
In the past few years, the number of people entering the field of data science has increased drastically because of higher salaries, an increasing job market, and more demand.
Undoubtedly, there are unlimited programs to learn data science, several companies offering in-depth Data Science Bootcamp, and a ton of channels on YouTube that are covering data science content. The abundance of data science content and learning pathways can easily confuse one with where to begin or how to start their data science career.
To ease this data science journey for beginners, intermediate, or starters, we are going to list a couple of data science tutorials, crash courses, webinars, and videos. The aim of this blog is to help beginners navigate their data science path, and also help them to determine if data science is the most perfect career choice for them or not.
If you are planning to add value to your data science skillset, check out our Python for Data Science training.
Let’s get started with the list:
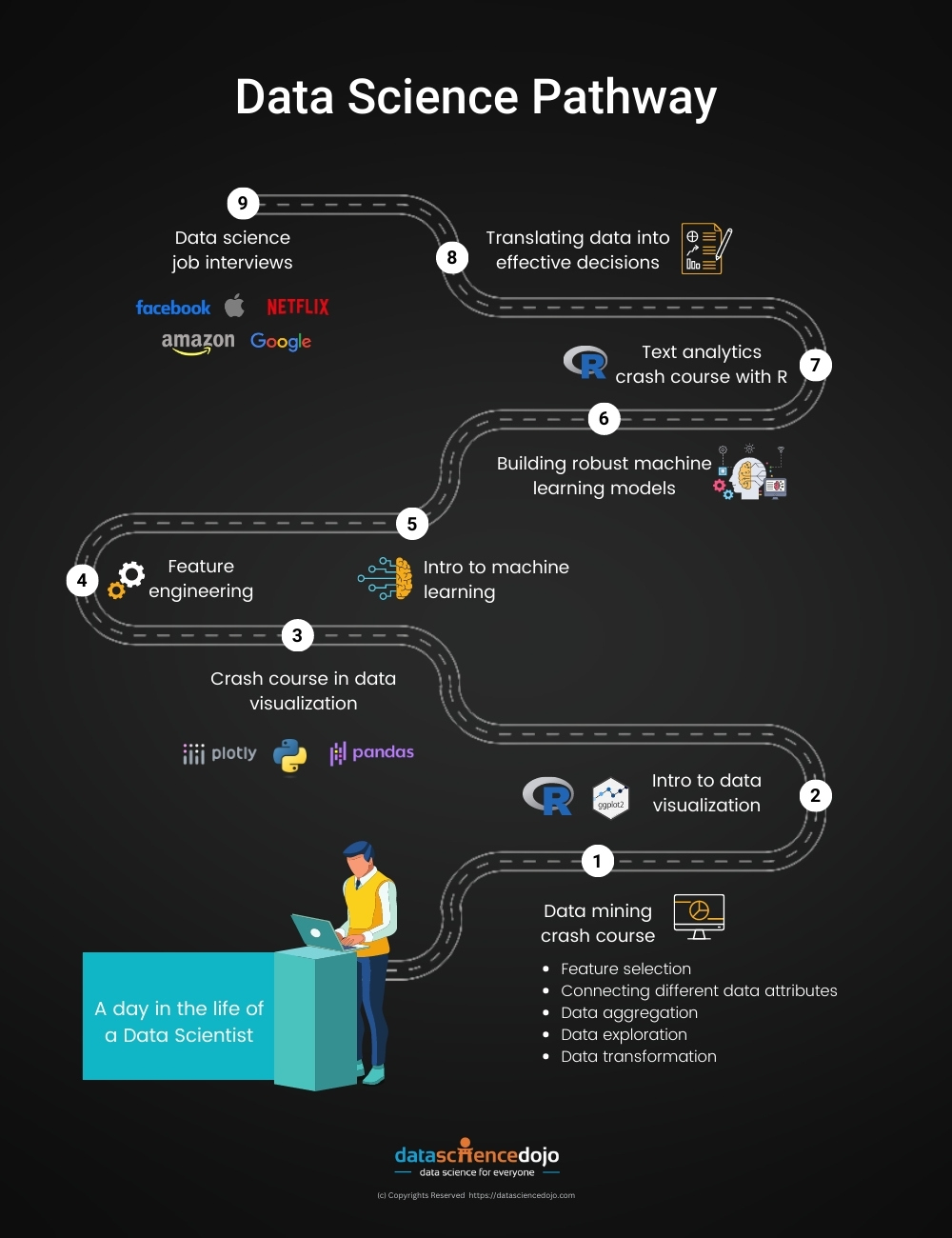
1. A day in the life of a data scientist
This talk will introduce you to what a typical data scientist’s job looks like. It will familiarize you with the day-to-day work that a data scientist does and differentiate between the different roles and responsibilities that data scientists have across companies.
