A hands-on guide to collect and store twitter data for timeseries analysis
“A couple of weeks back, I was working on a project in which I had to scrape tweets from twitter and after storing them in a csv file, I had to plot some graphs for timeseries analysis. I requested Twitter for Twitter developer API, but unfortunately my request was not fulfilled. Then I started searching for python libraries which can allow me to scrape tweets without the official Twitter API.
To my amazement, there were several libraries through which you can scrape tweets easily but for my project I found ‘Snscrape’ to be the best library, which met my requirements!”
What is SNScrape?
A scraper for social networking platforms known as snscrape (SNS). It retrieves objects, such as pertinent posts, by scraping things like user profiles, hashtags, or searches.
Install Snscrape
Snscrape requires Python 3.8 or higher. The Python package dependencies are installed automatically when you install Snscrape. You can install using the following commands.
For this tutorial we will be using the development version of Snscrape. Paste the second command in command prompt(cmd), make sure you have git installed on your system.
Code walkthrough for scraping
Before starting make sure you have the following python libraries:
Pandas
Numpy
Snscrape
Tqdm
Seaborn
Matplotlit
Importing Relevant Libraries
To run the scraping program, you will first need to import the libraries
import pandas as pdimport numpy as npimport snscrape.modules.twitter as sntwitterimport datetimefrom tqdm.notebook import tqdm_notebookimport seaborn as snsimport matplotlib.pyplot as pltsns.set_theme(style="whitegrid")
Taking User Input
To scrape tweets, you can provide many filters such as the username or start date or end date etc. We will be taking the following user inputs which will then be used in Snscrape.
Text: The query to be matched. (Optional)
Username: Specific username from twitter account. (Required)
Since: Start Date in this format yyyy-mm-dd. (Optional)
Until: End Date in this format yyyy-mm-dd. (Optional)
Count: Max number of tweets to retrieve. (Required)
Retweet: Include or Exclude Retweets. (Required)
Replies: Include or Exclude Replies. (Required)
For this tutorial we used the following inputs:
text = input('Enter query text to be matched (or leave it blank by pressing enter)')username = input('Enter specific username(s) from a twitter account without @ (or leave it blank by pressing enter): ')since = input('Enter startdate in this format yyyy-mm-dd (or leave it blank by pressing enter): ')until = input('Enter enddate in this format yyyy-mm-dd (or leave it blank by pressing enter): ')count = int(input('Enter max number of tweets or enter -1 to retrieve all possible tweets: '))retweet = input('Exclude Retweets? (y/n): ')replies = input('Exclude Replies? (y/n): ')
Which field can we Scrape?
Here is the list of fields which we can scrape using Snscrape Library.
For this tutorial we will not scrape all the fields but a few relevant fields from the above list.
The search function
Next, we will define a search function which takes in the following inputs as arguments and creates a query string to be passed inside SNS twitter search scraper function.
Here we have defined different conditions and based on those conditions we are creating the query string. For example, if variable until (end date) is empty then we are assigning it the current date and appending it in a query string and if the variable since (start date) is empty then we are assigning it a date of past 7 days from the current date. Along with the query string, we are creating filename string which will be used to name our csv file.
