

Multimodality refers to an AI model’s ability to understand, process, and generate multiple types of information, such as text, images, and potentially even sounds. It’s the capacity to interpret and interact with various data forms, where the model not only reads textual information but also comprehends visual or other types of data.
In this blog we will explore multimodality in LLMs through GPT 4 Vision use cases for better understanding.
How Does Multimodality Increase the Power of LLMs?
The significance of multimodality lies in its potential to greatly enhance the effectiveness and applications of AI models.
Consider the human intellect and its capacity to comprehend the world and tackle unique challenges. This ability stems from processing diverse forms of information, including language, sight, and taste, among others.
If an individual lacks access to one of these sensory inputs from the outset, such as vision, their understanding of the real world is likely to be significantly impaired.
Hence, multimodality in models, like GPT-4, allows them to develop intuition and understand complex relationships not just inside single modalities but across them, mimicking human-level cognizance to a higher degree.
Read about: GPT 3.5 VS GPT 4
Here are a few examples where we see that GPT 4 Vision is capable of performing human-like tasks:
Example 1: GPT 4 Vision and Understanding Humor

Source: OpenAI
Example 2: GPT 4 Vision Acing Complex Exams
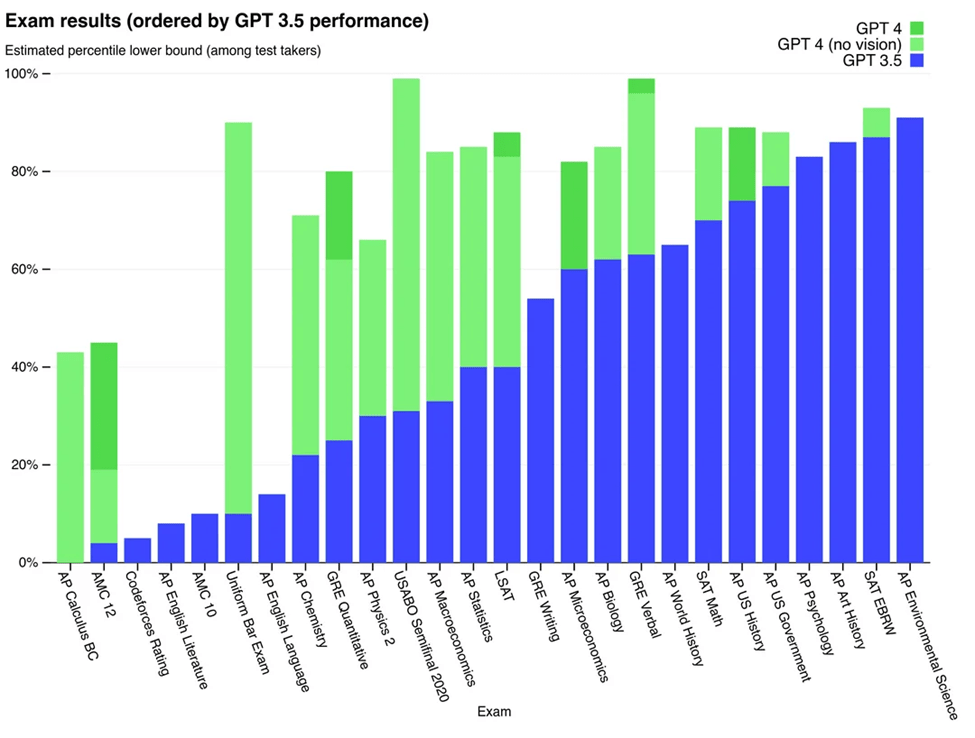
Why does vision help GPT-4 do better on tests? Well, think about it like this: you’d probably get more out of an exam if it’s written down for you to see, rather than just hearing it from someone, right?
Also understand the AI technology behind ChatGPT
It’s the same deal with a model like the GPT-4. Having that visual element just makes things a bit clearer and easier to work with.
Hence, multimodal learning opens up newer opportunities, helps AI handle real-world data more efficiently, and brings us closer to developing AI models that act and think more like humans.

How does the GPT 4 Vision Model Combine Text and Image Inputs?
GPT-4 with Vision combines natural language processing capabilities with computer vision. This means it can accept different forms of input, like text and images, and deliver outputs based on that mixture of information.
