

In this blog, we will discuss the top 8 Machine Learning algorithms that will help you to receive and analyze input data to predict output values within an acceptable range
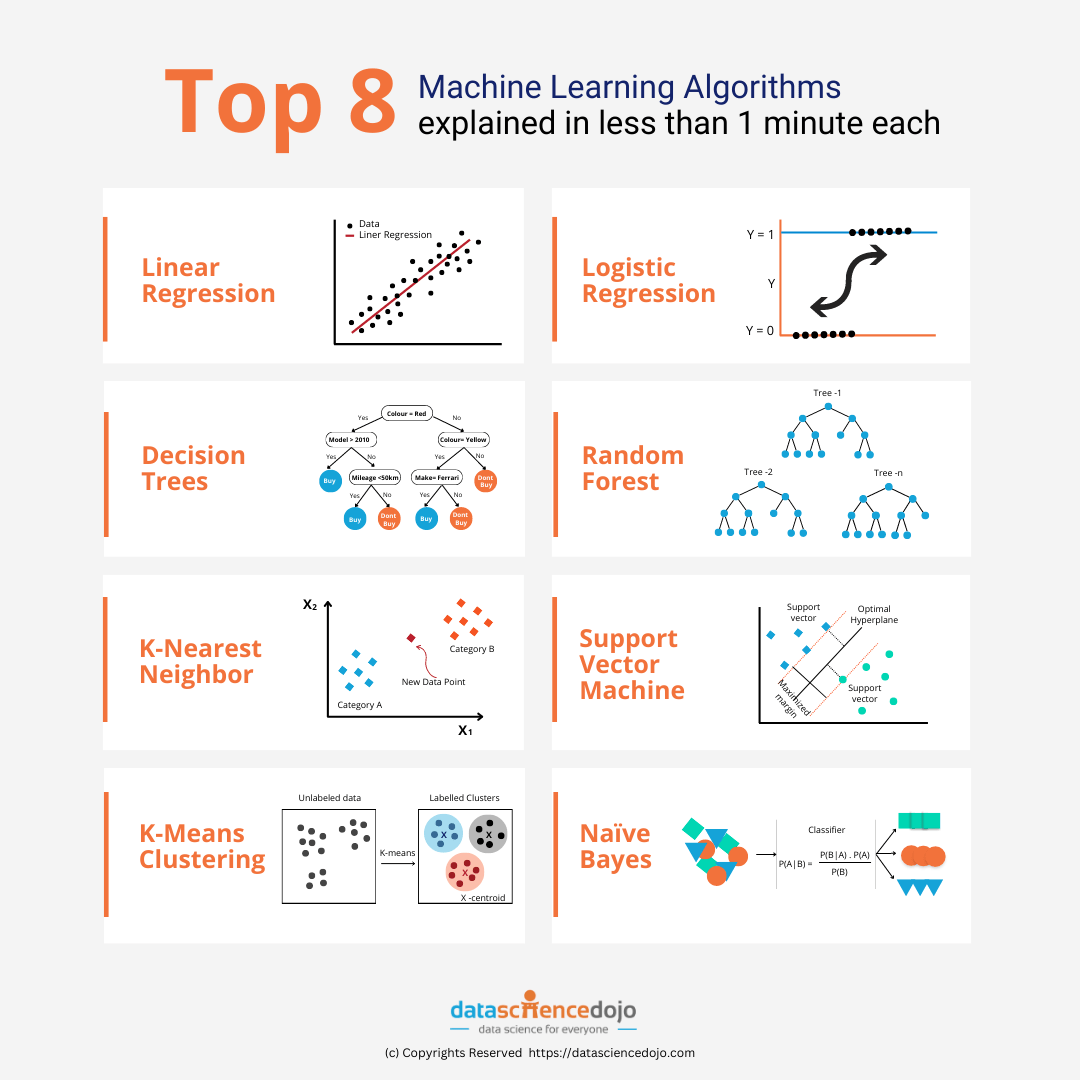
1. Linear Regression
Linear regression is a simple machine learning model and chances are you are already aware of it! Do you remember plotting the line y=mx+c in your introductory algebra class? This is an equation of a straight line where m is its gradient and c is the point where the line crosses the y-axis. Using this equation, you’re able to estimate the value of y for any given value of x. Similarly, linear regression involves estimating the relationship between independent variables (x) and a dependent variable(y).
