

As businesses continue to generate massive volumes of data, the problem is to store this data and efficiently use it to drive decision-making and innovation. Enterprise data management is critical for ensuring that data is effectively managed, integrated, and utilized throughout the organization.
One of the most recent developments in this field is the integration of Large Language Models (LLMs) with enterprise data lakes and warehouses.
Learn how is LLM development making chatbots smarter.
This article will look at how orchestration frameworks help develop applications on enterprise data, with a focus on LLM integration, scalable data pipelines, and critical security and governance considerations.

LLM Integration with Enterprise Data Lakes and Warehouses
Large language models, like OpenAI’s GPT-4, have transformed natural language processing and comprehension. Integrating LLMs with company data lakes and warehouses allows for significant insights and sophisticated analytics capabilities.
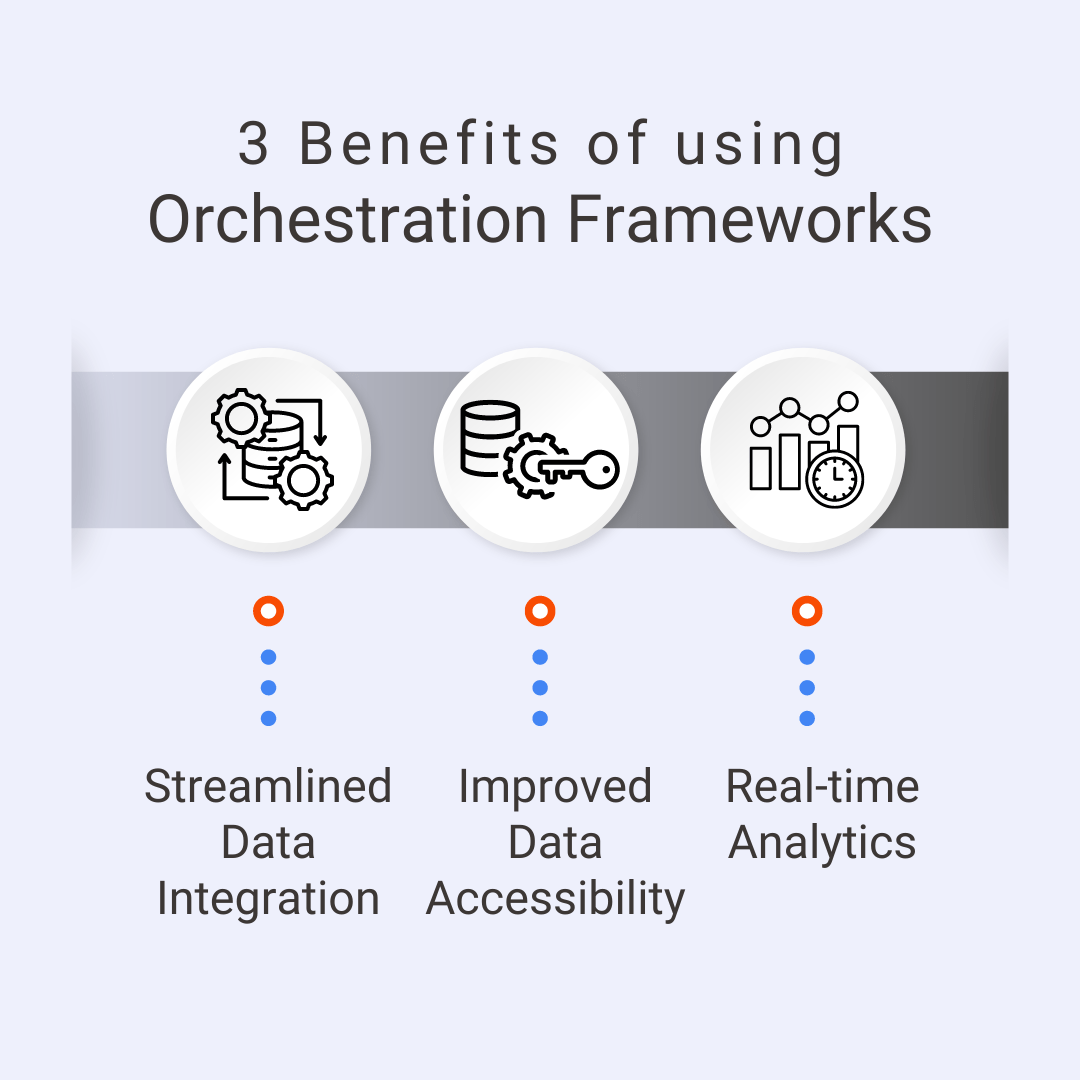
Here’s how orchestration frameworks help with this:
Streamlined Data Integration
Use orchestration frameworks like Apache Airflow and AWS Step Functions to automate ETL processes and efficiently integrate data from several sources into LLMs. This automation decreases the need for manual intervention and hence the possibility of errors.
