

Have you ever wondered what it would be like if computers could see the world just like we do? Think about it – a machine that can look at a photo and understand everything in it, just like you would. This isn’t science fiction anymore; it’s what’s happening right now with Large Vision Models (LVMs).

Large vision models are a type of AI technology that deals with visual data like images and videos. Essentially, they are like big digital brains that can understand and create visuals. They are trained on extensive datasets of images and videos, enabling them to recognize patterns, objects, and scenes within visual content.
Learn about 32 datasets to uplift your Skills in Data Science
LVMs can perform a variety of tasks such as image classification, object detection, image generation, and even complex image editing, by understanding and manipulating visual elements in a way that mimics human visual perception.
How Large Vision Models differ from Large Language Models
Large Vision Models and Large Language Models both handle large data volumes but differ in their data types. LLMs process text data from the internet, helping them understand and generate text, and even translate languages.
In contrast, large vision models focus on visual data, working to comprehend and create images and videos. However, they face a challenge: the visual data in practical applications, like medical or industrial images, often differs significantly from general internet imagery.
Internet-based visuals tend to be diverse but not necessarily representative of specialized fields. For example, the type of images used in medical diagnostics, such as MRI scans or X-rays, are vastly different from everyday photographs shared online.
Understand the Use of AI in Healthcare
Similarly, visuals in industrial settings, like manufacturing or quality control, involve specific elements that general internet images do not cover. This discrepancy necessitates “domain specificity” in large vision models, meaning they need tailored training to effectively handle specific types of visual data relevant to particular industries.
Importance of Domain-Specific Large Vision Models
Domain specificity refers to tailoring an LVM to interact effectively with a particular set of images unique to a specific application domain. For instance, images used in healthcare, manufacturing, or any industry-specific applications might not resemble those found on the Internet.
Accordingly, an LVM trained with general Internet images may struggle to identify relevant features in these industry-specific images. By making these models domain-specific, they can be better adapted to handle these unique visual tasks, offering more accurate performance when dealing with images different from those usually found on the internet.
For instance, a domain-specific large vision model trained in medical imaging would have a better understanding of anatomical structures and be more adept at identifying abnormalities than a generic model trained in standard internet images.
Explore LLM Finance to understand the Power of Large Language Models in the Financial Industry
This specialization is crucial for applications where precision is paramount, such as in detecting early signs of diseases or in the intricate inspection processes in manufacturing. In contrast, LLMs are not concerned with domain-specificity as much, as internet text tends to cover a vast array of domains making them less dependent on industry-specific training data.
Learn how LLM Development is Making Chatbots Smarter
Performance of Domain-Specific LVMs Compared with Generic LVMs
Comparing the performance of domain-specific Large Vision Models and generic LVMs reveals a significant edge for the former in identifying relevant features in specific domain images.
In several experiments conducted by experts from Landing AI, domain-specific LVMs – adapted to specific domains like pathology or semiconductor wafer inspection – significantly outperformed generic LVMs in finding relevant features in images of these domains.
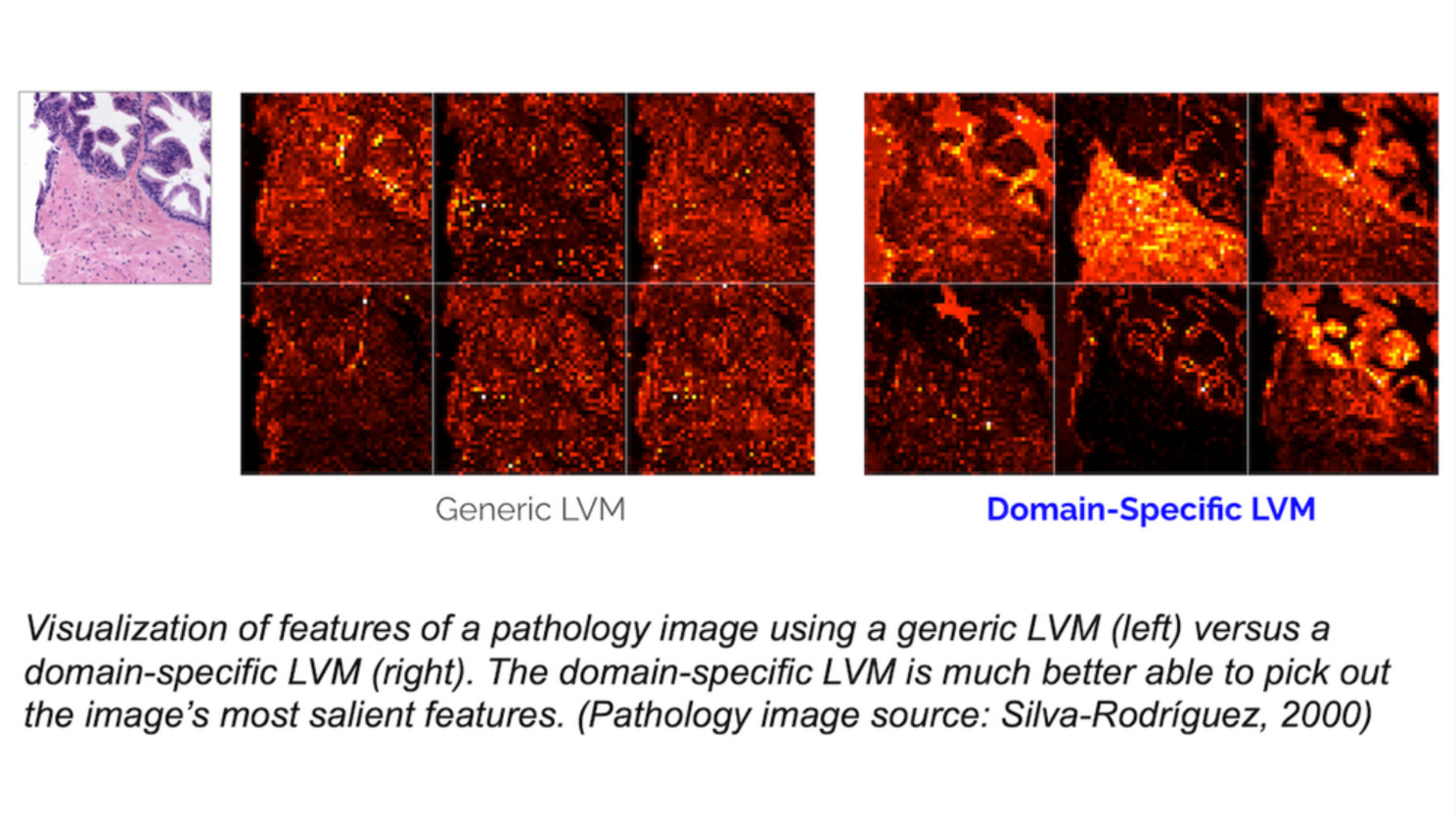
Domain-specific LVMs were created with around 100,000 unlabeled images from the specific domain, corroborating the idea that larger, more specialized datasets would lead to even better models.
Learn How to Use AI Image Generation Tools
Additionally, when used alongside a small labeled dataset to tackle a supervised learning task, a domain-specific LVM requires significantly less labeled data (around 10% to 30% as much) to achieve performance comparable to using a generic LVM.
Training Methods for Large Vision Models
The training methods being explored for domain-specific Large Vision Models involve, primarily, the use of extensive and diverse domain-specific image datasets.

