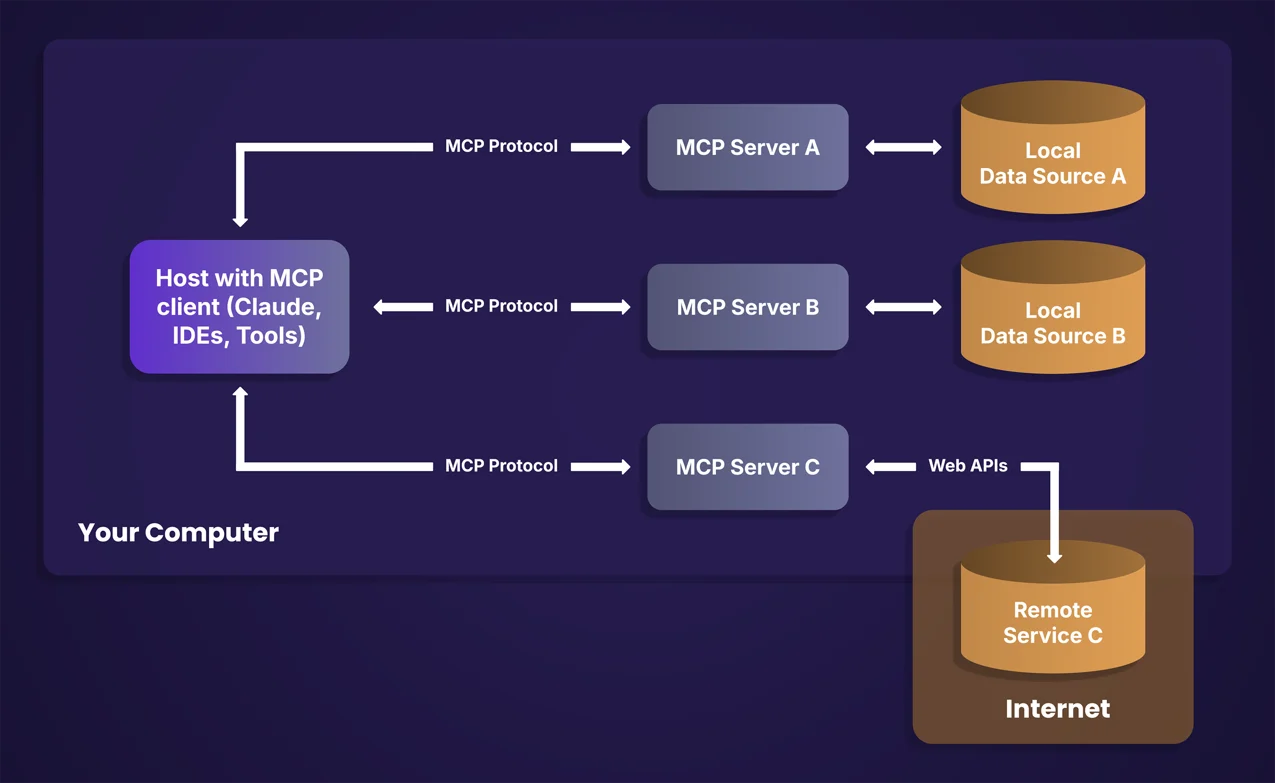
The Model Context Protocol (MCP) is rapidly becoming the “USB-C for AI applications,” enabling large language models (LLMs) and agentic AI systems to interact with external tools, databases, and APIs through a standardized interface. MCP’s promise is seamless integration and operational efficiency, but this convenience introduces a new wave of MCP security risks that traditional controls struggle to address.
As MCP adoption accelerates in enterprise environments, organizations face threats ranging from prompt injection and tool poisoning to token theft and supply chain vulnerabilities. According to recent research, hundreds of MCP servers are publicly exposed, with 492 identified as vulnerable to abuse, lacking basic authentication or encryption. This blog explores the key risks, real-world incidents, and actionable strategies for strengthening MCP security in deployments.