This model represents a significant advance in machine learning and natural language processing, as it bridges two traditionally separate fields: computer vision and natural language processing.
Enabling models to understand different types of data enhances their performance and expands their application scope. For instance, in the real-world, they may be used for Visual Question Answering (VQA), wherein the model is given an image and a text query about the image, and it needs to provide a suitable answer.
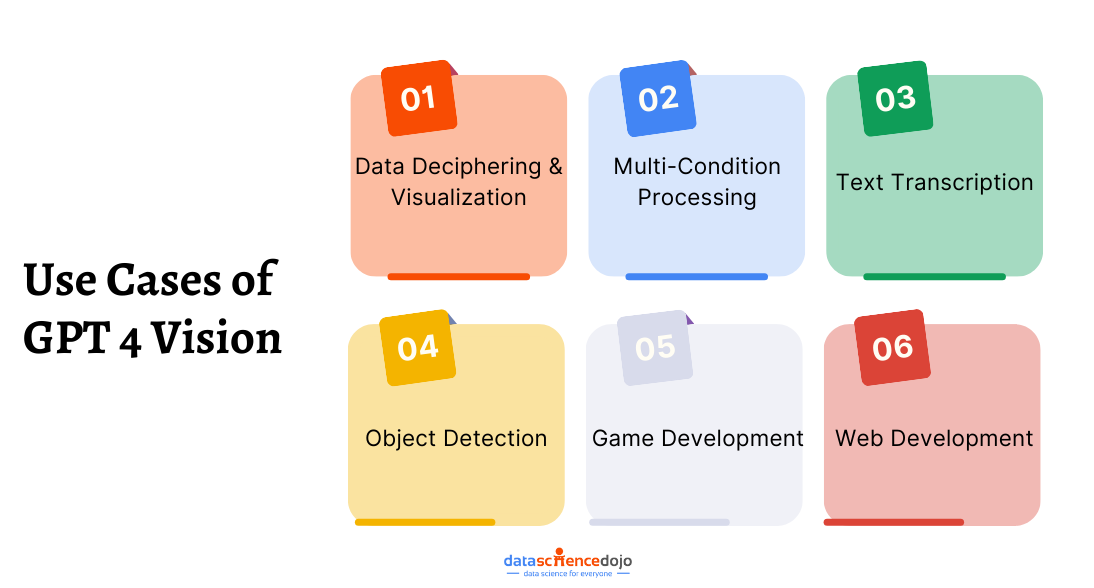
Use Cases of GPT 4 Vision
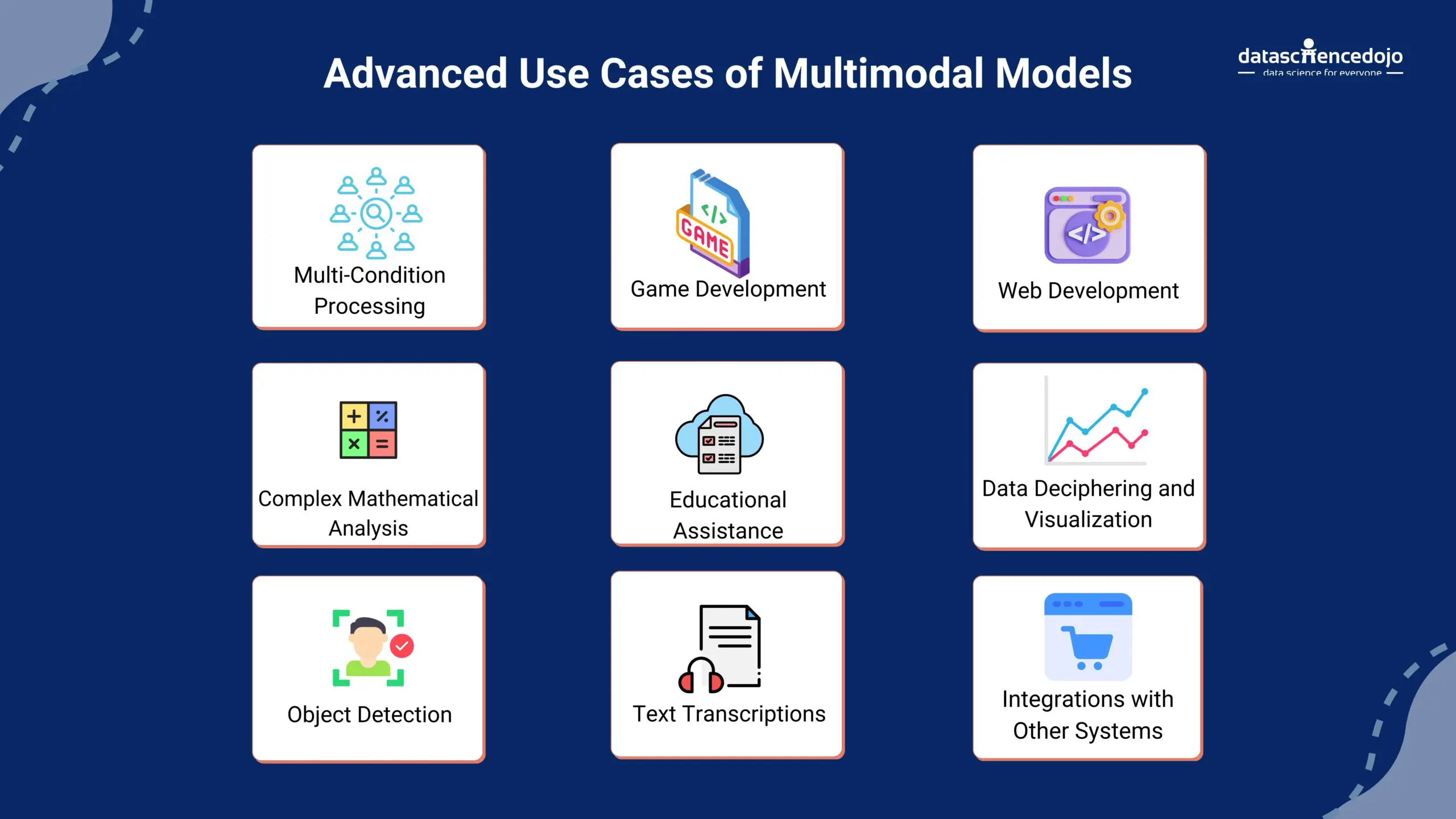
GPT-4V can perform a variety of tasks, including data deciphering, multi-condition processing, text transcription