

Ever wonder what happens to your data after you chat with an AI like ChatGPT? Do you wonder who else can see this data? Where does it go? Can it be traced back to you?
These concerns aren’t just hypothetical.
In the digital age, data is power. But with great power comes great responsibility, especially when it comes to protecting people’s personal information. One of the ways to make sure that data is used responsibly is through data anonymization.
It is a powerful technique that allows AI to learn and improve without compromising user privacy. But how does it actually work? How do tech giants like Google, Apple, and OpenAI anonymize data to train AI models without violating user trust? Let’s dive into the world of data anonymization to understand how it works.

What is Data Anonymization?
It is the process of removing or altering any information that can be traced back to an individual. It means stripping away the personal identifiers that could tie data back to a specific person, enabling you to use the data for analysis or research while ensuring privacy.
Anonymization ensures that the words you type, the questions you ask, and the information you share remain untraceable and secure.
The Origins of Data Anonymization
Data anonymization has been around for decades since governments and organizations began collecting vast amounts of personal data. However, with the rise of digital technologies, concerns about privacy breaches and data misuse grew, leading to the need for ways to protect sensitive information.
Thus, the origins of data anonymization can be traced back to early data protection laws, such as the Privacy Act of 1974 in the United States and the European Data Protection Directive in 1995. These laws laid the groundwork for modern anonymization techniques that are now a critical part of data security and privacy practices.
As data-driven technologies continue to evolve, data anonymization has become a crucial tool in the fight to protect individual privacy while still enabling organizations to benefit from the insights data offers.
You can also learn about the ethical challenges of LLMs
Key Benefits of Data Anonymization
Data anonymization has a wide range of benefits for businesses, researchers, and individuals alike. Some key advantages can be listed as follows:
- Protects Privacy: The most obvious benefit is that anonymization ensures personal data is kept private. This helps protect individuals from identity theft, fraud, and other privacy risks.
- Ensures Compliance with Regulations: With the introduction of strict regulations like GDPR and CCPA, anonymization is crucial for businesses to remain compliant and avoid heavy penalties.
- Enables Safe Data Sharing: Anonymized data can be shared between organizations and researchers without the risk of exposing sensitive personal information, fostering collaborations and innovations.
- Supports Ethical AI & Research: By anonymizing data, researchers and AI developers can train models and conduct studies without violating privacy, enabling the development of new technologies in an ethical way.
- Reduces Data Breach Risks: Even if anonymized data is breached, it’s much less likely to harm individuals since it can’t be traced back to them.
- Boosts Consumer Trust: In an age where privacy concerns are top of mind, organizations that practice data anonymization are seen as more trustworthy by their users and customers.
- Improves Data Security: Anonymization reduces the risk of exposing personally identifiable information (PII) in case of a cyberattack, helping to keep data safe from malicious actors.
In a world where privacy is becoming more precious, data anonymization plays a key role in ensuring that organizations can still leverage valuable insights from data without compromising individual privacy. So, whether you’re a business leader, a researcher, or simply a concerned individual, understanding data anonymization is essential in today’s data-driven world.
Let’s explore some important data anonymization techniques that you must know about.
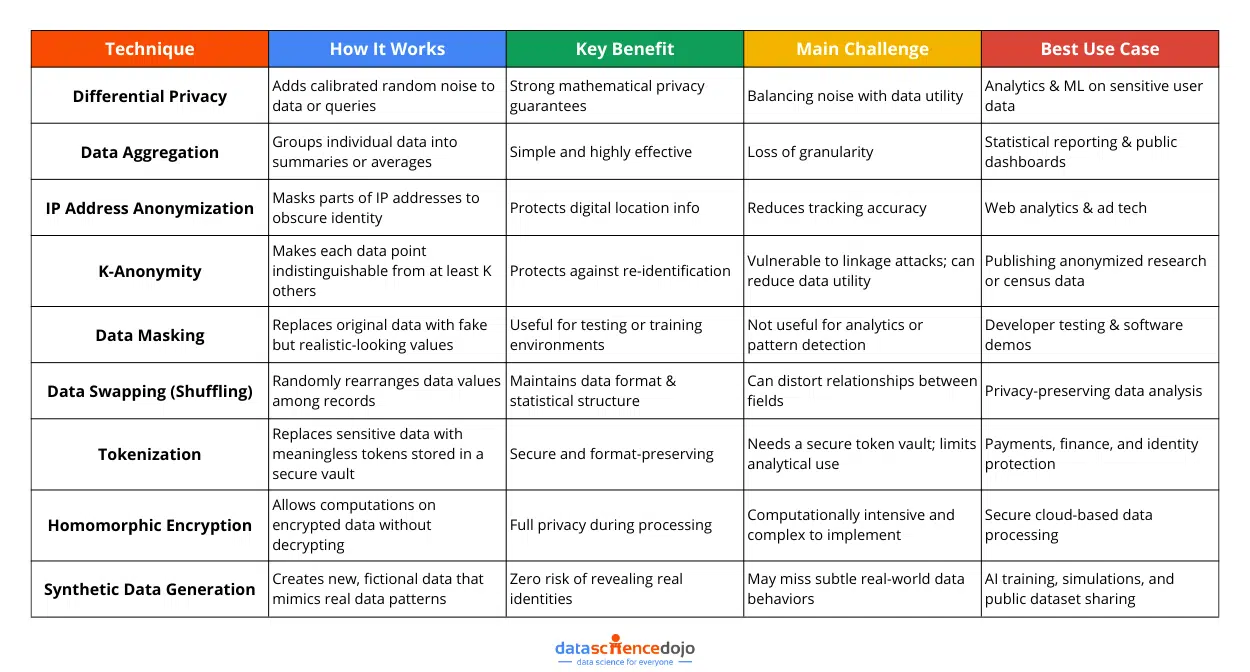
Key Techniques of Data Anonymization