This talk will help you understand what a typical day in the data scientist’s life looks like and assist you to decide if data science is the perfect choice for your career.
2. Data mining crash course
Data mining has become a vital part of data science and analytics in today’s world. And, if you planning to jumpstart your career in the field of data science, it is important for you to understand data mining. Data mining is a process of digging into different types of data and data sets to discover hidden connections between them.
The concept of data mining includes several steps that we are going to cover in this course. In this talk, we will cover how data mining is used in feature selection, connecting different data attributes, data aggregation, data exploration, and data transformation.
Additionally, we will cover the importance of checking data quality, reducing data noise, and visualizing the data to demonstrate the importance of good data.
3. Intro to data visualization with R & ggplot2
While tools like Excel, Power BI, and Tableau are often the go-to solutions for data visualizations, none of these tools can compete with R in terms of the sheer breadth of, and control over, crafted data visualizations. Thereby, it is important for one to learn about data visualization with R & ggplot2.
In this tutorial, you will get a brief introduction to data visualization with the ggplot2 package. The focus of the tutorial will be using ggplot2 to analyze your data visually with a specific focus on discovering the underlying signals/patterns of your business.
4. Crash course in data visualization: Tell a story with your data
Telling a story with your data is more important than ever. The best insights and machine learning models will not create an impact unless you are able to effectively communicate with your stakeholders. Hence, it is very important for a data scientist to have an in-depth understanding of data visualization.
In this course, we will cover chart theory and pair programs that will help us create a chart using Python, Pandas, and Plotly.
5. Feature engineering
To become a proficient data scientist, it is significant for one to learn about feature engineering. In this talk, we will cover ways to do feature engineering both with dplyr (“mutate” and “transmute”) and base R (“ifelse”). Additionally, we’ll go over four different ways to combine datasets.
With this talk, you will learn how to impute missing values as well as create new values based on existing columns.
6. Intro to machine learning with R & caret
The R programming language is experiencing rapid increases in popularity and wide adoption across industries. This popularity is due, in part, to R’s huge collection of open-source machine-learning algorithms. If you are a data scientist working with R, the caret package (short for Classification and Regression Training) is a must-have tool in your toolbelt.
In this talk, we will provide an introduction to the caret package. The focus of the talk will be using caret to implement some of the most common tasks of the data science project lifecycle and to illustrate incorporating caret into your daily work.
7. Building robust machine learning models
Modern machine learning libraries make the model building look deceptively easy. An unnecessary emphasis (admittedly, annoying to the speaker) on tools like R, Python, SparkML, and techniques like deep learning is prevalent.
Relying on tools and techniques while ignoring the fundamentals is the wrong approach to model building. Thereby, our aim here is to take you through the fundamentals of building robust machine-learning models.
8. Text analytics crash course with R
Industries across the globe deal with structured and unstructured data. To generate insights companies, work towards analyzing their text data. The data pipeline for transforming unstructured text into valuable insights consists of several steps that each data scientist must learn about.
This course will take you through the fundamentals of text analytics and teach you how to transform text data using different machine-learning models.
9. Translating data into effective decisions
As data scientists, we are constantly focused on learning new ML techniques and algorithms. However, in any company, value is created primarily by making decisions. Therefore, it is important for a data scientist to embrace uncertainty in a data-driven way.
In this talk, we present a systematic process where ML is an input to improve our ability to make better decisions, thereby taking us closer to the prescriptive ideal.
10. Data science job interviews
Once you are through your data science learning path, it is important to work on your data science interviews in order to uplift your career. In this talk, you will learn how to solve SQL, probability, ML, coding, and case interview questions that are asked by FAANG + Wall Street.
We will also share the contrarian job-hunting tips that can help you to find a job at Facebook, Google, or an ML startup.
Choose from Available Data Science Learning Pathways Today!
We hope that the aforementioned 12 talks assist you to get started with your data science learning path. If you are looking for a more detailed guide, then do check out our Data Science Roadmap.
If you want to receive data science blogs, infographics, cheat sheets, and other useful resources right into your inbox, subscribe to our weekly & monthly newsletter.

Whether you are new to data science or an expert, our upcoming talks, tutorials, and crash courses can help you learn diverse data science & engineering concepts, so make sure to stay tuned with us.
