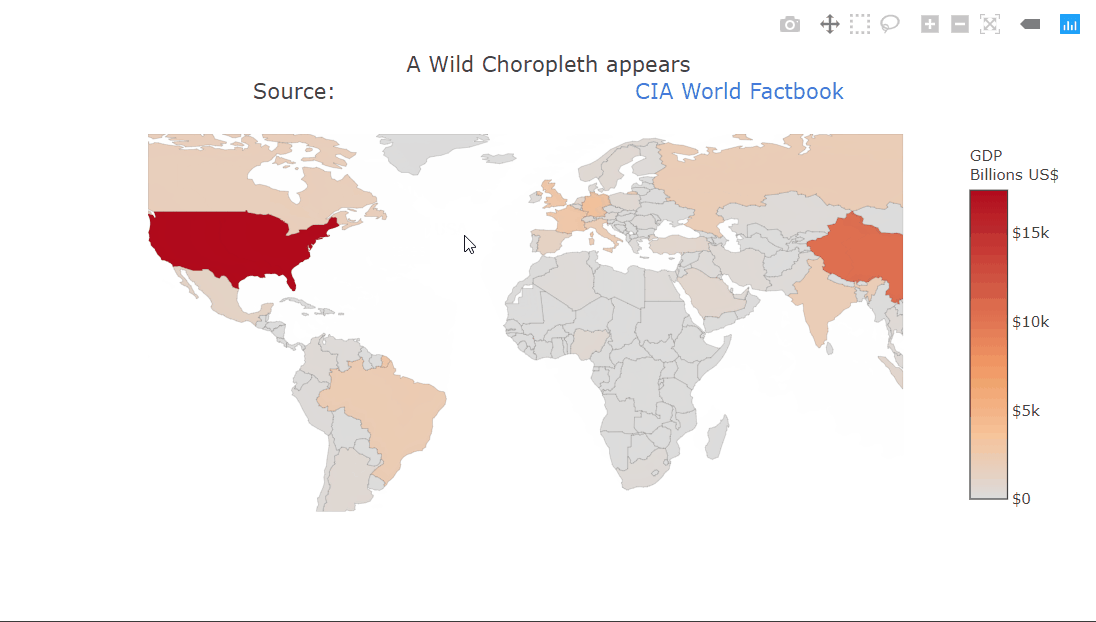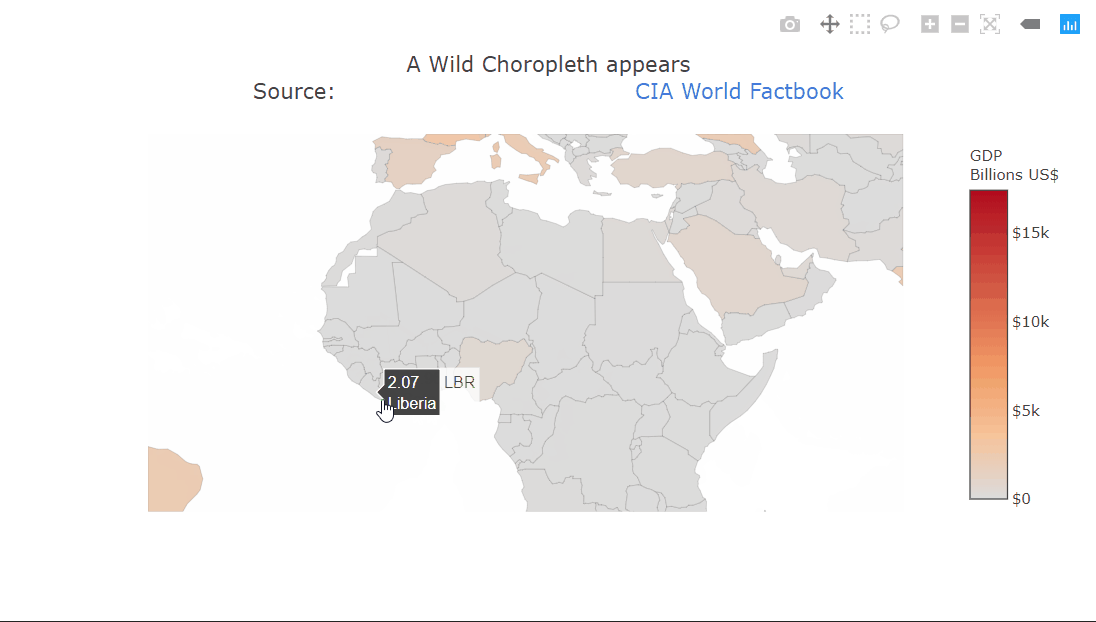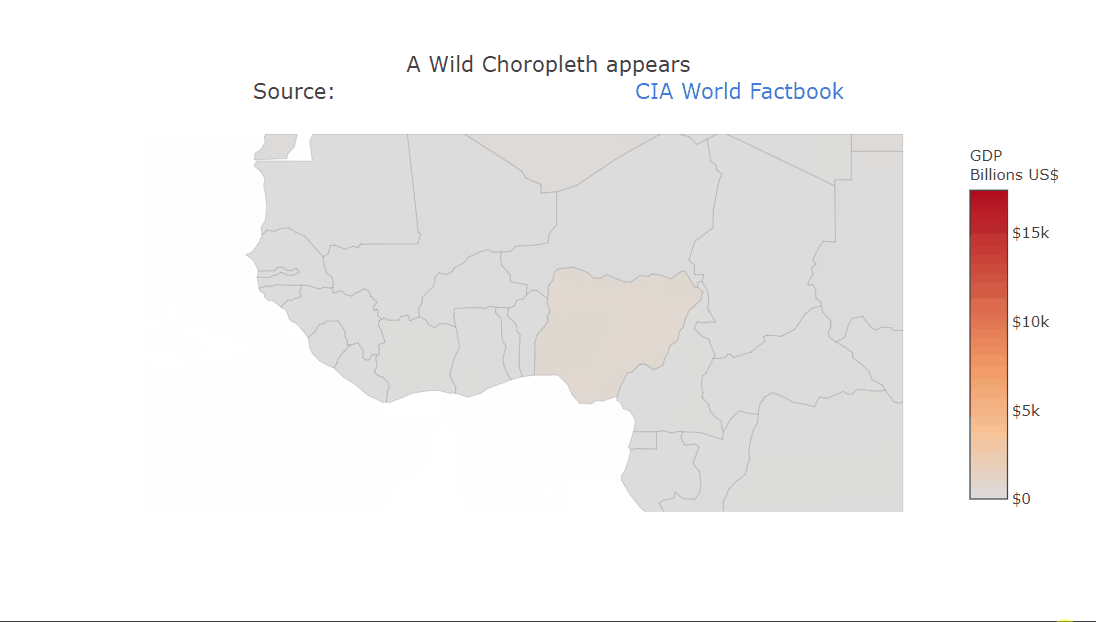
A choropleth is a very commonly used geographical plot. The benefit of the interactivity should be clear in this one. We can only show a single variable using the color but the tooltip can be used for extra information. Zooming in is also very useful in this case, allowing us