Empower non-profit organizations through Generative AI and LLMs
Improved Data Accessibility
Integrating LLMs with data lakes (e.g., AWS Lake Formation, Azure Data Lake) and warehouses (e.g., Snowflake, Google BigQuery) allows enterprises to access a centralized repository for structured and unstructured data. This architecture allows LLMs to access a variety of datasets, enhancing their training and inference capabilities.
Real-time Analytics
Orchestration frameworks enable real-time data processing. Event-driven systems can activate LLM-based analytics as soon as new data arrives, enabling organizations to make quick decisions based on the latest information.
Explore 10 ways to generate more leads with data analytics
Scalable Data Pipelines for LLM Training and Inference
Creating and maintaining scalable data pipelines is essential for training and deploying LLMs in an enterprise setting.
Here’s how orchestration frameworks work:
Automated Workflows
Orchestration technologies help automate complex operations for LLM training and inference. Tools like Kubeflow Pipelines and Apache NiFi, for example, can handle the entire lifecycle, from data import to model deployment, ensuring that each step is completed correctly and at scale.
Unleash LLM power and build your own ChatGPT in Data Science Dojo’s LLM Bootcamp
Resource Management
Effectively managing computing resources is crucial for processing vast amounts of data and complex computations in LLM procedures. Kubernetes, for example, can be combined with orchestration frameworks to dynamically assign resources based on workload, resulting in optimal performance and cost-effectiveness.
Monitoring and Logging
Tracking data pipelines and model performance is essential for ensuring reliability. Orchestration frameworks include built-in monitoring and logging tools, allowing teams to identify and handle issues quickly. This guarantees that the LLMs produce accurate and consistent findings.
Security and Governance Considerations for Enterprise LLM Deployments
Deploying LLMs in an enterprise context necessitates strict security and governance procedures to secure sensitive data and meet regulatory standards.
Orchestration frameworks can meet these needs in a variety of ways
- Data Privacy and Compliance: Orchestration technologies automate data masking, encryption, and access control processes to implement privacy and compliance requirements, such as GDPR and CCPA. This guarantees that only authorized workers have access to sensitive information.
- Audit Trails: Keeping accurate audit trails is crucial for tracking data history and changes. Orchestration frameworks can provide detailed audit trails, ensuring transparency and accountability in all data-related actions.
- Access Control and Identity Management: Orchestration frameworks integrate with IAM systems to guarantee only authorized users have access to LLMs and data. This integration helps to prevent unauthorized access and potential data breaches.
- Strong Security Protocols: Encryption at rest and in transport is essential for ensuring data integrity. Orchestration frameworks can automate the implementation of these security procedures, maintaining consistency across all data pipelines and operations.

Case Study: Implementing Orchestration Frameworks for Enterprise Data Management at TechCorp
TechCorp is a worldwide technology business focused on software solutions and cloud services. TechCorp generates and handles vast amounts of data every day for its global customer base. The corporation aimed to use its data to make better decisions, improve consumer experiences, and drive innovation.