Data anonymization is not a one-size-fits-all approach. Different scenarios require different techniques to ensure privacy while maintaining data utility. Organizations, researchers, and AI developers must carefully choose methods that provide strong privacy protection without rendering data useless.

Let’s dive into understanding some of the most effective anonymization techniques.
-
Differential Privacy: Anonymization with Mathematical Confidence
Differential privacy is a data anonymization technique that adds a layer of mathematically calibrated “noise” to a dataset or its outputs. This noise masks the contributions of individual records, making it virtually impossible to trace a specific data point back to a person.
It uses noise injection to complete the process. For instance, for an exact number of users of an app (say 12,387), the system adds a small random number to it. It will return either 12,390 or 12,375. While the result is close to the truth for useful insights, it keeps the confidentiality of individuals intact.
This approach ensures mathematical privacy, setting differential privacy apart from traditional anonymization techniques. The randomness is carefully calibrated based on something called a privacy budget (or epsilon, ε). This value balances privacy vs. data utility. A lower epsilon means stronger privacy but less accuracy, and vice versa.
-
Data Aggregation: Zooming Out to Protect Privacy
Data aggregation is one of the most straightforward ways to anonymize data. Instead of collecting and sharing data at the individual level, this method summarizes it into groups and averages. The idea is to combine data points into larger buckets, removing direct links to any one person.
For instance, instead of reporting every person’s salary in a company, you might share the average salary in each department. This data aggregation transforms granular, potentially identifiable data into generalized insights. It is done through:
- Averages: Like the average number of steps walked per day in a region.
- Counts or totals: Such as total website visits from a country instead of by each user.
- Ranges or categories: Instead of exact ages, you report how many users fall into age brackets.
-
IP Address Anonymization: Hiding Digital Footprints
Every time you visit a website, your device leaves a digital breadcrumb called an IP address. It is like your home address that can reveal where you are and who you might be. IP addresses are classified as personally identifiable information (PII) under laws like the GDPR.
This means that collecting, storing, or processing full IP addresses without consent could land a company in trouble. Hence, IP anonymization has become an important strategy for organizations to protect user privacy. Below is an explanation of how it works:
- For IPv4 addresses (the most common type, like 192.168.45.231), anonymization involves removing or replacing the last segment, turning it into something like 192.168.45.0. This reduces the precision of the location, masking the individual device but still giving you useful data like the general area or city.
- For IPv6 addresses (a newer, longer format), anonymization removes more segments because they can pinpoint devices even more accurately.
This masking happens before the IP address is logged or stored, ensuring that even the raw data never contains personal information. For example, Google Analytics has a built-in feature that anonymizes IP addresses, helping businesses stay compliant with privacy laws while analyzing traffic patterns.
-
K-Anonymity (Crowd-Based Privacy): Blending into the Data Crowd
K-anonymity is like the invisibility cloak of the data privacy world. It ensures any person’s data record in a dataset is indistinguishable from at least K–1 other people, meaning your data looks just like a bunch of others.
For instance, details like birthday, ZIP code, and gender do not seem revealing, but when combined, they can uniquely identify someone. K-anonymity solves that by making sure each combination of these quasi-identifiers (like age, ZIP, or job title) is shared by at least K people.