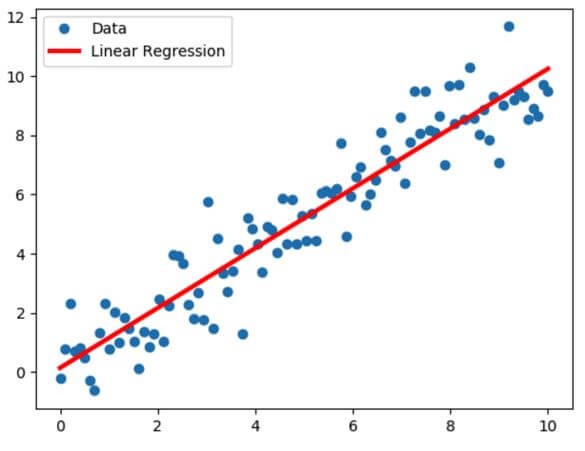
2. Logistic Regression
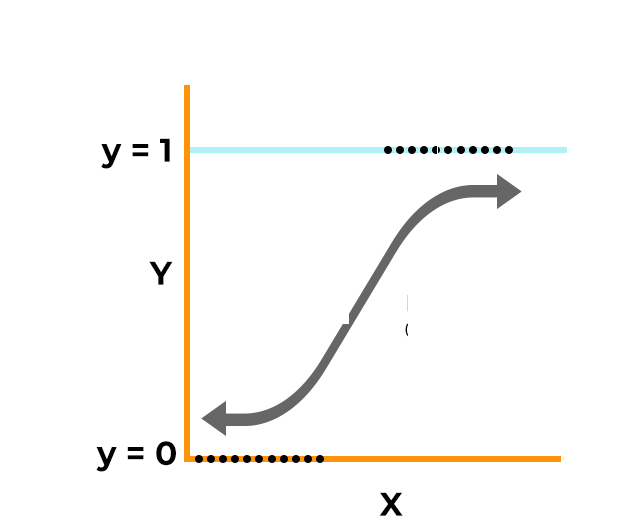
Just like linear regression, logistic regression is a machine learning model used to determine the relationship between a dependent variable and one or more independent variables. However, this model is used for classification analysis. This is because logistic regression predicts the probability of an event occurring. For a probability greater than 0.5, a value of 1 is assigned, and for less than that 0. For example, you can use logistic regression to predict whether a student will pass (1) an exam, or they will fail (0).

3. Decision Trees
Decision tree is a supervised machine learning model that repeatedly splits the data based on a question corresponding to the features. The model learns the best way to reduce randomness and drafts a decision tree that can be used to predict the category of an item based on answering a selection of questions. For example, in the case of whether it will rain today or not, the questions can be whether it is sunny, did it rain yesterday, whether it is windy, and so on.
4. Random Forest
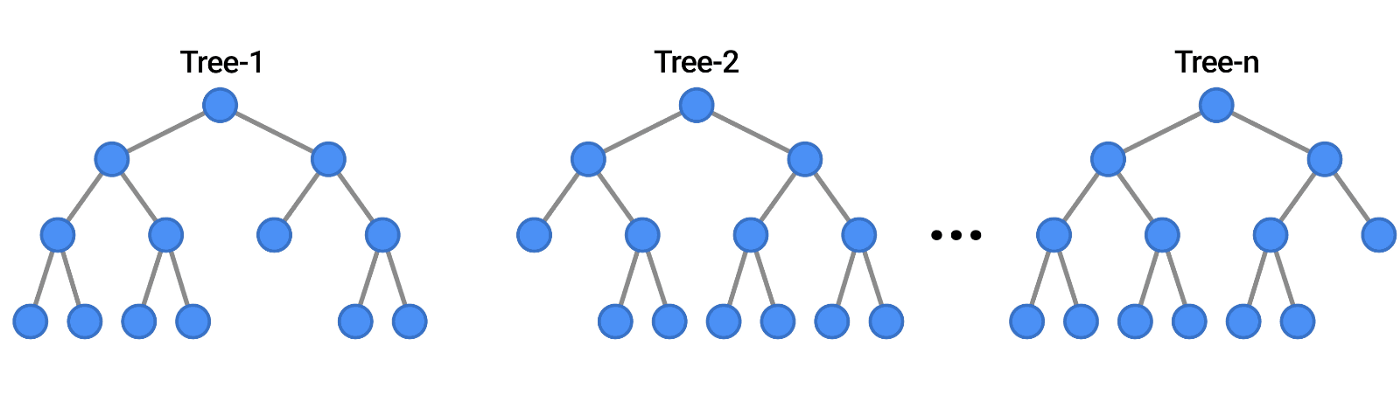
Random Forest is a machine learning algorithm that works similarly to a decision tree. The difference is that random forest uses multiple decision trees to make a prediction and hence decreases overfitting. The process of majority voting is carried out and the class selected by most trees is assigned to an item. For example, if two trees predict it to be 0, and one tree predicts it to be 1, then the class of 0 will be assigned to the item.
