Your one-stop shop for machine learning algorithms. These 101 algorithms are equipped with cheat sheets, tutorials, and explanations.
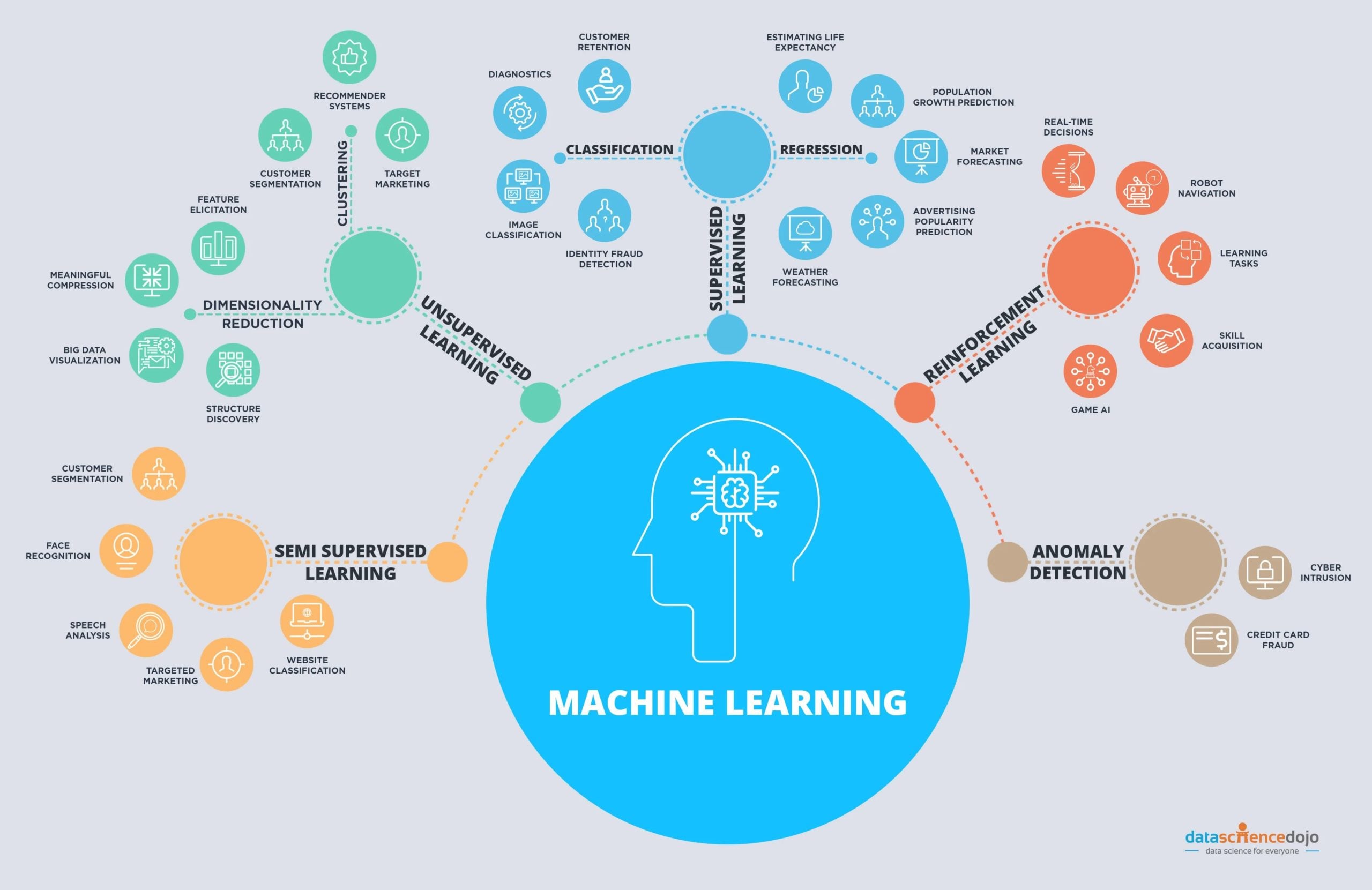
Think of this as the one-stop shop/dictionary/directory for machine learning algorithms. The algorithms have been sorted into 9 groups: Anomaly Detection, Association Rule Learning, Classification, Clustering, Dimensional Reduction, Ensemble, Neural Networks, Regression, Regularization. In this post, you’ll find 101 machine learning algorithms with useful Python tutorials, R tutorials, and cheat sheets from Microsoft Azure ML, SAS, and Scikit-Learn to help you know when to use each one (if available).