Prompt injection is the most notorious attack vector in MCP environments. Malicious actors craft inputs, either directly from users or via compromised external data sources, that manipulate model behavior, causing it to reveal secrets, perform unauthorized actions, or follow attacker-crafted workflows. Indirect prompt injection, where hidden instructions are embedded in external content (docs, webpages, or tool outputs) is especially dangerous for agentic AI running in containers or orchestrated environments (e.g., Docker).
How the Attack Works:
An MCP client or agent ingests external content (a README, a scraped webpage, or third-party dataset) as part of its contextual prompt.
The attacker embeds covert instructions or specially-crafted tokens in that conten.
The model or agent, lacking strict input sanitization and instruction-scoping, interprets the embedded instructions as authoritative and executes an action (e.g., disclose environment variables, call an API, or invoke local tools).
In agentic setups, the injected prompt can trigger multi-step behaviors—calling tools, writing files, or issuing system commands inside a containerized runtime.
Impact:
Sensitive data exfiltration: environment variables, API keys, and private files can be leaked.
Unauthorized actions: agents may push commits, send messages, or call billing APIs on behalf of the attacker.
Persistent compromise: injected instructions can seed future prompts or logs, creating a repeating attack vector.
High-risk for automated pipelines and Dockerized agentic systems where prompts are consumed programmatically and without human review.
2. Tool Poisoning in MCP
Tool poisoning exploits the implicit trust AI agents place in MCP tool metadata and descriptors. Attackers craft or compromise tool manifests, descriptions, or parameter schemas so the agent runs harmful commands or flows that look like legitimate tool behavior, making malicious actions hard to detect until significant damage has occurred.
How the Attack Works:
An attacker publishes a seemingly useful tool or tampers with an existing tool’s metadata (name, description, parameter hints, example usage) in a registry or on an MCP server.
The poisoned metadata contains deceptive guidance or hidden parameter defaults that instruct the agent to perform unsafe operations (for example, a “cleanup” tool whose example uses rm -rf /tmp/* or a parameter that accepts shell templates).
An agent loads the tool metadata and, trusting the metadata for safe usage and parameter construction, calls the tool with attacker-influenced arguments or templates.
The tool executes the harmful action (data deletion, command execution, exfiltration) within the agent’s environment or services the agent can access.
Impact:
Direct execution of malicious commands in developer or CI/CD environments.
Supply-chain compromise: poisoned tools propagate across projects that import them, multiplying exposure.
Stealthy persistence: metadata changes are low-profile and may evade standard code reviews (appearing as harmless doc edits).
Operational damage: data loss, compromised credentials, or unauthorized service access—especially dangerous when tools are granted elevated permissions or run in shared/Dockerized environments.
OAuth is a widely used protocol for secure authorization, but in the MCP ecosystem, insecure OAuth endpoints have become a prime target for attackers. The critical vulnerability CVE-2025-6514 exposed how MCP clients especially those using the popular mcp-remote OAuth proxy could be compromised through crafted OAuth metadata.
How the Attack Works:
MCP clients connect to remote MCP servers via OAuth for authentication.
The mcp-remote proxy blindly trusts server-provided OAuth endpoints.
A malicious server responds with an authorization_endpoint containing shell command injection
The proxy passes this endpoint directly to the system shell, executing arbitrary commands with the user’s privileges.
Impact:
Over 437,000 developer environments were compromised (CVE-2025-6514).
Attackers gained access to environment variables, credentials, and internal repositories.
Remote Code Execution (RCE) Threats in MCP
Remote Code Execution (RCE) is one of the most severe threats in MCP deployments. Attackers exploit insecure authentication flows, often via OAuth endpoints, to inject and execute arbitrary commands on host machines. This transforms trusted client–server interactions into full environment compromises.
How the Attack Works:
An MCP client (e.g., Claude Desktop, VS Code with MCP integration) connects to a remote server using OAuth.
The malicious server returns a crafted authorization_endpoint or metadata field containing embedded shell commands.
The MCP proxy or client executes this field without sanitization, running arbitrary code with the user’s privileges.