Calling the Search Function and creating Dataframe
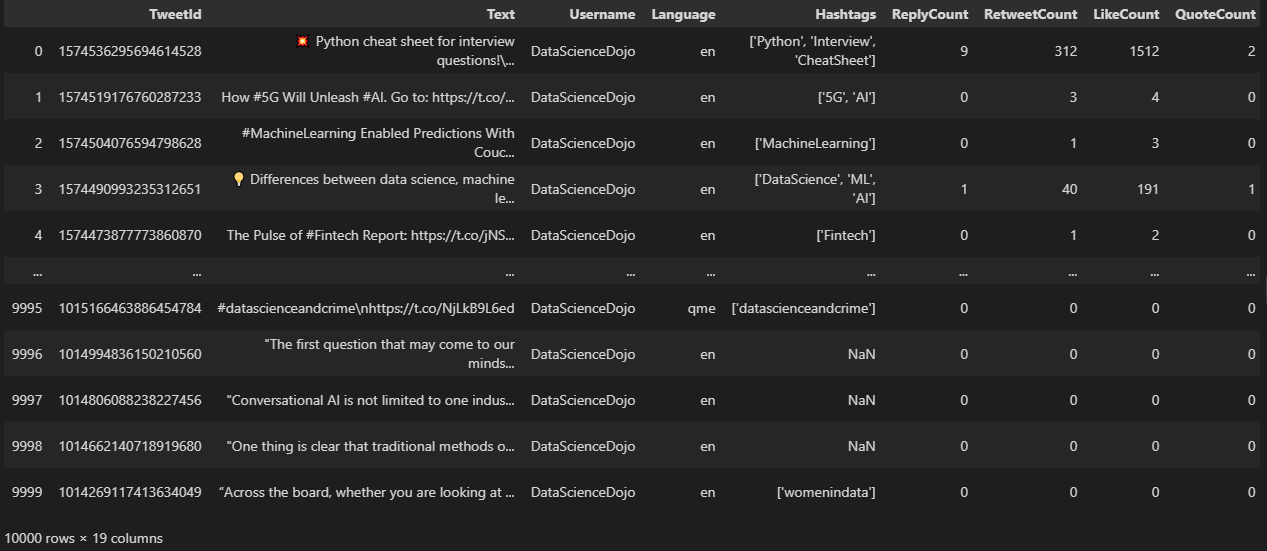
q = search(text,username,since,until,retweet,replies)# Creating list to append tweet data tweets_list1 = []# Using TwitterSearchScraper to scrape data and append tweets to listif count == -1:for i,tweet inenumerate(tqdm_notebook(sntwitter.TwitterSearchScraper(q).get_items())): tweets_list1.append([tweet.date, tweet.id, tweet.rawContent, tweet.user.username,tweet.lang, tweet.hashtags,tweet.replyCount,tweet.retweetCount, tweet.likeCount,tweet.quoteCount,tweet.media])else:with tqdm_notebook(total=count) as pbar:for i,tweet inenumerate(sntwitter.TwitterSearchScraper(q).get_items()): #declare a username if i>=count: #number of tweets you want to scrapebreak tweets_list1.append([tweet. Date, tweet.id, tweet.rawContent, tweet.user.username,tweet.lang,tweet.hashtags,tweet.replyCount, tweet.retweetCount,tweet.likeCount,tweet.quoteCount,tweet.media]) pbar.update(1)# Creating a dataframe from the tweets list above tweets_df1 = pd.DataFrame(tweets_list1, columns=['DateTime', 'TweetId', 'Text', 'Username','Language','Hashtags','ReplyCount','RetweetCount','LikeCount','QuoteCount','Media'])
In this snippet we have invoked the search function and the query string is stored inside variable ‘q’. Next, we have defined an empty list which will be used for appending tweet data. If the count is specified as -1 then the for loop will iterate over all the tweets.
TwitterSearchScraper class constructor takes the query string as an argument and then we invoke the get_items() method of TwitterSearchScraper class to retrieve all the tweets. Inside for loop we append scraped data in the tweets_list1 variable which we defined earlier. If count is defined, then we use it to break the for loop. Finally, using this list, we create the pandas dataframe by specifying the column names.