from images, object detection, coding enhancement, design understanding, and more. Here are some mind-boggling use cases of GPT-4 Vision. Of course, as time progresses, its usability will keep increasing.
Data Deciphering and Visualization
GPT-4V is capable of processing infographics or charts and providing detailed breakdowns of the data presented. This means that complex visual data can be transformed into understandable insights, making it easier for users to comprehend complex information. Here’s an example:
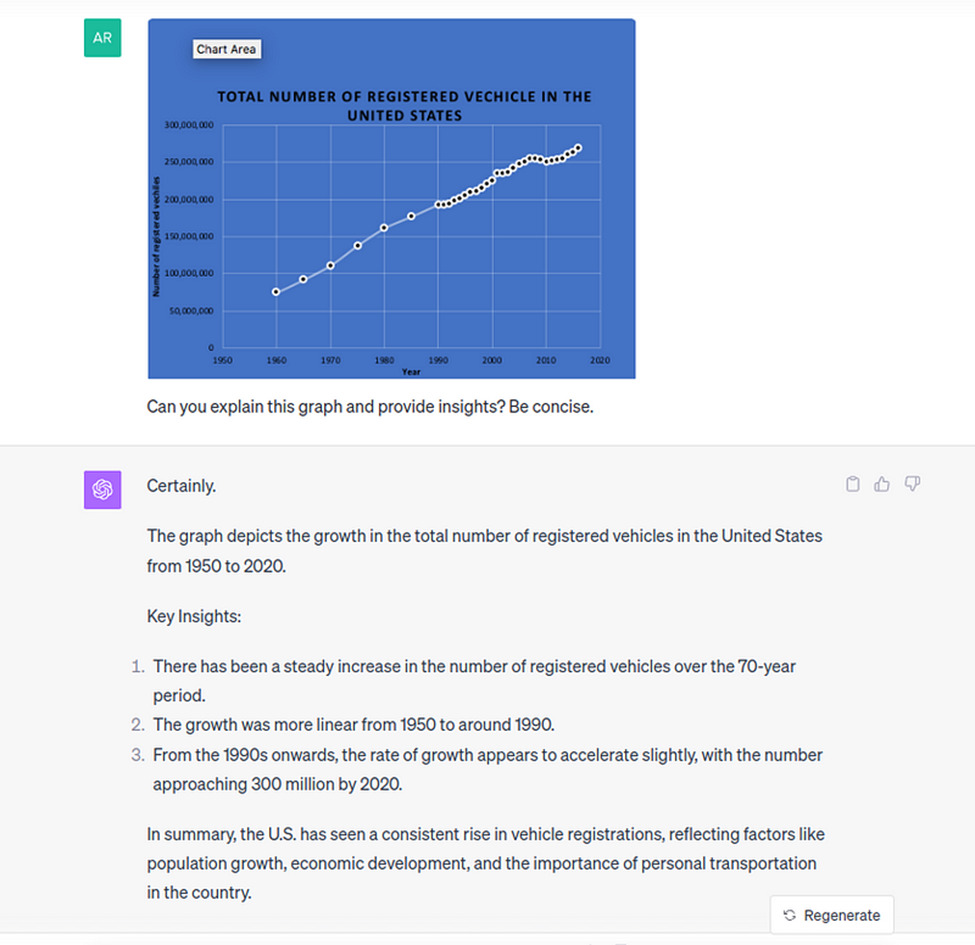
Source: Datacamp
Conversely, the technology demonstrates proficiency in interpreting the provided data and generating impactful visual representations. Here’s an example where GPT-4 successfully processed LATEX code to produce a Python plot.
