
Let’s suppose you’re training a machine learning model to detect diseases from X-rays. Your dataset contains only 1,000 images—a number too small to capture the diversity of real-world cases. Limited data often leads to underperforming models that overfit and fail to generalize well.
It seems like an obstacle – until you discover data augmentation. By applying transformations such as rotations, flips, and zooms, you generate more diverse examples from your existing dataset, giving your model a better chance to learn effectively and improve its performance.
This isn’t just theoretical. Companies like Google have used techniques like AutoAugment, which optimizes data augmentation strategies, to improve image classification models in challenges like ImageNet.
Researchers in healthcare rely on augmentation to expand datasets for diagnosing rare diseases, while data scientists use it to tackle small datasets and enhance model robustness. Mastering data augmentation is essential to address data scarcity and improve model performance in real-world scenarios. Without it, models risk failing to generalize effectively.

What is Data Augmentation?
Data augmentation refers to the process of artificially increasing the size and diversity of a dataset by applying various transformations to the existing data. These modifications mimic real-world variations, enabling machine learning models to generalize better to unseen scenarios.
For instance:
- An image of a dog can be rotated, brightened, or flipped to create multiple unique versions.
- Text datasets can be enriched by substituting words with synonyms or rephrasing sentences.
- Time-series data can be altered using techniques like time warping and noise injection.
- Time Warping: Alters the speed or timing of a time series, simulating faster or slower events.
- Noise Injection: Adds random variations to mimic real-world disturbances and improve model robustness.
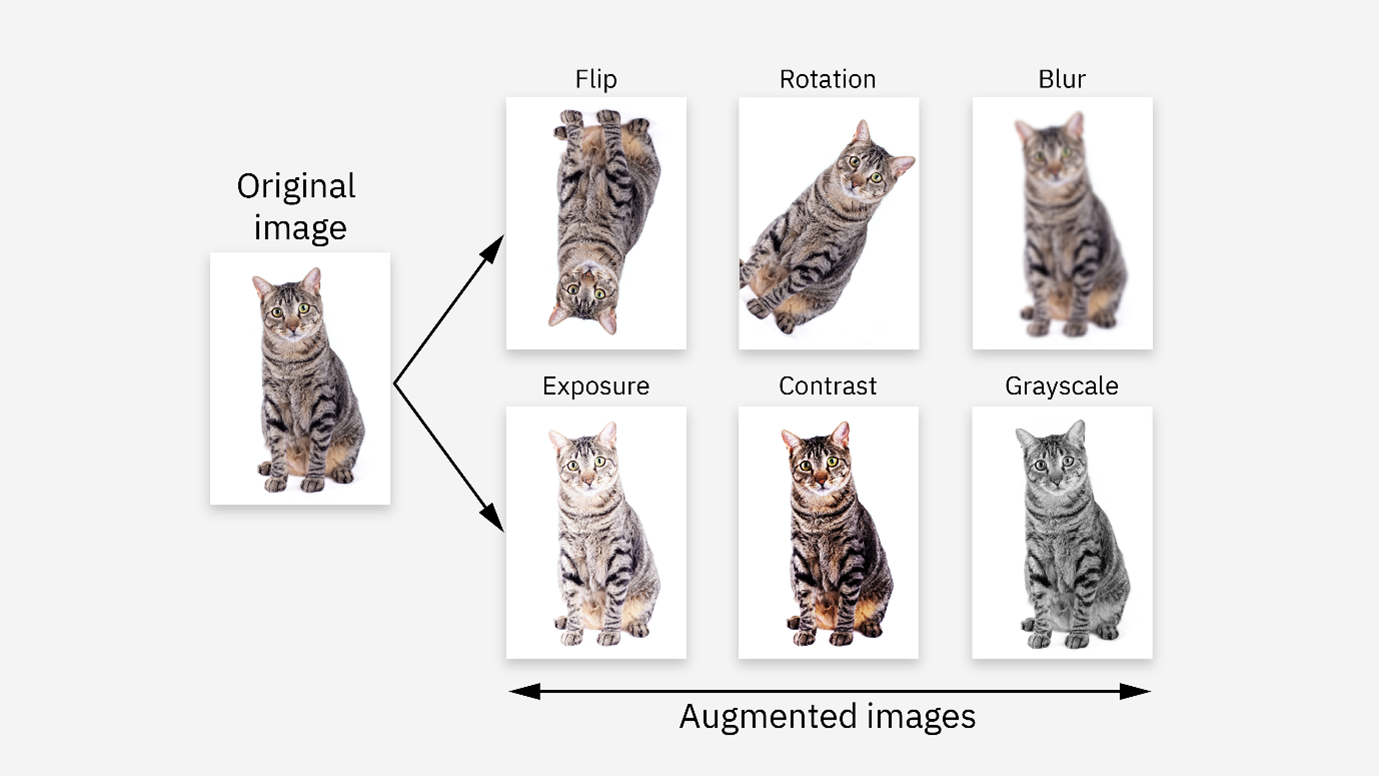
Why is Data Augmentation Important?