Finally our data is prepared, we will now save the dataframe as csv using df.to_csv() function which takes filename as an input parameter.
tweets_df1.to_csv(f"{filename}",index=False)
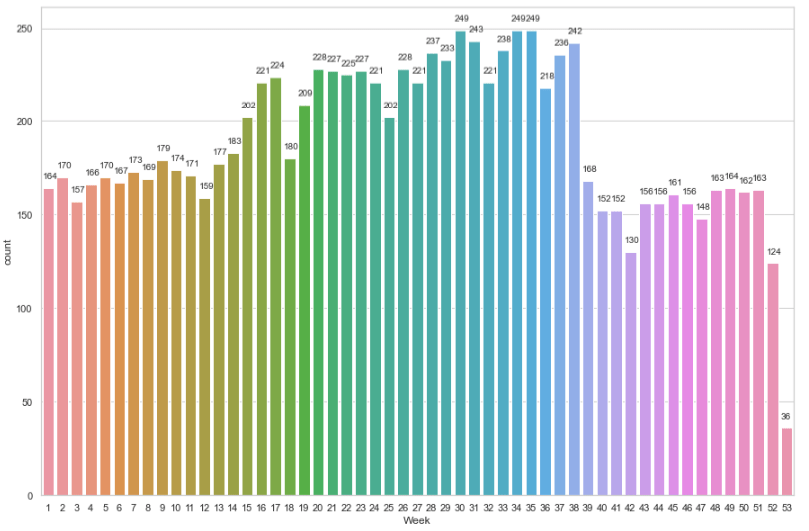
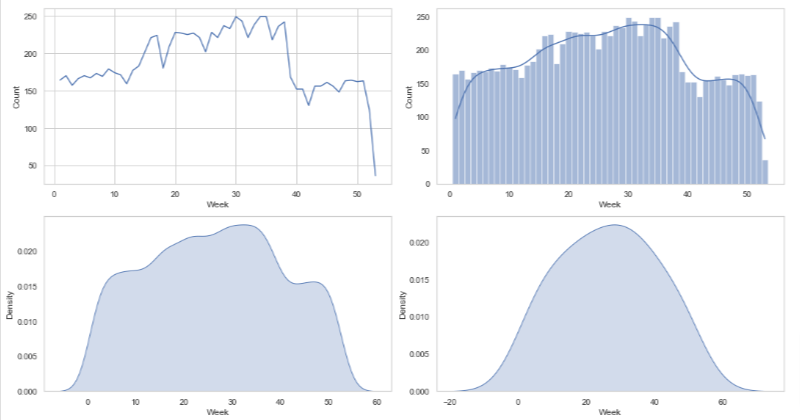
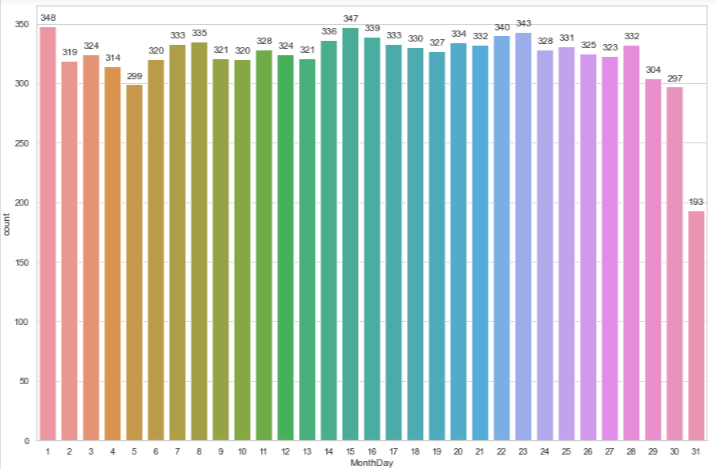
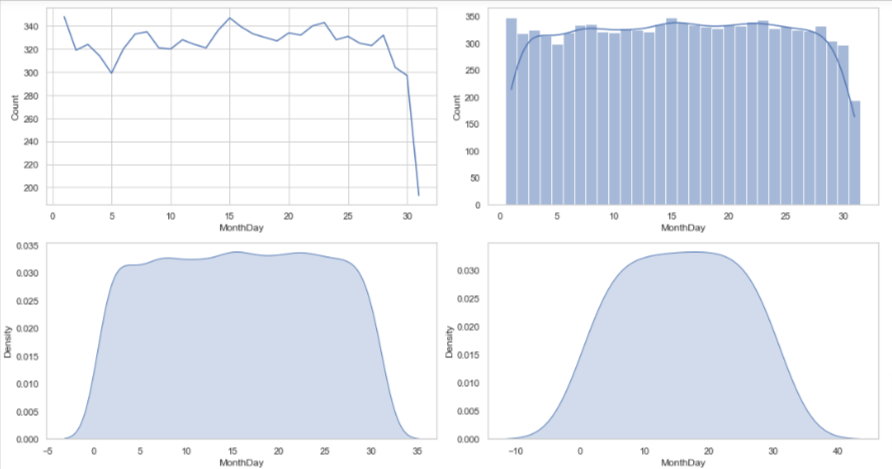