There is also an increasing interest in using methods developed for Large Language Models and applying them within the visual domain, as with the sequential modeling approach introduced for learning an LVM without linguistic data.
Know more about 7 Best Large Language Models (LLMs)
Sequential Modeling Approach for Training LVMs
This approach adapts the way LLMs process sequences of text to the way LVMs handle visual data. Here’s a simplified explanation:

This approach adapts the way LLMs process sequences of text to the way LVMs handle visual data. Here’s a simplified explanation:
Breaking Down Images into Sequences
Just like sentences in a text are made up of a sequence of words, images can also be broken down into a sequence of smaller, meaningful pieces. These pieces could be patches of the image or specific features within the image.
Using a Visual Tokenizer
To convert the image into a sequence, a process called ‘visual tokenization’ is used. This is similar to how words are tokenized in text. The image is divided into several tokens, each representing a part of the image.

Training the Model
Once the images are converted into sequences of tokens, the LVM is trained using these sequences.
The training process involves the model learning to predict parts of the image, similar to how an LLM learns to predict the next word in a sentence.
This is usually done using a type of neural network known as a transformer, which is effective at handling sequences.
Understand Neural Networks and its applications
Learning from Context
Just like LLMs learn the context of words in a sentence, LVMs learn the context of different parts of an image. This helps the model understand how different parts of an image relate to each other, improving its ability to recognize patterns and details.
Applications
This approach can enhance an LVM’s ability to perform tasks like image classification, object detection, and even image generation, as it gets better at understanding and predicting visual elements and their relationships.
The Emerging Vision of Large Vision Models
Large Vision Models are advanced AI systems designed to process and understand visual data, such as images and videos. Unlike Large Language Models that deal with text, LVMs are adept at visual tasks like image classification, object detection, and image generation.
A key aspect of LVMs is domain specificity, where they are tailored to recognize and interpret images specific to certain fields, such as medical diagnostics or manufacturing. This specialization allows for more accurate performance compared to generic image processing.

Large Vision Models are trained using innovative methods, including the Sequential Modeling Approach, which enhances their ability to understand the context within images. As LVMs continue to evolve, they’re set to transform various industries, bridging the gap between human and machine visual perception.