

A vector database is a type of database that stores data as high-dimensional vectors. These vectors are mathematical representations of features or attributes, and they can be used to represent a wide variety of data, such as text, images, and audio.
One way to think about a vector database is to store and organize data similar to how the human brain stores and organizes memories. Our brain creates a vector representation of that information when we learn something new. This vector representation is then stored in our memory and can be used to retrieve the information later.

1. Redis

One of the things that makes Redis so special is its performance. It can handle millions of requests per second, making it ideal for real-time applications. On top of it, Redis can be easily deployed on a cluster of machines, making it a good choice for high-traffic applications.
If you’re looking for a fast, versatile, and scalable in-memory data structure store, then Redis is a great option.
Here are some specific examples of how Redis can be used:
Caching: Redis can be used to cache database queries, API calls, and other frequently accessed data. This can improve the performance of your applications by reducing the number of times they have to access the database.
Session storage: Redis can be used to store session data, such as user login information and shopping cart contents. This can improve the scalability of your applications by reducing the load on your database.
Real-time messaging: Redis can be used to implement real-time messaging applications, such as chat rooms and social media platforms. This can improve the responsiveness of your applications by allowing users to interact with each other in real time.
Streaming: Redis can be used to stream data, such as financial data or sensor data. This can be used to build real-time analytics applications or to create event-driven applications.
2. Milvus
is an open-source vector database that is designed for high-performance similarity search. It is based in the Faiss library and it can be used to store and search for large data sets of vectors. Milvus is used by companies such as Alibaba, Baidu, and Tencent.

3. Pinecone
It is a vector database that is designed for machine learning applications. It is fast, scalable, and supports a variety of machine learning algorithms. Pinecone is built on top of Faiss, a library for efficient similarity search of dense vectors. Pinecone is used by companies such as Google, Microsoft, and Uber.

4. Weaviate
It is an open-source vector database that is designed for storing and searching for linked data. It is based on the Elasticsearch search engine and it can be used to store and search for data that is linked together by relationships. Weaviate is used by companies such as Zalando and eBay.

5. Chroma
It is an AI-native open-source embedding database. It is designed for storing and searching for large datasets of embeddings. Chroma is used by companies such as Google, Amazon, and Facebook.

6. Faiss
is a library for efficient similarity search and clustering of dense vectors. It is not a vector database itself, but it can be used to build vector databases. Faiss is used by companies such as Google, Microsoft, and Amazon.

As you can see, vector databases are being used by a wide variety of companies for a variety of applications. They are a powerful tool for storing and managing unstructured data, and they are becoming increasingly popular as the amount of unstructured data continues to grow.
If you want to learn more about vector databases, click below:

The vector database pipeline
Vector databases are a type of database that is optimized for storing and searching high-dimensional vectors. They are used in a variety of AI applications, such as image search, natural language processing, and recommender systems.
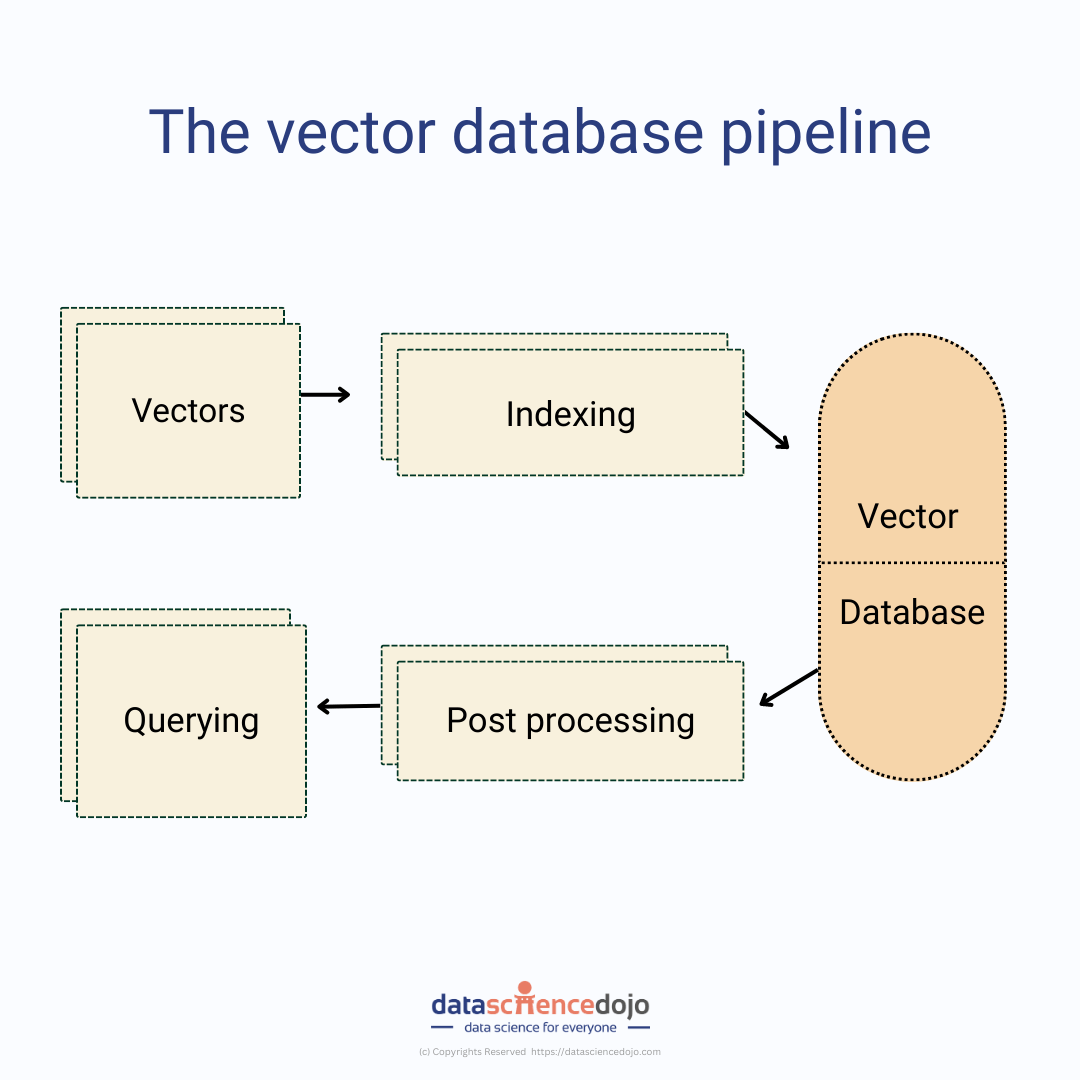
Indexing
The indexing step is responsible for mapping the vectors to a data structure that will enable faster searching. The data structure used will depend on the specific vector database and the application.
Some common indexing algorithms used in vector databases include:
- Product quantization (PQ): PQ is a technique for compressing vectors into a smaller representation that can be used for efficient search.
- Locality-sensitive hashing (LSH): LSH is a technique for finding similar vectors by hashing them into buckets.
- Hierarchical Navigable Small World (HNSW): HNSW is a graph-based algorithm for finding similar vectors.
Querying
The querying step is responsible for finding the nearest neighbors to a query vector. The nearest neighbors are the vectors that are most similar to the query vector.
The querying step typically uses the index created in the indexing step to find the nearest neighbors. The similarity metric used to measure the similarity between vectors will depend on the specific application.
Post-processing
The post-processing step is optional. It can be used to improve the results of the query by re-ranking the nearest neighbors. This can be done by using a different similarity metric or by applying other techniques, such as filtering or clustering.
The vector database pipeline is a key part of vector databases. It allows vector databases to efficiently search high-dimensional vectors. This makes them a powerful tool for a variety of AI applications.
How do vector databases work?
Vector databases work in a similar way. When data is stored in a vector database, it is first converted into a vector representation. This vector representation is then stored in the database and can be used to retrieve the data later.
Read about —> Large Language Models power and build your own ChatGPT (2023)
One of the advantages of vector databases is that they are very efficient at performing similarity searches. This means that they can be used to find the most similar data to a given piece of data very quickly. This makes them ideal for applications where it is important to find similar data, such as recommender systems, search engines, and fraud detection systems.
How to use vector database?
Here is an example of how a vector database could be used. Imagine that you have a vector database that stores information about books. Each book in the database is represented by a vector that contains information about the book’s title, author, genre, and other features.
If you want to find books that are similar to a particular book, you can simply search the vector database for books that have a similar vector representation. This will return a list of books that are similar to the book you are looking for.
Vector databases are a powerful tool for storing and managing unstructured data. They are particularly well-suited for applications where it is important to find similar data quickly.
Here are some other examples of how vector databases can be used:
- Searching for similar images
- Finding similar documents
- Recommending products to customers
- Detecting fraud
- Classifying text
- Translating languages
As you can see, vector databases have a wide range of potential applications. They are a powerful tool for storing and managing unstructured data, and they are becoming increasingly popular as the amount of unstructured data continues to grow.
Common features of vector databases
Vector databases are a type of database that is optimized for storing and searching high-dimensional vectors. They are used in a variety of AI applications, such as image search, natural language processing, and recommender systems.
Some of the common features of vector databases include:
- Vector similarity search: Vector databases support vector similarity search, which finds the k nearest vectors to a query vector, as measured by a similarity metric. This is useful for applications such as image search, where you want to find similar images to a query image.