To do this, TechCorp decided to connect Large Language Models (LLMs) with its enterprise data lakes and warehouses, leveraging orchestration frameworks to improve data management and analytics.
Know more about the power of Large Language Models in the Financial Industry
Challenge
TechCorp faced a number of issues in enterprise data management:
- Data Integration: Difficulty in creating a coherent view due to data silos from diverse sources.
- Scalability: The organization required efficient data handling for LLM training and inference.
- Security and Governance: Maintaining data privacy and regulatory compliance was crucial.
- Resource Management: Efficiently manage computing resources for LLM procedures without overpaying.
Solution
To address these difficulties, TechCorp designed an orchestration system built on Apache Airflow and Kubernetes. The solution included the following components:
Data Integration with Apache Airflow
- ETL Pipelines were automated using Apache Airflow. Data from multiple sources (CRM systems, transactional databases, and log files) was extracted, processed, and fed into an AWS-based centralized data lake.
- Data Harmonization: Airflow workflows harmonized data, making it acceptable for LLM training.
Scalable Infrastructure with Kubernetes
- Dynamic Resource Allocation: Kubernetes used dynamic resource allocation to install LLMs and scale resources based on demand. This method ensured that computational resources were used efficiently during peak periods and scaled down when not required.
- Containerization: LLMs and other services were containerized with Docker, allowing for consistent and stable deployment across several environments.
- Data Encryption: All data at rest and in transit was encrypted. Airflow controlled the encryption keys and verified that data protection standards were followed.
- Access Control: The integration with AWS Identity and Access Management (IAM) ensured that only authorized users could access sensitive data and LLM models.
- Audit Logs: Airflow’s logging capabilities were used to create comprehensive audit trails, ensuring transparency and accountability for all data processes.
Read more about simplifying LLM apps with orchestration frameworks
LLM Integration and Deployment
- Training Pipelines: Data pipelines for LLM training were automated with Airflow. The training data was processed and supplied into the LLM, which was deployed across Kubernetes clusters.
- Inference Services: Real-time inference services were established to process incoming data and deliver insights. These services were provided via REST APIs, allowing TechCorp applications to take advantage of the LLM’s capabilities.
Implementation Steps
- Planning and design
- Identifying major data sources and defining ETL needs.
- Developed architecture for data pipelines, LLM integration, and Kubernetes deployments.
- Implemented security and governance policies.
- Deployment
- Set up Apache Airflow to orchestrate data pipelines.
- Set up Kubernetes clusters for scalability LLM deployment.
- Implemented security measures like data encryption and IAM policies.
- Testing and Optimization
- Conducted thorough testing of ETL pipelines and LLM models.
- Improved resource allocation and pipeline efficiency.
- Monitored data governance policies continuously to ensure compliance.
- Monitoring and maintenance
- Implemented tools to track data pipeline and LLM performance.
- Updated models and pipelines often to enhance accuracy with fresh data.
- Conducted regular security evaluations and kept audit logs updated.
Results
TechCorp experienced substantial improvements in its data management and analytics capabilities:
- Improved Data Integration: A unified data perspective across the organization leads to enhanced decision-making.
- Scalability: Efficient resource management and scalable infrastructure resulted in lower operational costs.
- Improved Security: Implemented strong security and governance mechanisms to maintain data privacy and regulatory compliance.
- Advanced Analytics: Real-time insights from LLMs improved customer experiences and spurred innovation.

Conclusion
Orchestration frameworks are critical for developing robust enterprise data management applications, particularly when incorporating sophisticated technologies such as Large Language Models.
These frameworks enable organizations to maximize the value of their data by automating complicated procedures, managing resources efficiently, and guaranteeing strict security and control.
TechCorp’s success demonstrates how leveraging orchestration frameworks may help firms improve their data management capabilities and remain competitive in a data-driven environment.