101 machine learning algorithms
At Data Science Dojo, our mission is to make data science (machine learning in this case) available to everyone. Whether you join our data science boot camp or online data science certificate program, read our blog, or watch our tutorials, we want everyone to have the opportunity to learn data science.
Having said that, each accordion dropdown is embeddable if you want to take them with you. All you have to do is click the little ‘Embed’ button in the lower left-hand corner and copy/paste the iframe, or download the file by clicking ‘Reuse’.
Within each dropdown, you’ll see a description of data science algorithms with a tutorial in either R or Python (and one tutorial in Julia). For some, the R tutorial was too troublesome to find, and the R documentation was used instead. For the Boltzmann Machine algorithm, you will only find a description. Tutorials can be found under the Restricted Boltzmann Machine.
By the way, if you have trouble with Medium/TDS, just throw your browser into incognito mode.
Classification algorithms
Any of these classification algorithms can be used to build a model that predicts the outcome class for a given dataset. The datasets can come from a variety of domains. Depending upon the dimensionality of the dataset, the attribute types, sparsity, and missing values, etc., one algorithm might give better predictive accuracy than most others. Let’s briefly discuss these algorithms. (18)
Regression analysis
Regression Analysis is a statistical method for examining the relationship between two or more variables. There are many different types of Regression analysis, of which a few algorithms can be found below. (20)
Neural networks
A neural network is an artificial model based on the human brain. These systems learn tasks by example without being told any specific rules. (11)
Anomaly detection
Also known as outlier detection, anomaly detection is used to find rare occurrences or suspicious events in your data. The outliers typically point to a problem or rare event. (5)
Also known as outlier detection, anomaly detection is used to find rare occurrences or suspicious events in your data. The outliers typically point to a problem or rare event. (5)
Dimensionality reduction
With some problems, especially classification, there can be so many variables, or features, that it is difficult to visualize your data. The correlation amongst your features creates redundancies, and that’s where dimensionality reduction comes in. Dimensionality Reduction reduces the number of random variables you’re working with. (17)
Ensemble
Ensemble learning methods are meta-algorithms that combine several machine learning methods into a single predictive model to increase the overall performance. (11)
Clustering
In supervised learning, we know the labels of the data points and their distribution. However, the labels may not always be known. Clustering is the practice of assigning labels to unlabeled data using the patterns that exist in it. Clustering can either be semi-parametric or probabilistic. (14)
Association rule learning
Association Rule Learning, also known as association rule analysis, is a technique to uncover how items are associated with each other. (2)
Regularization
Regularization is used to prevent overfitting. Overfitting means a machine learning algorithm has fit the data set too strongly such that it has high accuracy in it but does not perform well on unseen data. (3)
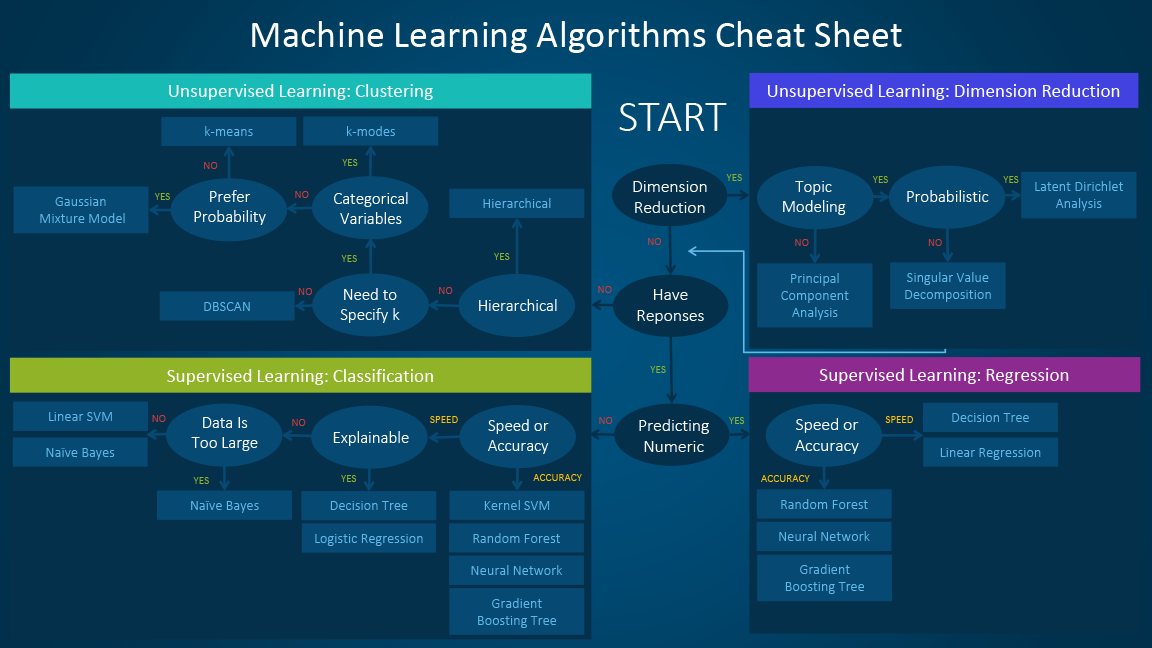
Scikit-Learn algorithm cheat sheet
First and foremost is the Scikit-Learn machine learning algorithms cheat sheet. If you click the image, you’ll be taken to the same graphic except it will be interactive. We suggest saving this site as it makes remembering the data science algorithms, and when best to use them, incredibly simple and easy.