Tackling Limited Data
Many machine learning projects fail due to insufficient or unbalanced data, a challenge particularly common in the healthcare industry. Medical datasets are often limited because collecting and labeling data, such as X-rays or MRI scans, is expensive, time-consuming, and subject to strict privacy regulations.
Additionally, rare diseases naturally have fewer available samples, making it difficult to train models that generalize well across diverse cases.
Data augmentation addresses this issue by creating synthetic examples that mimic real-world variations. For instance, transformations like rotations, flips, and noise injection can simulate different imaging conditions, expanding the dataset and improving the model’s ability to identify patterns even in rare or unseen scenarios.
This has enabled breakthroughs in diagnosing rare diseases where real data is scarce.
Improving Model Generalization
Adding slight variations to the training data helps models adapt to new, unseen data more effectively. Without these variations, a model can become overly focused on the specific details or noise in the training data, a problem known as overfitting.
Overfitting occurs when a model performs exceptionally well on the training set but fails to generalize to validation or test data. Data augmentation addresses this by providing a broader range of examples, encouraging the model to learn meaningful patterns rather than memorizing the training data.
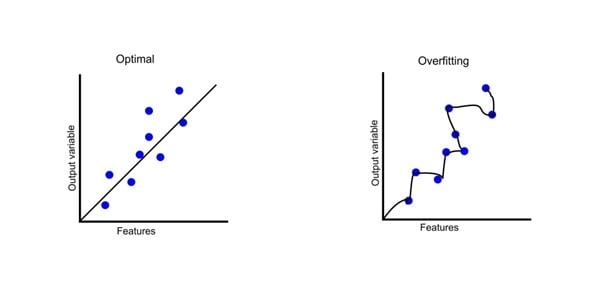
Enhancing Robustness
Data augmentation exposes models to a variety of distortions. For instance, in autonomous driving, training models with augmented datasets ensure they perform well in adverse conditions like rain, fog, or low light.
This improves robustness by helping the model recognize and adapt to variations it might encounter in real-world scenarios, reducing the risk of failure in unpredictable environments.
What are Data Augmentation Techniques?
For Images
- Flipping and Rotation: Horizontally flipping or rotating images by small angles can help models recognize objects in different orientations.
Example: In a cat vs. dog classifier, flipping a dog image horizontally helps the model learn that the orientation doesn’t change the label.
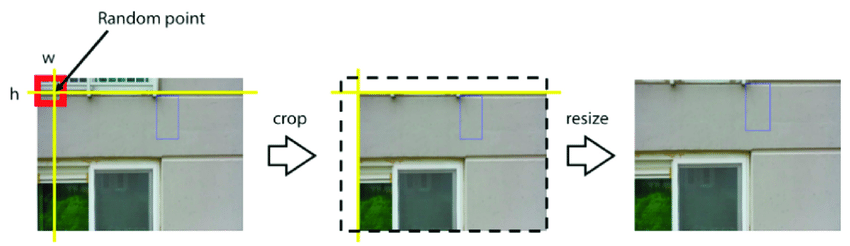
- Cropping and Scaling: Adjusting the size or focus of an image enables models to focus on different parts of an object.