The attacker gains full code execution capabilities, allowing persistence, credential theft, and malware installation.
Impact:
Documented in CVE-2025-6514, the first large-scale RCE attack on MCP clients.
Attackers were able to dump credentials, modify source files, and plant backdoors.
Loss of developer environment integrity and exposure of internal code repositories.
Potential lateral movement across enterprise networks.
4. Supply Chain Attacks via MCP Packages
Supply chain attacks exploit the trust developers place in widely adopted open-source packages. With MCP rapidly gaining traction, its ecosystem of tools and servers has become a high-value target for attackers. A single compromised package can cascade into hundreds of thousands of developer environments.
How the Attack Works:
Attackers publish a malicious MCP package (or compromise an existing popular one like mcp-remote).
Developers install or update the package, assuming it is safe due to its popularity and documentation references (Cloudflare, Hugging Face, Auth0).
The malicious version executes hidden payloads—injecting backdoors, leaking environment variables, or silently exfiltrating sensitive data.
Because these packages are reused across many projects, the attack spreads downstream to all dependent environments.
Impact:
mcp-remote has been downloaded over 437,000 times, creating massive attack surface exposure.
A single compromised update can introduce RCE vulnerabilities or data exfiltration pipelines.
Widespread propagation across enterprise and individual developer setups.
Long-term supply chain risk: backdoored packages remain persistent until discovered.
6. Insecure Server Configurations in MCP
Server configuration plays a critical role in MCP security. Misconfigurations—such as relying on unencrypted HTTP endpoints or permitting raw shell command execution in proxies—dramatically increase attack surface.
How the Attack Works:
Plaintext HTTP endpoints expose OAuth tokens, credentials, and sensitive metadata to interception, allowing man-in-the-middle (MITM) attackers to hijack authentication flows.
Shell-executing proxies (common in early MCP implementations) take server-provided metadata and pass it directly to the host shell.
A malicious server embeds payloads in metadata, which the proxy executes without validation.
The attacker gains arbitrary command execution with the same privileges as the MCP process.
Impact:
Exposure of tokens and credentials through MITM interception.
Direct RCE from maliciously crafted metadata in server responses.
Privilege escalation risks if MCP proxies run with elevated permissions.
Widespread compromise when developers unknowingly rely on misconfigured servers.
Anthropic’s reference SQLite MCP server was designed as a lightweight bridge between AI agents and structured data. However, it suffered from a classic SQL injection vulnerability: user input was directly concatenated into SQL statements without sanitization or parameterization. This flaw was inherited by thousands of downstream forks and deployments, many of which were used in production environments despite warnings that the code was for demonstration only.
Attack Vectors:
Attackers could submit support tickets or other user-generated content containing malicious SQL statements. These inputs would be stored in the database and later retrieved by AI agents during triage. The vulnerability enabled “stored prompt injection”, akin to stored XSS, where the malicious prompt was saved in the database and executed by the AI agent when processing open tickets. This allowed attackers to escalate privileges, exfiltrate data, or trigger unauthorized tool calls (e.g., sending sensitive files via email).
Impact on Organizations:
Thousands of AI agents using vulnerable forks were exposed to prompt injection and privilege escalation.
Attackers could automate data theft, lateral movement, and workflow hijacking.
No official patch was planned; organizations had to manually fix their own deployments or migrate to secure forks.
Lessons Learned:
Classic input sanitization bugs can cascade into agentic AI environments, threatening MCP security.
Always use parameterized queries and whitelist table names.
Restrict tool access and require human approval for destructive operations.
Monitor for anomalous prompts and outbound traffic.
Case 2: Enterprise Data Exposure (Asana MCP Integration)
Technical Background:
Asana’s MCP integration was designed to allow AI agents to interact with project management data across multiple tenants. However, a multi-tenant access control failure occurred due to shared infrastructure and improper token isolation. This meant that tokens or session data were not adequately segregated between customers.
Attack Vectors:
A flaw in the MCP server’s handling of authentication and session management allowed one customer’s AI agent to access another customer’s data. This could happen through misrouted API calls, shared session tokens, or insufficient validation of tenant boundaries.