5. K-Nearest Neighbor
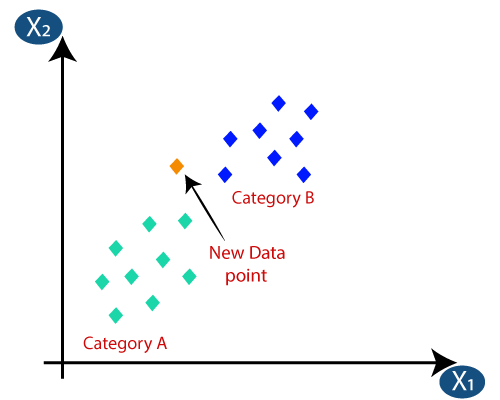
K-Nearest Neighbor is another simple machine learning algorithm that classifies new cases based on the category/class of the data points nearest to the new data point. That is, if most neighbors of an unknown item belong to class 1, then we assign class 1 to this unknown item. The number of neighbors to take into consideration is the value K assigned. If k=10, we will look at the 10 nearest neighbors of this item. The nearest neighbors are determined by measuring the distance using distance measures such as Euclidean distance, and the nearest are those that have the shortest distance.
6. Support Vector Machine
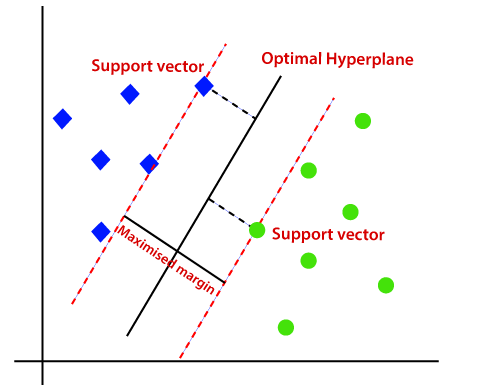
Support vector machines by dividing the data points using a hyperplane which is a straight line. The points donated by the blue diamond form one class on the left side of the plane and the points donated by the green circle represent another class on the right side of the plane. If we want to predict the class of a new point, we can simply determine it by whether it lies on the left or right side of the hyperplane and where it is within the margin.
7. K-Means clustering
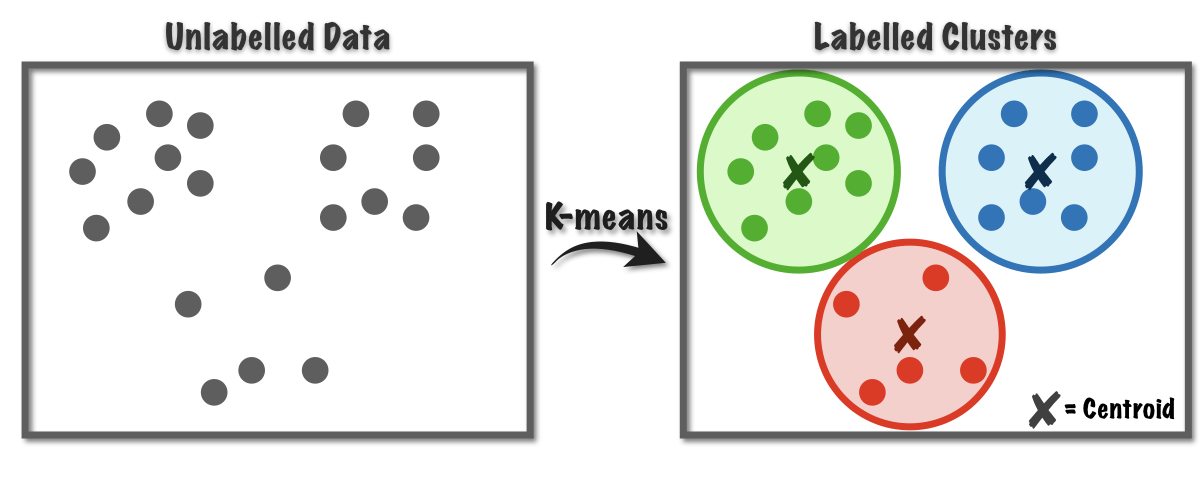
K-means clustering is an unsupervised machine learning algorithm. That means it is used to work with data points whose class is not already known. We can use the clustering algorithm to group similar items into clusters. The number of clusters is determined by the value of K assigned. For example, you assign K=3. Three clusters are selected at random, and we adjust them until they are highly distinct from one another. Distinct clusters will have points similar to each other but these points will be distinct from points in another cluster.