Example: Cropping a person’s face from an image in a facial recognition dataset helps the model identify key features.
- Color Adjustment: Altering brightness, contrast, or saturation simulates varying lighting conditions.
Example: Changing the brightness of a traffic light image trains the model to detect signals in day or night scenarios.

- Noise Addition: Adding random noise to simulate real-world scenarios improves robustness.
Example: Adding noise to satellite images helps models handle interference caused by weather or atmospheric conditions.

For Text
- Synonym Replacement: Replacing words with their synonyms helps models learn semantic equivalence.
Example: Replacing “big” with “large” in a sentiment analysis dataset ensures the model understands the meaning doesn’t change.
- Word Shuffling: Randomizing word order in sentences helps models become less dependent on strict syntax.
Example: Rearranging “The movie was great!” to “Great was the movie!” ensures the model captures the sentiment despite the order.
- Back Translation: Translating text to another language and back creates paraphrased versions.
Example: Translating “The weather is nice today” to French and back might return “Today the weather is pleasant,” diversifying the dataset.
For Time-Series
- Window Slicing: Extracting different segments of a time series helps models focus on smaller intervals.
- Noise Injection: Adding random noise to the series simulates variability in real-world data.
- Time Warping: Altering the speed of the data sequence simulates temporal variations.
Data Augmentation in Action: Python Examples
Below are examples of how data augmentation can be applied using Python libraries.
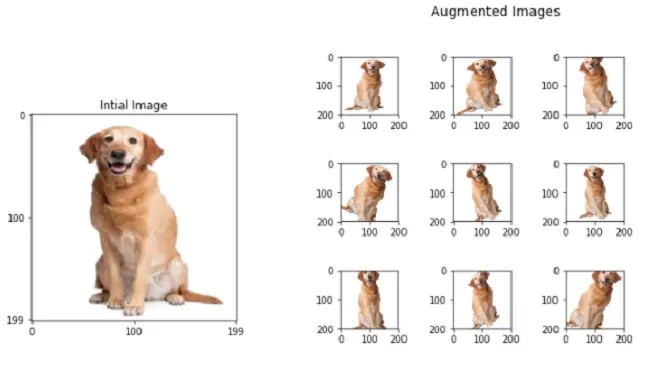
Image Data Augmentation

Text Data Augmentation
Output: Data augmentation is dispensable for deep learning models
Time-Series Data Augmentation
Advanced Technique: GAN-Based Augmentation
Generative Adversarial Networks (GANs) provide an advanced approach to data augmentation by generating realistic synthetic data that mimics the original dataset.
GANs use two neural networks—a generator and a discriminator—that work together: the generator creates synthetic data, while the discriminator evaluates its authenticity. Over time, the generator improves, producing increasingly realistic samples.
How GAN-Based Augmentation Works?
- A small set of original training data is used to initialize the GAN.
- The generator learns to produce data samples that reflect the diversity of the original dataset.
- These synthetic samples are then added to the original dataset to create a more robust and diverse training set.
Challenges in Data Augmentation
While data augmentation is powerful, it has its limitations:
- Over-Augmentation: Adding too many transformations can result in noisy or unrealistic data that no longer resembles the real-world scenarios the model will encounter. For example, excessively rotating or distorting images might create examples that are unrepresentative or confusing, causing the model to learn patterns that don’t generalize well.
- Computational Cost: Augmentation can be resource-intensive, especially for large datasets.
- Applicability: Not all techniques work well for every domain. For instance, flipping may not be ideal for text data because reversing the order of words could completely change the meaning of a sentence.
Example: Flipping “I love cats” to “cats love I” creates a grammatically incorrect and semantically different sentence, which would confuse the model instead of helping it learn.
Conclusion: The Future of Data Augmentation
Data augmentation is no longer optional; it’s a necessity for modern machine learning. As datasets grow in complexity, techniques like AutoAugment and GAN-based Augmentation will continue to shape the future of AI. By experimenting with the Python examples in this blog, you’re one step closer to building models that excel in the real world.
What will you create with data augmentation? The possibilities are endless!