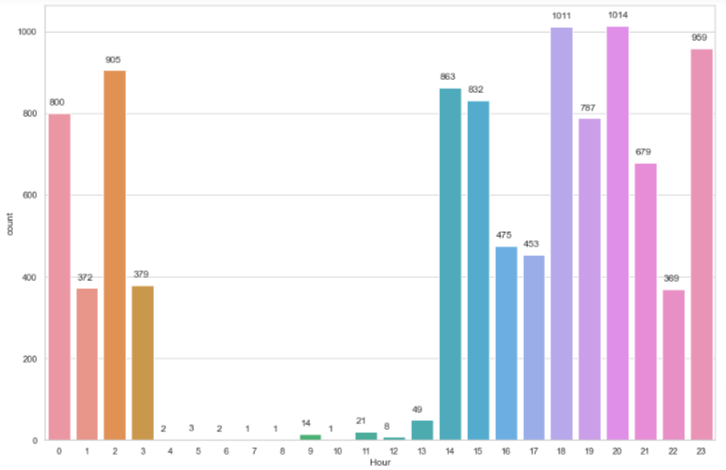
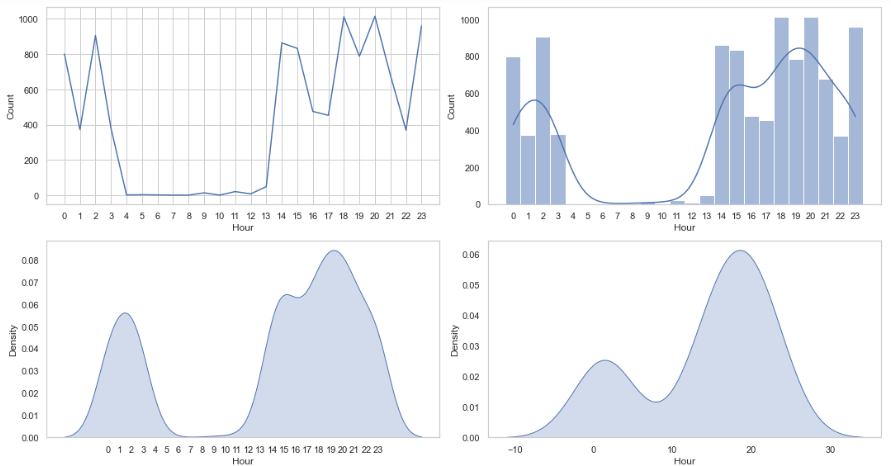
Visualizing timeseries data using barplot, lineplot, histplot and kdeplot
It is time to visualize our prepared data so that we can find useful insights. Firstly, we will load the saved csv in a dateframe using the read_csv() function of pandas which take filename as input parameter.
