

Before we understand LlamaIndex, let’s step back a bit. Imagine a futuristic landscape where machines possess an extraordinary ability to understand and produce human-like text effortlessly. LLMs have made this vision a reality. Armed with a vast ocean of training data, these marvels of innovation have become the crown jewels of the tech world.
There is no denying that LLMs (Large Language Models) are currently the talk of the town! From revolutionizing text generation and reasoning, LLMs are trained on massive datasets and have been making waves in the tech vicinity.
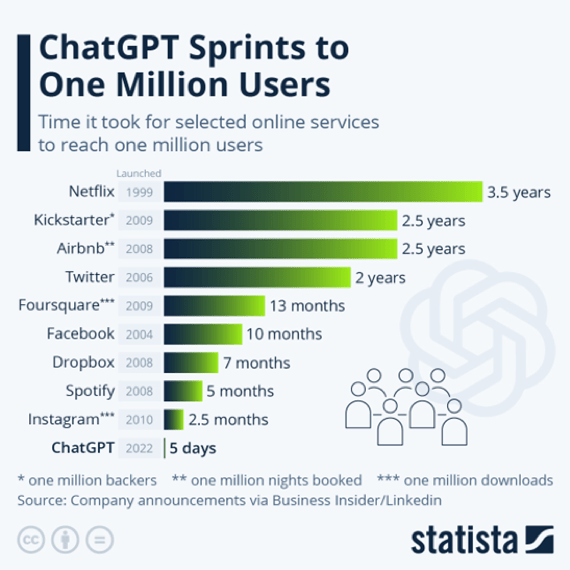
One particular LLM has emerged as a true superstar. Back in November 2022, ChatGPT, an LLM developed by OpenAI, attracted a staggering one million users within 5 days of its beta launch.
When researchers and developers saw these stats they started thinking on how we can best feed/augment these LLMs with our own private data. They started thinking about different solutions.
Finetune your own LLM. You adapt an existing LLM by training your data. But, this is very costly and time-consuming.
Combining all the documents into a single large prompt for an LLM might be possible now with the increased token limit of 100k for models. However, this approach could result in slower processing times and higher computational costs.
Instead of inputting all the data, selectively provide relevant information to the LLM prompt. Choose the useful bits for each query instead of including everything.
Option 3 appears to be both relevant and feasible, but it requires the development of a specialized toolkit. Recognizing this need, efforts have already begun to create the necessary tools.