Also explore the evolution of GPT series
This was achieved through interactive dialogue with the user. In this scenario, the model accurately extracted the necessary data and efficiently addressed all user queries. It adeptly reformatted the data and tailored the visualization to meet the specified requirements.
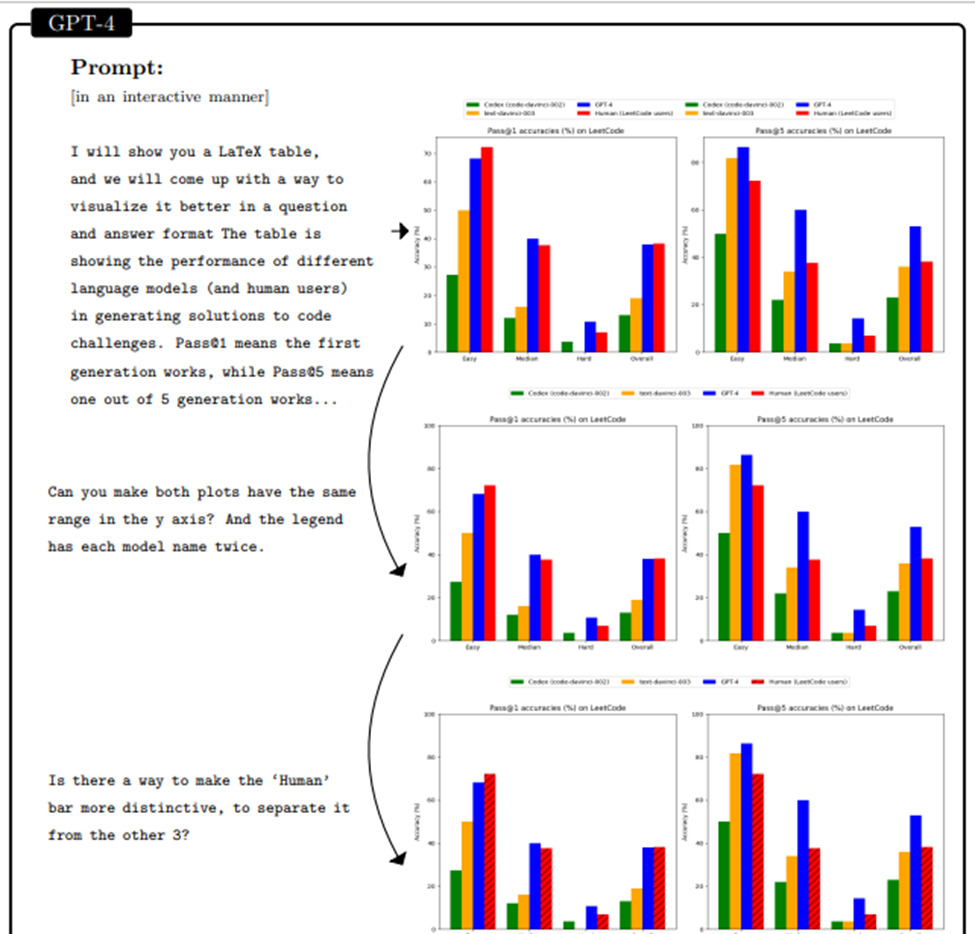
Source: Sparks of Artificial General Intelligence: Early experiments with GPT-4 | Microsoft
Multi-Condition Processing
GPT-4V is excellent at analyzing images under varying conditions, such as different lighting or complex scenes, and can provide insightful details drawn from these varying contexts.