- Vector compression: Vector databases use vector compression techniques to reduce the storage space and improve the query performance. This is important for large datasets, where storing the vectors in their original form would be too expensive.
- Nearest neighbor search: Vector databases can perform exact or approximate nearest neighbor search, depending on the trade-off between accuracy and speed. Exact nearest neighbor search provides perfect recall, but may be slow for large datasets. Approximate nearest neighbor search uses specialized data structures and algorithms to speed up the search, but may sacrifice some recall.
- Similarity metrics: Vector databases support different types of similarity metrics, such as L2 distance, inner product, and cosine distance. Different similarity metrics may suit different use cases and data types.
- Data sources: Vector databases can handle various types of data sources, such as text, images, audio, video, and more. Data sources can be transformed into vector embeddings using machine learning models, such as word embeddings, sentence embeddings, image embeddings, etc.
Choosing a vector Database
When choosing a vector database, it is important to consider your specific needs and requirements. Some factors to consider include:
- The type of data you will be storing and searching.
- The size of your dataset.
- The accuracy and speed requirements.
- The budget.
There are a number of vector databases available, so it is important to do your research and choose the one that is right for you.
What are vector embeddings?
Vector embeddings are a way of representing data as vectors. This means that each piece of data is represented as a point in a high-dimensional space. The dimensions of the space represent different features of the data.
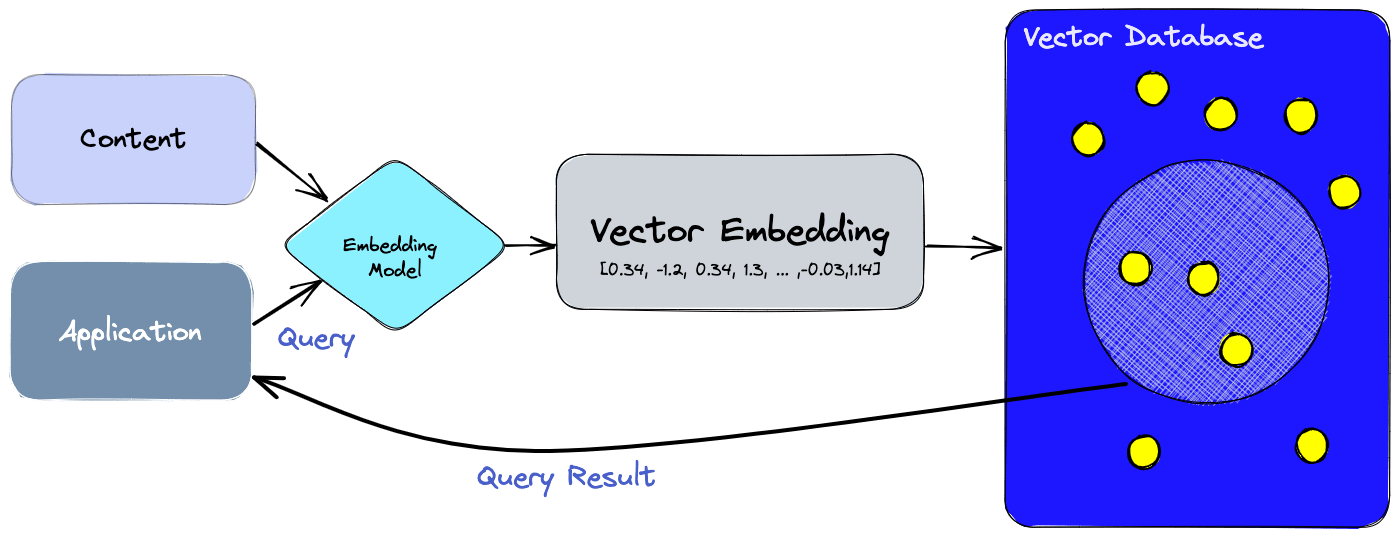
For example, if you are representing text data, the dimensions of the space might represent the presence or absence of different words in the text. The closer two vectors are in the space, the more similar the data they represent.
Where to use vector embeddings?
Here is an example of how vector embeddings can be used. Let’s say you have a dataset of images of cats and dogs. You can use a machine learning model to learn vector embeddings for each image. These vectors will represent the features of the image, such as the color, shape, and texture of the animal.
Once you have the vector embeddings, you can use them to do things like find similar images, classify images, and generate new images. For example, you could use the vector embeddings to find all the images of cats that are most similar to a given image.
Vector embeddings are a powerful tool for representing and manipulating data. They are used in a variety of AI applications, such as natural language processing, image recognition, and recommender systems.
Here are some other examples of vector embeddings:
- Word embeddings: Word embeddings are vector representations of words. They are used to represent the meaning of words in a way that can be understood by machines.
- Sentence embeddings: Sentence embeddings are vector representations of sentences. They are used to represent the meaning of sentences in a way that can be understood by machines.
- Image embeddings: Image embeddings are vector representations of images. They are used to represent the content of images in a way that can be understood by machines.
In a nutshell
Vector embeddings are becoming increasingly popular in fields such as natural language processing (NLP), computer vision, and other artificial intelligence (AI) applications. This has led to the emergence of vector databases, which are purpose-built databases that are specialized in managing vector embeddings.
Vector databases offer significant advantages over traditional scalar-based databases and standalone vector indexes. This is because they are designed to handle the specific challenges of working with vector embeddings, such as the high dimensionality of the data and the need for efficient search and retrieval.
In this post, we reviewed the key aspects of a vector database, including how it works, what algorithms it uses, and the additional features that make it operationally ready for production scenarios. We hope this helps you understand the inner workings of vector databases.