to look at the smaller countries. The plot title contains HTML which is being rendered properly. This can be used to create fancier labels.
Interactive scatter plot
fig = go.FigureWidget()
scatter_trace = fig.add_scattergl(x=diamonds['carat'], y=diamonds['price'],
mode='markers', marker={'opacity':0.2});
fig.layout.hovermode = 'closest'
fig.layout.xaxis.title = 'Carat'
fig.layout.yaxis.title = 'Price'
fig.layout.title = 'A Wild Scatterplot appears'
fig
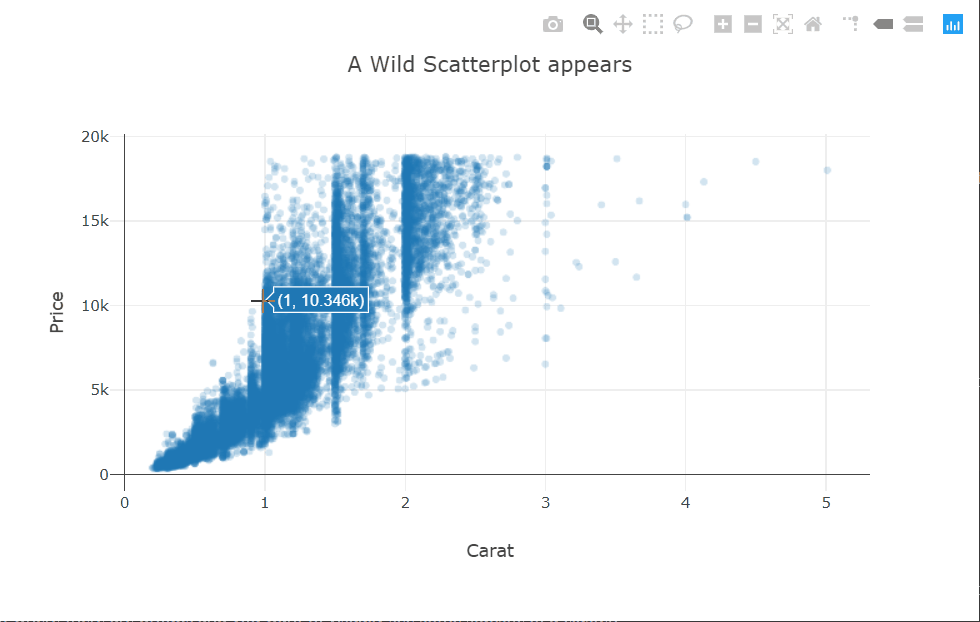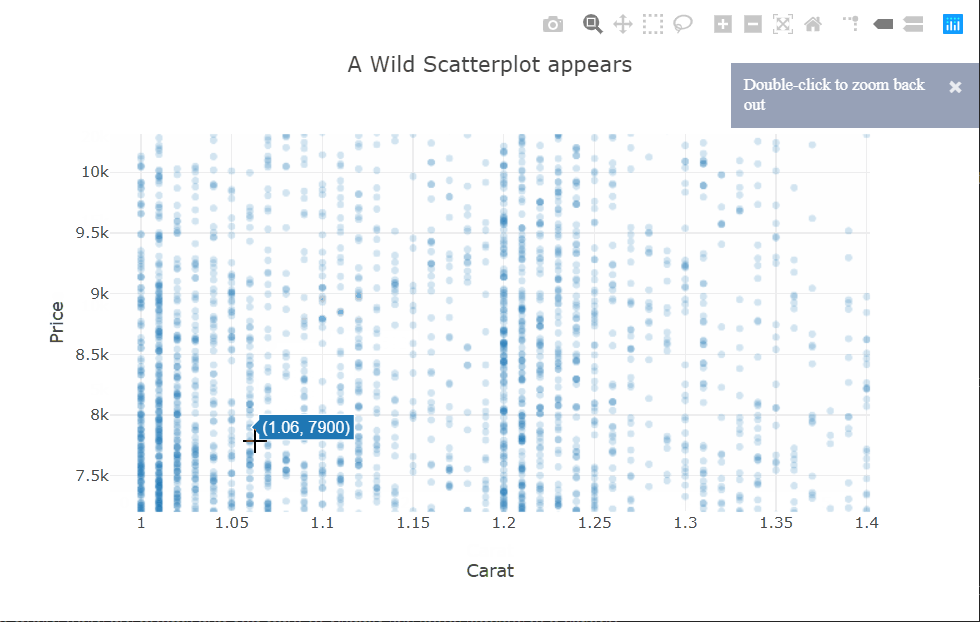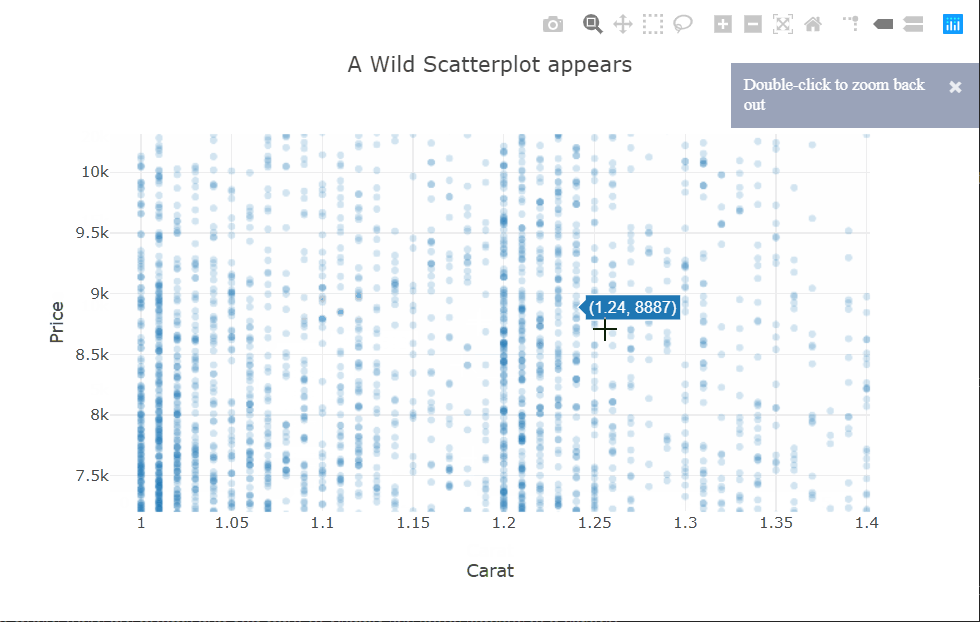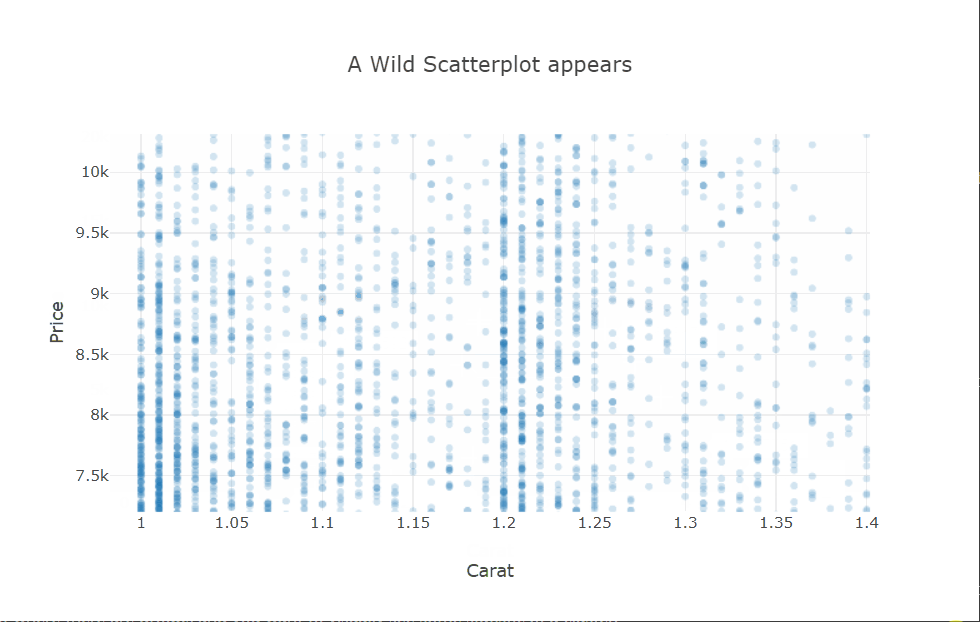
I’m using the scattergl trace type here. This is a version of the scatter plot that uses WebGL in the background so that the interactions don’t get laggy even with larger datasets.