Introducing LlamaIndex
Recently a toolkit was launched for building applications using LLM, known as Langchain. LlamaIndex is built on top of Langchain to provide a central interface to connect your LLMs with external data.
Key Components of LlamaIndex
The key components of LlamaIndex are as follows
- Data Connectors: The data connector, known as the Reader, collects data from various sources and formats, converting it into a straightforward document format with textual content and basic metadata.
- Data Index: It is a data structure facilitating efficient retrieval of pertinent information in response to user queries. At a broad level, Indices are constructed using Documents and serve as the foundation for Query Engines and Chat Engines, enabling seamless interactions and question-and-answer capabilities based on the underlying data. Internally, Indices store data within Node objects, which represent segments of the original documents.
- Retrievers: Retrievers play a crucial role in obtaining the most pertinent information based on user queries or chat messages. They can be constructed based on Indices or as standalone components and serve as a fundamental element in Query Engines and Chat Engines for retrieving contextually relevant data.
- Query Engines: A query engine is a versatile interface that enables users to pose questions regarding their data. By accepting natural language queries, the query engine provides comprehensive and informative responses.
- Chat Engines: A chat engine serves as an advanced interface for engaging in interactive conversations with your data, allowing for multiple exchanges instead of a single question-and-answer format. Similar to ChatGPT but enhanced with access to a knowledge base, the chat engine maintains a contextual understanding by retaining the conversation history and can provide answers that consider the relevant past context.
Query Engine vs. Chat Engine: Key Differences
It is important to note that there is a significant distinction between a query engine and a chat engine. Although they may appear similar at first glance, they serve different purposes:
A query engine operates as an independent system that handles individual questions over the data without maintaining a record of the conversation history.
On the other hand, a chat engine is designed to keep track of the entire conversation history, allowing users to query both the data and previous responses. This functionality resembles ChatGPT, where the chat engine leverages the context of past exchanges to provide more comprehensive and contextually relevant answers
- Customization: LlamaIndex offers customization options where you can modify the default settings, such as the utilization of OpenAI’s text-davinci-003 model. Users have the flexibility to customize the underlying language model (LLM) and other settings used in LlamaIndex, with support for various integrations and LangChain’s LLM modules.
- Analysis: LlamaIndex offers a diverse range of analysis tools for examining indices and queries. These tools include features for analyzing token usage and associated costs. Additionally, LlamaIndex provides a Playground module, which presents a visual interface for analyzing token usage across different index structures and evaluating performance metrics.
- Structured Outputs: LlamaIndex offers an assortment of modules that empower language models (LLMs) to generate structured outputs. These modules are available at various levels of abstraction, providing flexibility and versatility in producing organized and formatted results.
- Evaluation: LlamaIndex provides essential modules for assessing the quality of both document retrieval and response synthesis. These modules enable the evaluation of “hallucination,” which refers to situations where the generated response does not align with the retrieved sources. A hallucination occurs when the model generates an answer without effectively grounding it in the given contextual information from the prompt.
- Integrations: LlamaIndex offers a wide array of integrations with various toolsets and storage providers. These integrations encompass features such as utilizing vector stores, integrating with ChatGPT plugins, compatibility with Langchain, and the capability to trace with Graphsignal. These integrations enhance the functionality and versatility of LlamaIndex by allowing seamless interaction with different tools and platforms.
- Callbacks: LlamaIndex offers a callback feature that assists in debugging, tracking, and tracing the internal operations of the library. The callback manager allows for the addition of multiple callbacks as required. These callbacks not only log event-related data but also track the duration and frequency of each event occurrence. Moreover, a trace map of events is recorded, providing valuable information that callbacks can utilize in a manner that best suits their specific needs.
- Storage: LlamaIndex offers a user-friendly interface that simplifies the process of ingesting, indexing, and querying external data. By abstracting away complexities, LlamaIndex allows users to query their data with just a few lines of code. Behind the scenes, LlamaIndex provides the flexibility to customize storage components for different purposes. This includes document stores for storing ingested documents (represented as Node objects), index stores for storing index metadata, and vector stores for storing embedding vectors.The document and index stores utilize a shared key-value store abstraction, providing a common framework for efficient storage and retrieval of data
Now that we have explored the key components of LlamaIndex, let’s delve into its operational mechanisms and understand how it functions.
How Llama-Index Works
To begin, the first step is to import the documents into LlamaIndex, which provides various pre-existing readers for sources like databases, Discord, Slack, Google Sheets, Notion, and the one we will utilize today, the Simple Directory Reader, among others.[Text Wrapping Break][Text Wrapping Break]You can check for more here: Llama Hub (llama-hub-ui.vercel.app)

Once the documents are loaded, LlamaIndex proceeds to parse them into nodes, which are essentially segments of text. Subsequently, an index is constructed to enable quick retrieval of relevant data when querying the documents. The index can be stored in different formats, but we will opt for a Vector Store as it is typically the most useful when querying text documents without specific limitations.
LlamaIndex is built upon LangChain, which serves as the foundational framework for a wide range of LLM applications. While LangChain provides the fundamental building blocks, LlamaIndex is specifically designed to streamline the workflow described above.
Here is an example code showcasing the utilization of the SimpleDirectoryReader data loader in LlamaIndex, along with the integration of the OpenAI language model for natural language processing.
Installing the necessary libraries required to run the code.
Importing openai library and setting the secret API (Application Programming Interface) key.
Importing the SimpleDirectoryReader class from llama_index library and loading the data from it.
Importing SimpleNodeParser class from llama_index and parsing the documents into nodes – basically in chunks of text.
Importing VectorStoreIndex class from llama_index to create index from the chunks of text so that each time when a query is placed only relevant data is sent to OpenAI. In short, for the sake of cost effectiveness.
Conclusion
LlamaIndex, built on top of Langchain, offers a powerful toolkit for integrating external data with LLMs. By parsing documents into nodes, constructing an efficient index, and selectively querying relevant information, LlamaIndex enables cost-effective exploration of text data.
The provided code example demonstrates the utilization of LlamaIndex’s data loader and query engine, showcasing its potential for next-generation text exploration. For the notebook of the above code, refer to the source code available here.