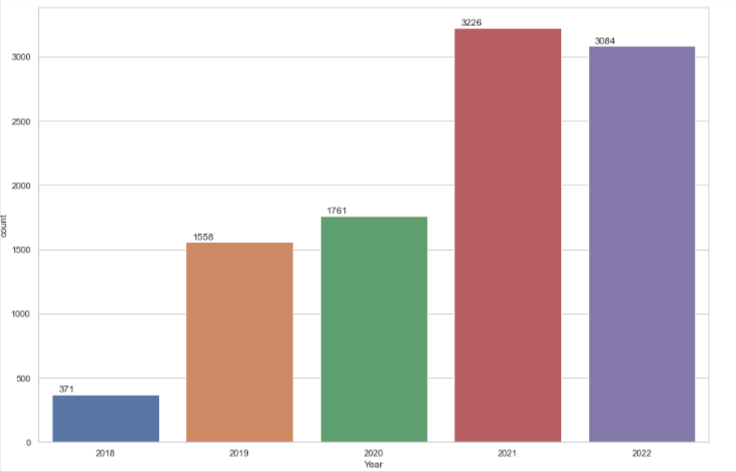
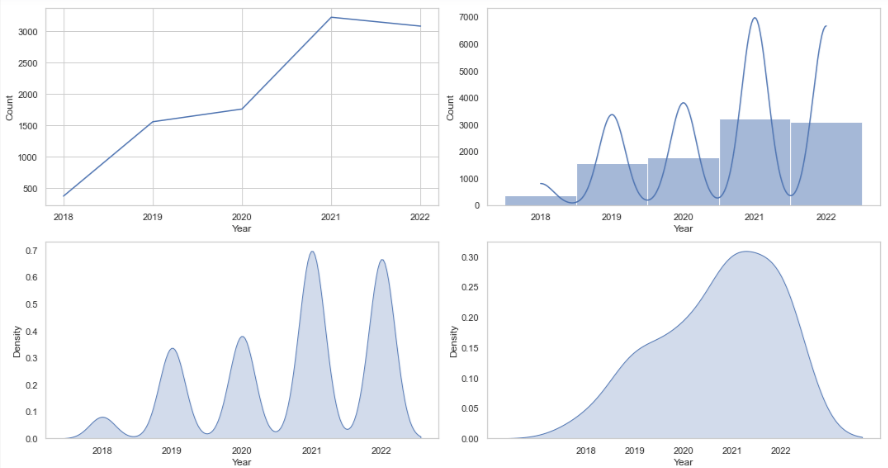
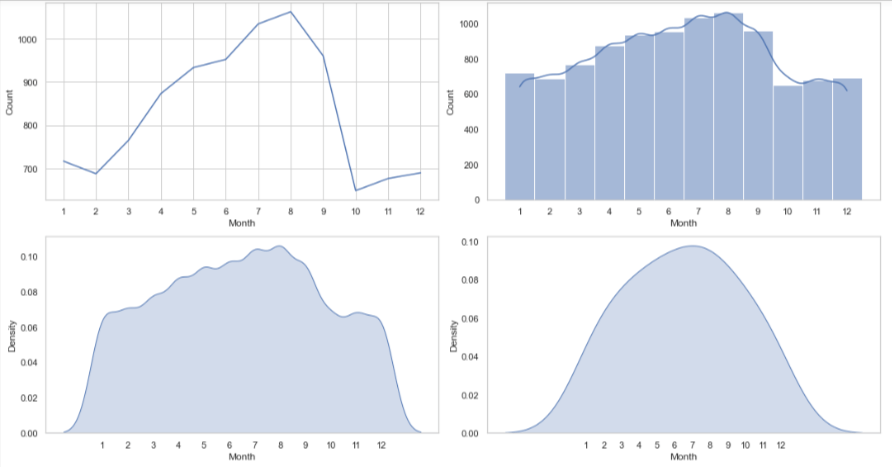
From the above time series visualizations, we can clearly understand that the peak hours of tweets from this account is between 7pm-9pm and from 4am -1pm the twitter handle is quiet. We can also point out that most of the tweets related to that topic are done in the month of August. Similarly, we can identify that the Twitter handle was not very active before 2021.
Conclusively, we saw how we can easily scrape tweets without using Twitter API through Snscrape. Then we performed some transformations on the scraped data and stored it in csv file. Later, we used that csv file for time-series visualizations and analysis. We appreciate you following along with this hands-on guide. We hope that this guide will make it easy for you to get started on your upcoming data science project.