There is quite a bit of over-plotting here even with the aggressive transparency, so let’s zoom into the densest part to take a closer look. Zooming in reveals that the carat variable is quantized and there are clean vertical lines.
def selection_handler(trace, points, selector):
data_mean = np.mean(points.ys)
fig.data[0].figure.layout.title.text = f'A Wild Scatterplot appears - mean price: ${data_mean:.1f}'
fig.data[0].on_selection(selection_handler)
fig
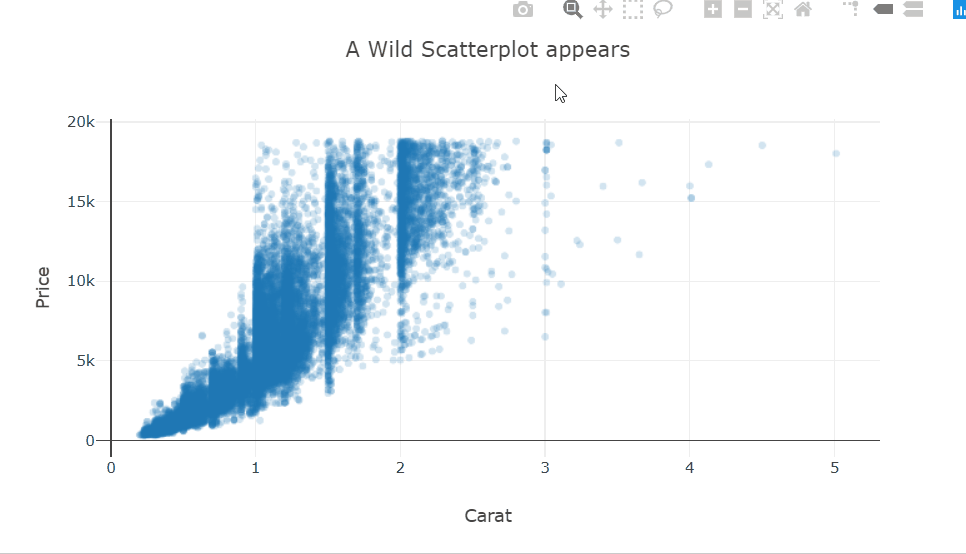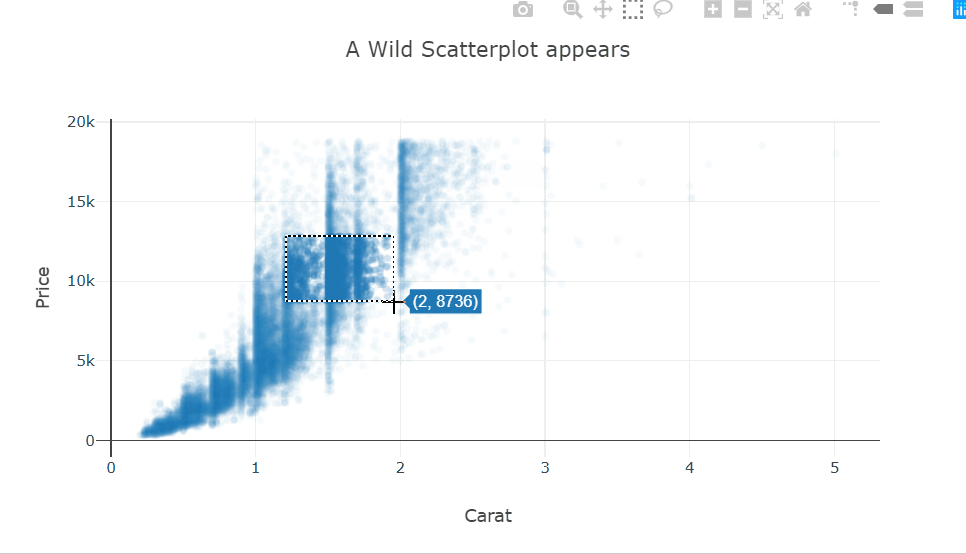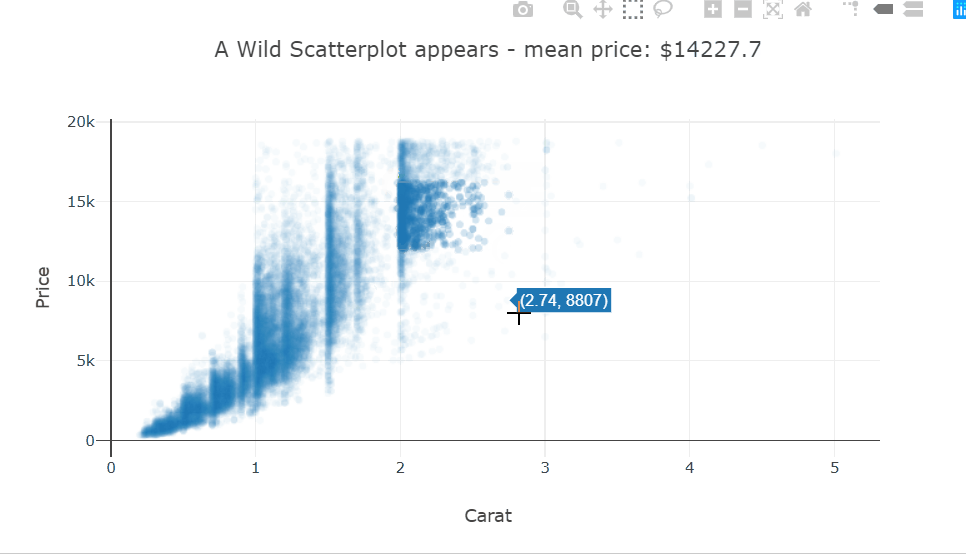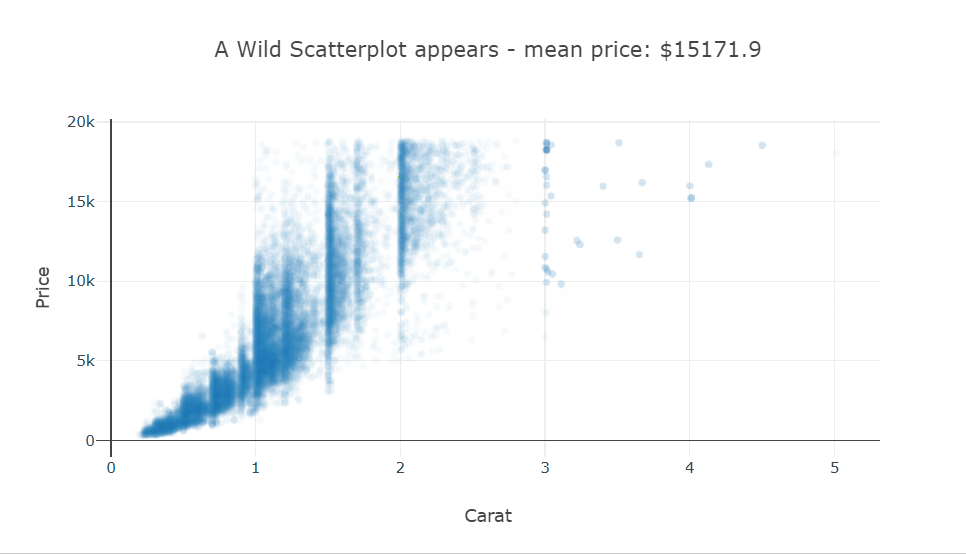
Selecting a bunch of points in this scatter plot will change the title of the plot to show the mean price of the selected points. This could prove to be very useful in a plot where there are groups and you want to visually see some statistics of a cluster.
This behavior is easily implemented using callback functions attached to predefined event handlers for each trace.