It mainly relies on two techniques:
- Generalization: replacing specific values with broader ones
- Suppression: removing certain values altogether when generalization is not enough
-
Data Masking
Data masking is a popular technique for protecting confidential information by replacing it with fake, but realistic-looking values. This approach is useful when you need to use real-looking data, like in testing environments or training sessions, without exposing the actual information.
The goal is to preserve the format of the original data while removing the risk of exposing PII. Here are some common data masking methods:
- Character Shuffling: Rearranging characters so the structure stays the same, but the value changes
- Substitution: Replacing real data with believable alternatives
- Nulling Out: Replacing values with blanks or null entries when the data is not needed at all
- Encryption: Encrypting the data so it is unreadable without a decryption key
- Date Shifting: Slightly changing dates while keeping patterns intact
Explore the strategies for data security in data warehousing
-
Data Swapping (Shuffling): Mixing Things Up to Protect Privacy
This method randomly rearranges specific data points, like birthdates, ZIP codes, or income levels, within the same column so that they no longer line up with the original individuals.
In practice, data swapping is used on quasi-identifiers – pieces of information that, while not directly identifying, can become identifying when combined (like age, gender, or ZIP code). Here’s how it works step-by-step:
- Identify the quasi-identifiers in your dataset (e.g., ZIP code, age).
- Randomly shuffle the values of these attributes between rows.
- Keep the overall data format and distribution intact, so it still looks and feels like real data.
For example, students in a class write their birthdays on sticky notes, and then the teacher mixes them up and hands them out at random. Everyone still has a birthday, but nobody knows the exact birthday of anybody.
-
Tokenization: Giving Your Data a Secret Identity
Tokenization is a technique where actual data elements (like names, credit card numbers, or Social Security numbers) are replaced with non-sensitive, randomly generated values called tokens. These tokens look like the real thing and preserve the data’s format, but they’re completely meaningless on their own.
For instance, when managing a VIP guest list, you avoid revealing the names by assigning them labels like “Guest 001,” “Guest 002,” and so on. This tokenization follows a simple but highly secure process:
- Identify sensitive data
- Replace each data element with a token
- Store the original data in a secure token vault
- Use the token in place of the real data
-
Homomorphic Encryption: Privacy Without Compromise
It is a method of performing computations on encrypted data. Once the results are decrypted, it is as if the operations were performed directly on the original, unencrypted data. This means you can keep data completely private and still derive value from it without ever exposing the raw information.
These are the steps to homomorphic encryption:
- Sensitive data is encrypted using a special homomorphic encryption algorithm.
- The encrypted data is handed off to a third party (cloud service or analytics team).
- This party performs analysis or computations directly on the encrypted data.
- The encrypted results are returned to the original data owner.
- The owner decrypts the result and gets the final output – accurate, insightful, and 100% private.
-
Synthetic Data Generation
Synthetic data generation fabricates new, fictional records that look and act like real data. That means you get all the value of your original dataset (structure, patterns, relationships), without exposing anyone’s private details.
Think of it like designing a CGI character for a movie. The character walks, talks, and emotes like a real person, but no actual actor was filmed. Similarly, synthetic data keeps the realism of your dataset intact while ensuring that no real individual can be traced.
Here’s a simplified look at how synthetic data is created and used to anonymize information:
-
Data Modeling: The system studies the original dataset using machine learning (often GANs) to learn its structure, patterns, and relationships between fields.
-
Data Generation: Based on what it learned, the system creates entirely new, fake records that mimic the original data without representing real individuals.
-
Validation: The synthetic data is tested to ensure it reflects real-world patterns without duplicating or revealing any actual personal information.
Data anonymization is undoubtedly a powerful tool for protecting privacy, but it is not without its challenges. Businesses must tread carefully and strike the right balance.
Challenges and Limitations of Data Anonymization
While data anonymization techniques offer impressive privacy protection, they come with their own set of challenges and limitations. These hurdles are important to consider when implementing anonymization strategies, as they can impact the effectiveness of the process and its practical application in real-world scenarios.
Here’s a list of controversial experiments in big data ethics
Let’s dive into some of the major challenges that businesses and organizations face when anonymizing data.
Risk of Re-Identification (Attackers Combining External Datasets)
One of the biggest challenges with data anonymization is the risk of re-identification. Even if data is anonymized, attackers can sometimes combine it with other publicly available datasets to piece together someone’s identity. This makes re-identification a real concern for organizations dealing with sensitive information.