Source: roboflow
Text Transcription
The model is geared to transcribe text from images. It could be a game-changer in digitizing written or printed documents by converting images of text into a digital format.

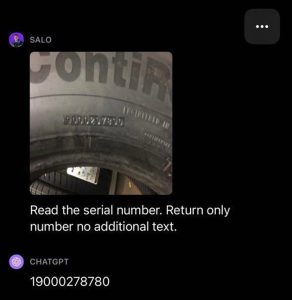
Object Detection
GPT-4V has superior object detection capabilities. It can accurately identify different objects within an image, even abstract ones, providing a comprehensive analysis and comprehension of images.
Source: roboflow
Game Development
GPT-4V can significantly impact the gaming industry as well. Here an example where it was provided with a comprehensive overview of a 3D game. GPT-4 demonstrated its capability to develop a functional game using HTML and JavaScript. This is accomplished without prior training or experience in related projects.

Source: Sparks of Artificial General Intelligence: Early experiments with GPT-4 | Microsoft
Web Development
GPT-4 Vision significantly enhances web development by enabling the creation of websites from visual inputs like sketches. It interprets design elements and transforms them into functional HTML, CSS, and JavaScript code, including interactive features and specific themes, such as a ’90s hacker style with dynamic effects. Here’s an example where GPT-4 was prompted to write code for a website by only providing it a hand-drawn sketch:
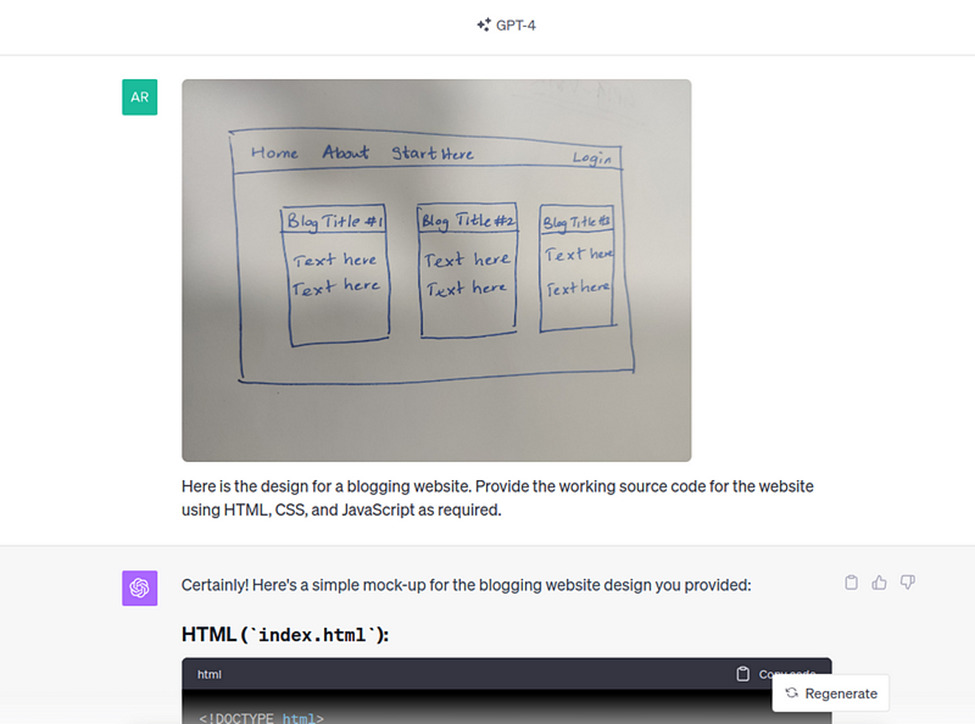
Once the HTML and CSS files were created as instructed, this was the result:
Source: Datacamp
This advancement streamlines the web development process, making it more accessible and efficient, particularly for those with limited coding knowledge. It opens up new possibilities for creative design and can be applied across various domains, potentially evolving with continuous learning and improvement.