More interactivity
Let’s do something fancier now.
fig1 = go.FigureWidget()
fig1.add_scattergl(x=exports['beef'], y=exports['total exports'],
text=exports['state'],
mode='markers');
fig1.layout.hovermode = 'closest'
fig1.layout.xaxis.title = 'Beef Exports in Million US$'
fig1.layout.yaxis.title = 'Total Exports in Million US$'
fig1.layout.title = 'A Wild Scatterplot appears'
fig2 = go.FigureWidget()
fig2.add_choropleth(locations=exports['code'],
z=exports['total exports'].astype('float64'),
text=exports['state'],
locationmode='USA-states')
fig2.data[0].marker.line.width = 0.1
fig2.data[0].marker.line.color = 'white'
fig2.data[0].marker.line.width = 2
fig2.data[0].colorbar.title = 'Exports Millions USD'
fig2.layout.geo.showframe = False
fig2.layout.geo.scope = 'usa'
fig2.layout.geo.showcoastlines = False
fig2.layout.title = 'A Wild Choropleth appears'
def do_selection(trace, points, selector):
if trace is fig2.data[0]:
fig1.data[0].selectedpoints = points.point_inds
else:
fig2.data[0].selectedpoints = points.point_inds
fig1.data[0].on_selection(do_selection)
fig2.data[0].on_selection(do_selection)
HBox([fig1, fig2])
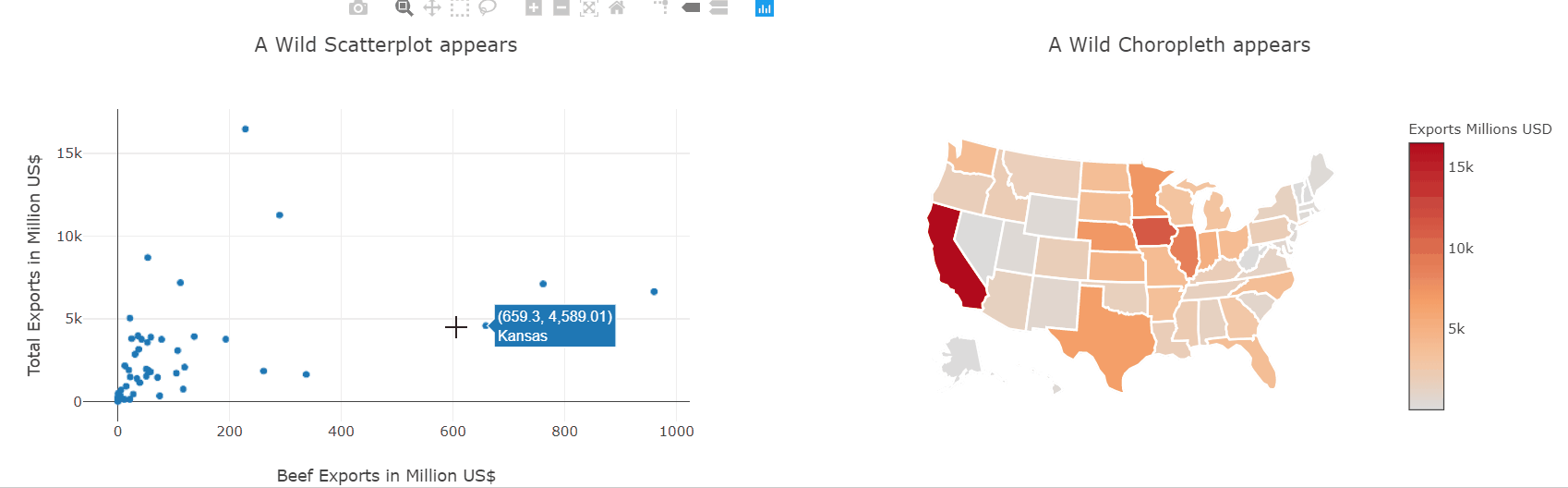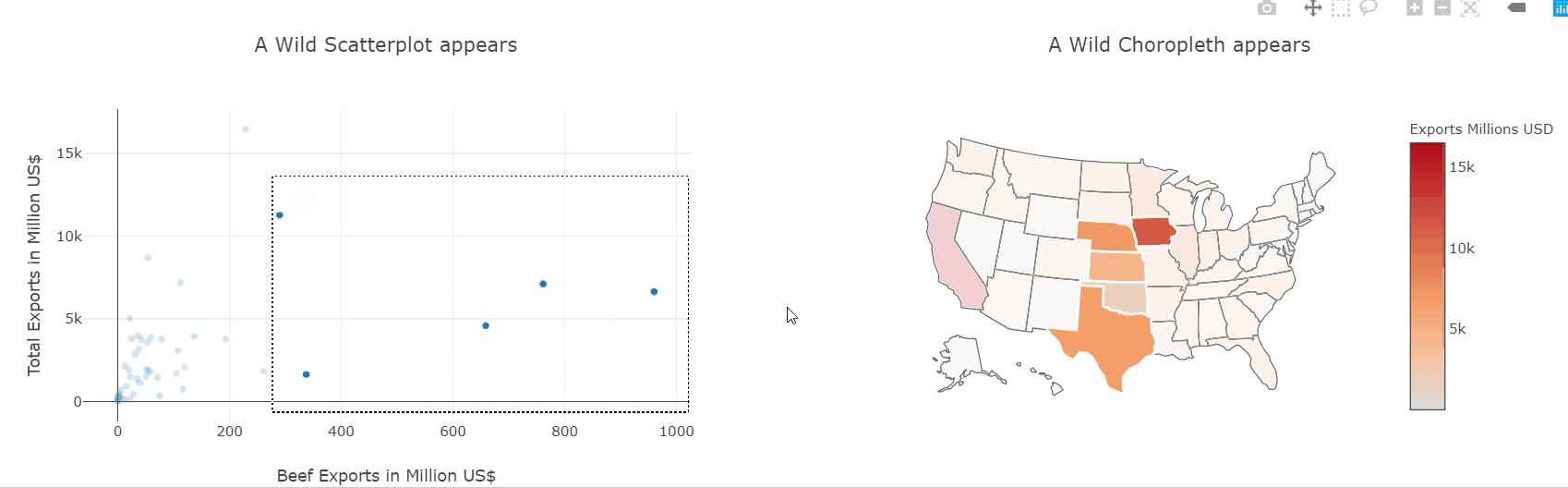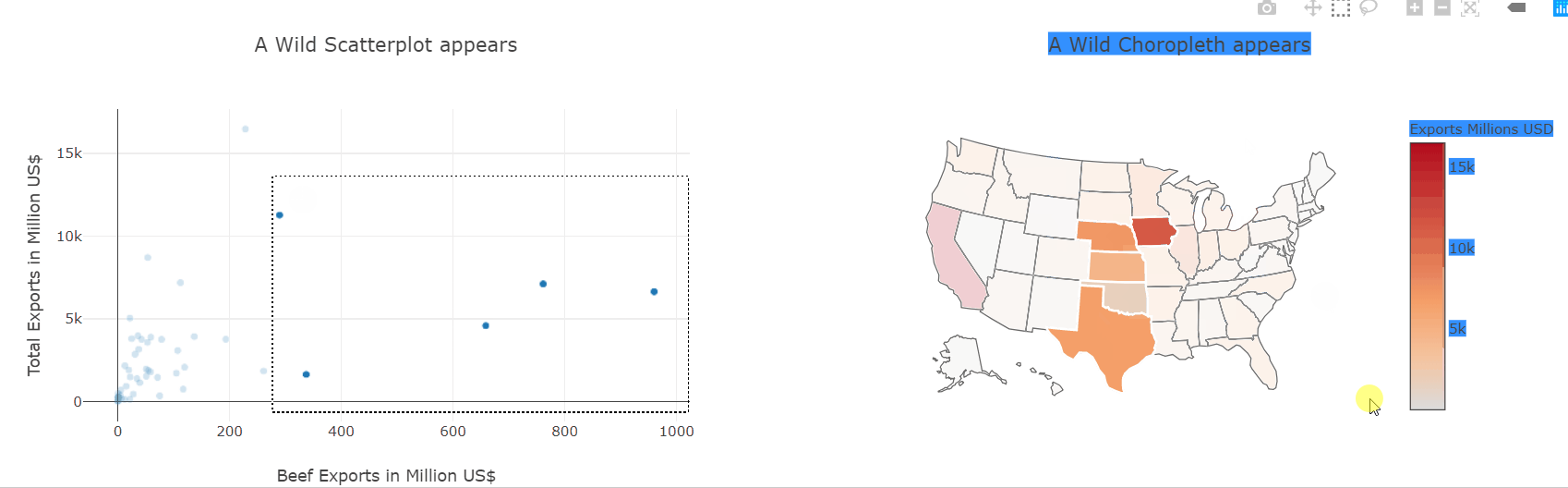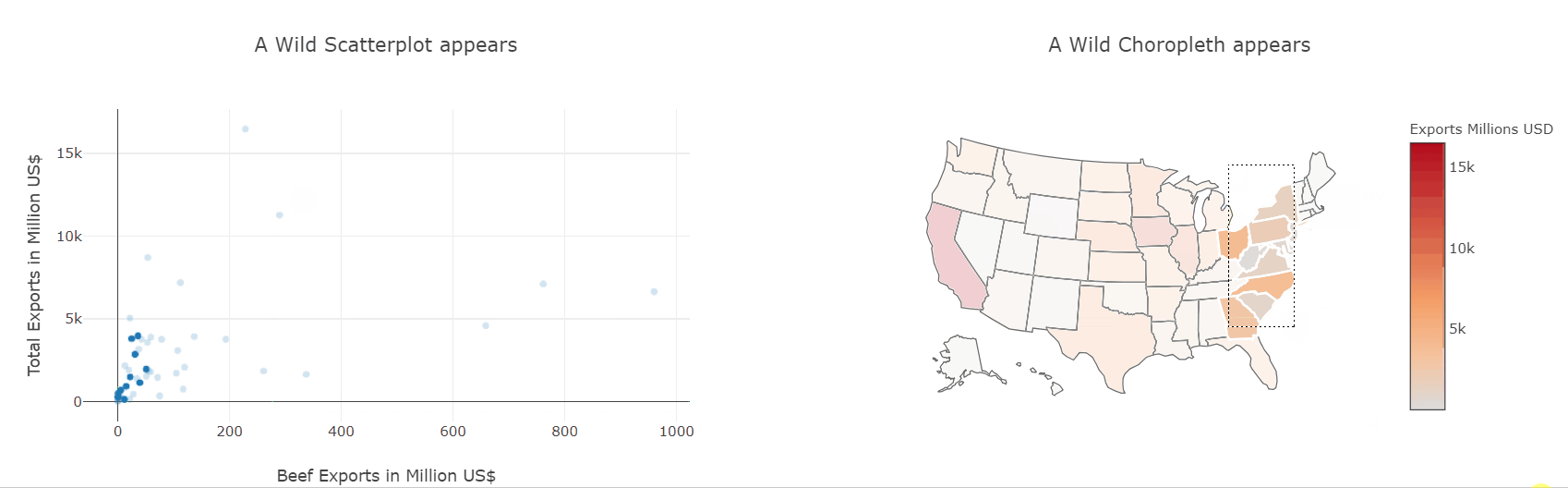
We have already seen how to make scatter and choropleth plots so let’s put them to use and plot the same data-frame. Then, using the event handlers we also saw before, we can link both plots together and interactively explore which states produce which kinds of goods.
This kind of interactive exploration of different slices of the dataset is far more intuitive and natural than transforming the data in pandas and then plotting it again.
fig = go.FigureWidget()
fig.add_histogram(x=iris['sepal_length'],
histnorm='probability density');
fig.layout.xaxis.title = 'Sepal Length'
fig.layout.yaxis.title = 'Probability Density'