To reduce this risk, it’s important to layer different anonymization techniques, such as pairing K-anonymity with data masking or using differential privacy to introduce noise. Regular audits can help spot weak points in data, and reducing data granularity can assist in keeping individuals anonymous.
Trade-off Between Privacy & Data Utility
One of the biggest hurdles in data anonymization is balancing privacy with usefulness. The more you anonymize data, the safer it becomes, but it also loses important details needed for analysis or training AI models. For example, data masking protects identities, but it can limit how much insight you can extract from the data.
To overcome this, businesses can tailor anonymization levels based on the sensitivity of each dataset, anonymizing the most sensitive fields while keeping the rest intact for meaningful analysis where possible. Techniques like synthetic data generation can also help by creating realistic datasets that protect privacy without compromising on value.
Compliance Complexity (Navigating Regulations like GDPR, CCPA, HIPAA)
For organizations working with sensitive data, staying compliant with privacy laws is a must. However, it is a challenge when different countries and industries have their own rules. Businesses operating across borders must navigate these regulations to avoid hefty fines and damage to their reputation.
Organizations should work closely with legal experts and adopt a compliance-by-design approach, ensuring privacy in every stage of the data lifecycle. Regular audits, legal check-ins, and reviewing anonymization techniques can help ensure everything stays within legal boundaries.
Thus, as data continues to be an asset for many organizations, finding effective anonymization strategies will be essential for preserving both privacy and analytical value.
Real-World Use Cases of Data Anonymization
Whether it’s training AI models, fighting fraud, or building smarter tech, anonymization is working behind the scenes. Let’s take a look at how it’s making an impact in the real world.
Healthcare – Protecting Patient Data in Research & AI
Healthcare is one of the most sensitive domains when it comes to personal data. Patient records, diagnoses, and medical histories are highly private, yet incredibly valuable for research and innovation. This is where data anonymization becomes a critical tool.
Hospitals and medical researchers use anonymized datasets to train AI models for diagnostics, drug development, disease tracking, and more while maintaining patient confidentiality. By removing or masking identifiable information, researchers can still uncover insights while staying HIPAA and GDPR compliant.
One prominent use case within this domain is the partnership between Google’s DeepMind and Moorfields Eye Hospital in the UK. They used anonymized medical data to train an AI system that can detect early signs of eye disease with high accuracy.
Read more about AI in healthcare
Financial Services – Secure Transactions & Fraud Prevention
A financial data leak could lead to identity theft, fraud, or regulatory violations. Hence, banks and fintech companies rely heavily on anonymization techniques to monitor transactions, detect fraud, and calculate credit scores while protecting sensitive customer information.
Companies like Visa and Mastercard use tokenization to anonymize payment data. Instead of the real card number, they use a token that represents the card in a transaction. Even if the token is stolen, it is useless without access to the original data stored securely elsewhere.
This boosts customer trust, strengthens security, and makes it possible to safely analyze transaction patterns and detect fraud in real time.
Explore the real-world applications of AI tools in finance
Big Tech & AI – Privacy-Preserving Machine Learning
Tech companies collect huge amounts of data to power everything from recommendation engines to voice assistants. A useful approach for these companies to ensure user privacy is federated learning (FL), which allows AI models to be trained directly on users’ devices.
Combined with differential privacy, it adds statistical “noise” to individual data points, ensuring sensitive user data never leaves the device or gets stored in a central database.
For example, Google’s Gboard, the Android keyboard app, uses FL to improve word predictions and autocorrect. It learns from how users type, but the data stays on the phone. This protects user privacy while making the app smarter over time.

Despite these applications, it is important to know that each industry faces its own challenges. However, with the right techniques such as tokenization, federated learning, and differential privacy, organizations can find the perfect balance between utility and confidentiality.
Privacy Isn’t Optional: It’s the Future
Data anonymization is essential in today’s data-driven world. It helps businesses innovate safely, supports governments in protecting citizens, and ensures individuals’ privacy stays intact.
With real-world strategies from companies like Google and Visa, it is clear that protecting data does not mean sacrificing insights. Techniques like tokenization, federated learning, and differential privacy prove that security and utility can go hand-in-hand.
Learn more about AI ethics for today’s world
If you’re ready to make privacy a priority, here’s how to start:
- Start small: Identify which types of sensitive data you collect and where it’s stored.
- Choose the right tools: Use anonymization methods that suit your industry and compliance needs.
- Make it a mindset: Build privacy into your processes, not just your policies.