Complex Mathematical Analysis: GPT-4V can process and analyze intricate mathematical expressions, especially when they are represented graphically or in handwritten forms.
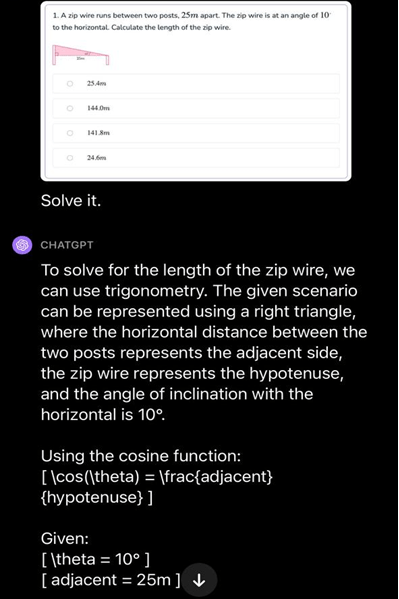
Source: roboflow
Integrations with Other Systems
GPT-4 can be integrated with other systems through its API, expanding its application sphere to diverse domains like security, healthcare diagnostics, and entertainment.
Educational Assistance
GPT-4V can help in the educational sector by analyzing diagrams, illustrations, and visual aids, and transforming them into detailed textual explanations, making concepts easier to comprehend for students and educators alike.
The innovation of incorporating visual capabilities, therefore, offers a dynamic and engaging method for users to interact with AI systems.
Where Does GPT 4 Vision Perform Less Effectively?
While the GPT-4 Vision is groundbreaking, it is important to recognize its limitations and risks.
- Privacy Concerns: GPT-4 Vision’s ability to identify individuals and locations in images raises serious privacy issues. This poses a challenge for companies to balance innovation with adherence to privacy laws and ethical practices.
- Bias in Image Analysis: The risk of biases in image interpretation could lead to unfair or discriminatory outcomes, particularly affecting diverse demographic groups. This necessitates careful oversight and continuous improvement of the AI’s algorithms to minimize biases.
- Unreliable Medical Advice or Dangerous Instructions: The model might inadvertently provide inaccurate medical advice or instructions for potentially hazardous tasks. This limitation is significant, especially in contexts where precise and reliable information is critical for safety and health.
Master ChatGPT cheat sheet with examples
- Cybersecurity Vulnerabilities: GPT-4 Vision could be exploited for tasks like solving CAPTCHAs, posing cybersecurity risks. This highlights the need for robust security measures to prevent malicious use.
- Content Accuracy and Hallucination: The model, like other AI systems, can sometimes generate content that is not factually correct or based in reality, known as ‘hallucinations’. Users must be vigilant and verify the information provided by the AI.
- Refusal to Analyze Certain Images: In some cases, GPT-4 Vision might refuse to analyze images, particularly those involving people, due to the sensitive nature of such data. This limitation can be viewed as a measure to prevent misuse or ethical breaches, but it also restricts the model’s functionality in certain scenarios.
- Overall, these risks and limitations highlight the importance of cautious and responsible deployment of GPT-4 Vision, ensuring that its use aligns with ethical standards and societal norms.
Conclusion
GPT-4 Vision represents a monumental leap in AI technology, merging text and image processing to offer unprecedented capabilities. Its potential in fields like web development, content creation, and data analysis is immense.
However, this technology comes with responsibilities. The potential risks, including privacy concerns, biases, and safety issues, underscore the importance of using GPT-4 Vision with a mindful approach.
As we harness this powerful tool, it’s crucial to continuously evaluate and address these challenges to ensure ethical and responsible usage of AI.