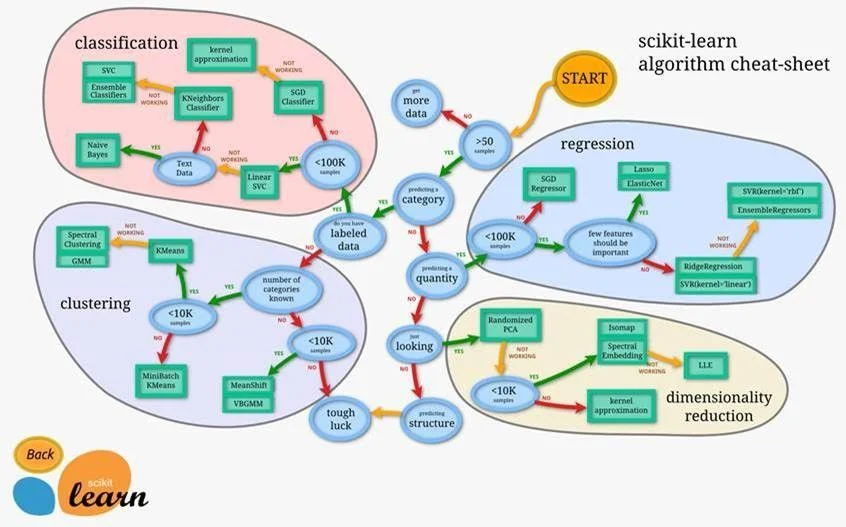
SAS: The machine learning algorithms cheat sheet
You can also find many of the same algorithms on SAS’s machine learning cheat sheet as the one above. The SAS website (click the pic) also gives great descriptions about how, when, and why to use each algorithm.
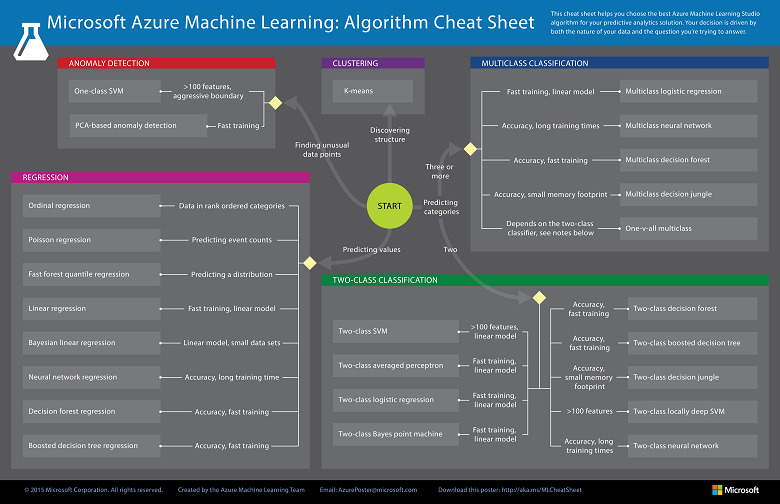
Microsoft azure machine learning: Algorithms cheat sheet
Microsoft Azure’s ML cheat sheet is the simplest cheat sheet by far. Even though it’s simple, Microsoft was still able to pack a ton of information into it. Microsoft also made its algorithm sheet available to download.
There you have it, 101 machine learning algorithms with cheat sheets, descriptions, and tutorials! We hope you’re able to make good use of this list. If there are any algorithms that you think should be added, go ahead and leave a comment with the algorithm and a link to a tutorial. Thanks!