8. Naïve Bayes
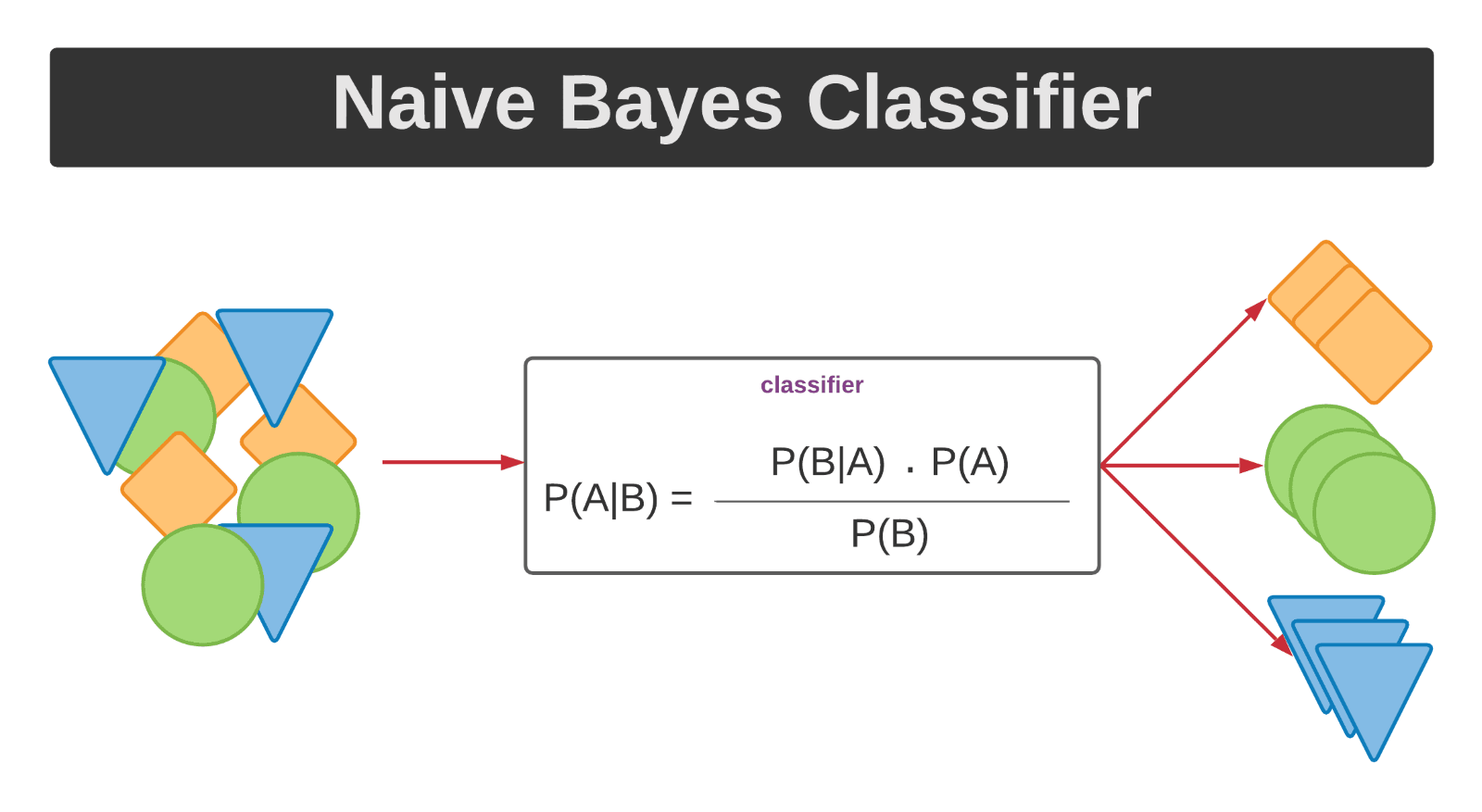
Naïve Bayes is a probabilistic machine learning model based on the Bayes theorem that assumes that all the features are independent of one another. Conditional probability refers to the probability of an outcome occurring if it is given that another event has occurred. This algorithm predicts the probability that an item belongs to a particular class and is assigned the class with the highest probability.
Share more Machine Learning algorithms with us
Have we missed any Machine Learning algorithm that you would like to learn about? Share with us in the comments below