fig.layout.title = 'A Wild Histogram appears'
def change_binsize(s):
fig.data[0].xbins.size = s
slider = interactive(change_binsize, s=(0.1,1,0.1))
label = Label('Bin Size: ')
VBox([HBox([label, slider]),
fig])
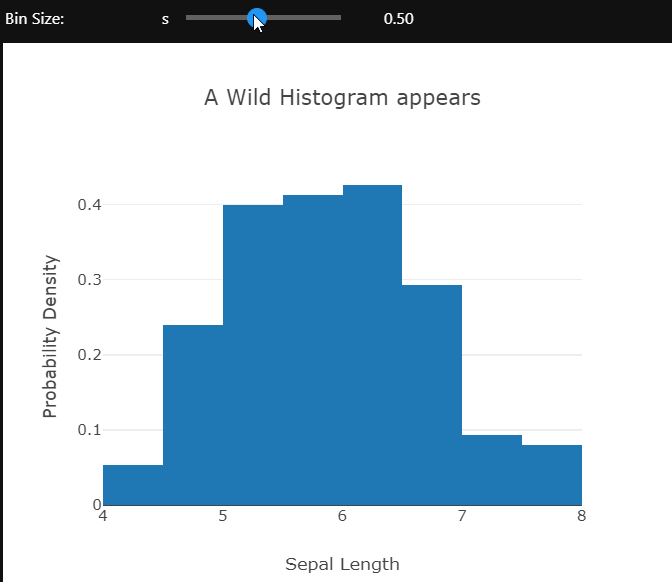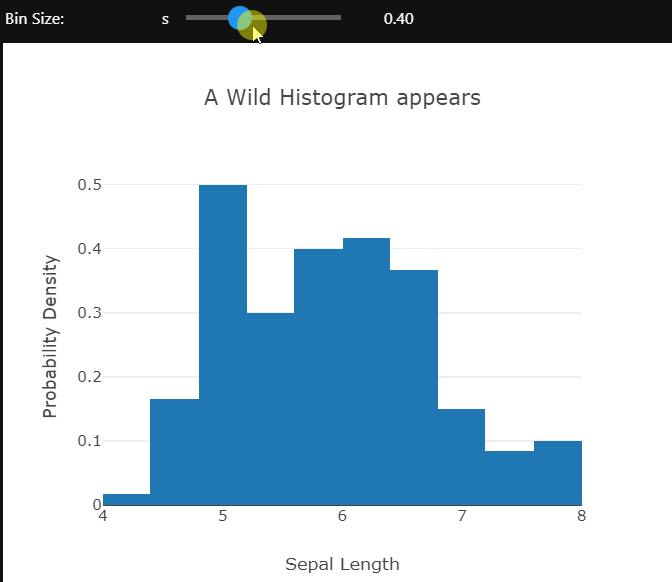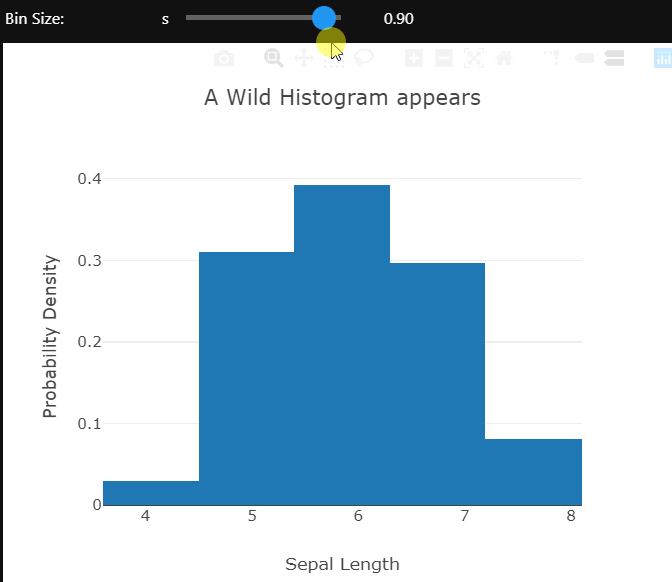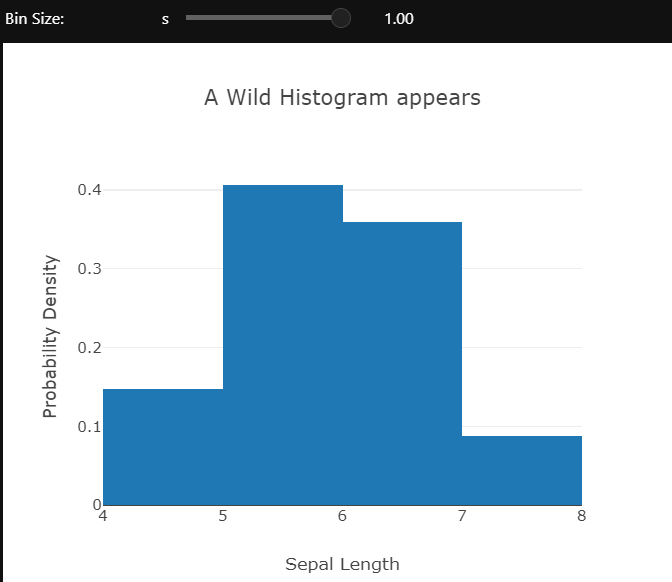
Using the ipywidgets module’s interactive controls different aspects of the plot can be changed to gain a better understanding of the data. Here the bin size of the histogram is being controlled.
fig = go.FigureWidget()
scatter_trace = fig.add_scattergl(x=diamonds['carat'], y=diamonds['price'],
mode='markers', marker={'opacity':0.2});
fig.layout.hovermode = 'closest'
fig.layout.xaxis.title = 'Carat'
fig.layout.yaxis.title = 'Price'
fig.layout.title = 'A Wild Scatterplot appears'
def change_opacity(x):
fig.data[0].marker.opacity = x
slider = interactive(change_opacity, x=(0.1,1,0.1))
label = Label('Marker Opacity: ')
VBox([HBox([label, slider]),
fig])
The opacity of the markers in this scatter plot is controlled by the slider. These examples only control the visual or layout aspects of the plot. We can also change the actual data which is being shown using dropdowns. I’ll leave you to explore that on your own.
What have we learned about Python plots
Let’s take a step back and sum up what we have learned. We saw that Plotly can reveal more information about our data using interactive controls, which we get for free and with no extra code. We saw a few interesting, slightly more complex visualizations available to us. We then combined the plots with custom widgets to create custom interactive workflows.
All this is just scratching the surface of what Plotly is capable of. There are many more trace types, an animations framework, and integration with Dash to create professional dashboards and probably a few other things that I don’t even know of.