Impact on Organizations:
Sensitive project and user data was exposed across organizational boundaries.
The breach undermined trust in Asana’s AI integrations and prompted urgent remediation.
Regulatory and reputational risks increased due to cross-tenant data leakage.
Lessons Learned:
Strict data segregation and token isolation are foundational for MCP security in multi-tenant deployments.
Regular audits and automated tenant-boundary tests must be mandatory.
Incident response plans should include rapid containment and customer notifications.
Case 3: Living Off AI Attack (Atlassian Jira Service Management MCP)
Technical Background:
Atlassian’s Jira Service Management integrated MCP to automate support workflows using AI agents. These agents had privileged access to backend tools, including ticket management, notifications, and data retrieval. The integration, however, did not adequately bound permissions or audit agent actions.
Attack Vectors:
Attackers exploited prompt injection by submitting poisoned support tickets containing hidden instructions. When the AI agent processed these tickets, it executed unauthorized actions—such as escalating privileges, accessing confidential data, or triggering destructive workflows. The attack leveraged the agent’s trusted access to backend tools, bypassing traditional security controls.
Impact on Organizations:
Unauthorized actions were executed by AI agents, including data leaks and workflow manipulation.
The attack demonstrated the risk of “living off AI”—where attackers use legitimate agentic workflows for malicious purposes.
Lack of audit logs and bounded permissions made incident investigation and containment difficult.
Lessons Learned:
Always bound agent permissions and restrict tool access to the bare minimum.
Implement comprehensive audit logging for all agent actions to strengthen MCP security.
Require human-in-the-loop approval for high-risk operations.
Continuously test agent workflows for prompt injection and privilege escalation.
Strategies for Strengthening MCP Security
Enforce Secure Defaults
Require authentication for all MCP servers.
Bind servers to localhost by default to avoid public network exposure.
Principle of Least Privilege
Scope OAuth tokens to the minimum necessary permissions.
Regularly audit and rotate credentials to maintain strong MCP security.
Supply Chain Hardening
Maintain an internal registry of vetted MCP servers.
Use automated scanning tools to detect vulnerabilities in third-party servers and enhance overall MCP security posture.
Input Validation and Prompt Shields
Sanitize all AI inputs and tool metadata.
Implement AI prompt shields to detect and filter malicious instructions before they compromise MCP security.
Audit Logging and Traceability
Log all tool calls, inputs, outputs, and user approvals.
Monitor outbound traffic for anomalies to catch early signs of MCP exploitation.
Sandboxing and Zero Trust
Run MCP servers with minimal permissions in isolated containers.
Adopt zero trust principles, verifying identity and permissions for every tool call, critical for long-term MCP security.
Human-in-the$-Loop Controls
Require manual approval for high-risk operations.
Batch low-risk approvals to avoid consent fatigue while maintaining security oversight.
Future of MCP Security
The next generation of MCP and agentic protocols will be built on zero trust, granular permissioning, and automated sandboxing. Expect stronger identity models, integrated audit hooks, and policy-driven governance layers. As the ecosystem matures, certified secure MCP server implementations and community-driven standards will become the foundation of MCP security best practices.
Organizations must continuously educate teams, update policies, and participate in community efforts to strengthen MCP security. By treating AI agents as junior employees with root access, granting only necessary permissions and monitoring actions, enterprises can harness MCP’s power without opening the door to chaos.
MCP security refers to the practices and controls that protect Model Context Protocol deployments from risks such as prompt injection, tool poisoning, token theft, and supply chain attacks.
Q2: How can organizations prevent prompt injection in MCP?
Implement input validation, AI prompt shields, and continuous monitoring of external content and tool metadata.
Q3: Why is audit logging important for MCP?
Audit logs enable traceability, incident investigation, and compliance with regulations, helping organizations understand agent actions and respond to breaches.
Q4: What are the best practices for MCP supply chain security?
Maintain internal registries of vetted servers, use automated vulnerability scanning, and avoid installing MCP servers from untrusted sources.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.