

Applications leveraging AI powered search are on the rise. My colleague, Sam Partee, recently introduced vector similarity search (VSS) in Redis and how it can be applied to common use cases. As he puts it:
“Users have come to expect that nearly every application and website provide some type of search functionality. With effective search becoming ever-increasingly relevant (pun intended), finding new methods and architectures to improve search results is critical for architects and developers. “
– Sam Partee: Vector Similarity Search: from Basics to Production
For example, in eCommerce, allowing shoppers to browse product inventory with a visual similarity component brings online shopping one step closer to mirroring an in-person experience.
However, this is only the tip of the iceberg. Here, we will pick up right where Sam left off with another common use case for vector similarity: Document Search.
We will cover:
- Common applications of AI-powered document search
- A typical production workflow
- A hosted example using the arXiv papers dataset
- Scaling embedding workflows
Lastly, we will share about an exciting upcoming hackathon co-hosted by Redis, MLOps Community, and Saturn Cloud from October 24 – November 4 that you can join in the coming weeks!

The use case
Whether we realize it or not, we take advantage of document search and processing capabilities in everyday life. We see its impact while searching for a long-lost text message in our phone, automatically filtering spam from our email inbox, and performing basic Google searches.
Businesses use it for information retrieval (e.g. insurance claims, legal documents, financial records), and even generating content-based recommendations (e.g. articles, tweets, posts).
Beyond lexical search
Traditional search, i.e. lexical search, emphasizes the intersection of common keywords between docs. However, a search query and document may be very similar to one another in meaning and not share any of the same keywords (or vice versa). For example, in the sentences below, all readers should be able to parse that they are communicating the same thing. But – only two words overlap.
“The weather looks dark and stormy outside.” <> “The sky is threatening thunder and lightning.”
Another example…with pure lexical search, “USA” and “United States” would not trigger a match though these are interchangeable terms.
This is where lexical search breaks down on its own.
Neural search
Search has evolved from simply finding documents to providing answers. Advances in NLP and large language models (GPT-3, BERT, etc) have made it incredibly easy to overcome this lexical gap AND expose semantic properties of text. Sentence embeddings form a condensed vector-like representation of unstructured data that encodes “meaning”.

These embeddings allow us to compute similarity metrics (e.g. cosine similarity, euclidean distance, and inner product) to find similar documents, i.e. neural (or vector) search. Neural search respects word order and understands the broader context beyond the explicit terms used.
Immediately this opens up a host of powerful use cases
- Question & Answering Services
- Intelligent Document Search + Retrieval
- Insurance Claim Fraud Detection

What’s even better is that ready-made models from Hugging Face Transformers can fast-track text-to-embedding transformations. Though, it’s worth noting that many use cases require fine-tuning to ensure quality results:
Production workflow
In a production software environment, document search must take advantage of a low-latency database that persists all docs and manages a search index that can enable nearest neighbor’s vector similarity operations between documents.
RediSearch was introduced as a module to extend this functionality over a Redis cluster that is likely already handling web request caching or online ML feature serving (for low-latency model inference).
Below we will highlight the core components of a typical production workflow.
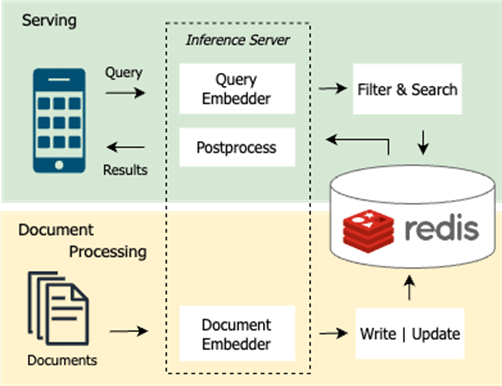
Document processing
In this phase, documents must be gathered, embedded, and stored in the vector database. This process happens upfront before any client tries to search and will also consistently run in the background on document updates, deletions, and insertions.
Up front, this might be iteratively done in batches from some data warehouse. Also, it’s common to leverage streaming data structures (e.g., Kafka, Kinesis, or Redis Streams) to orchestrate the pipeline in real time.
Scalable document processing services might take advantage of a high-throughput inference server like NVIDIA’s Triton. Triton enables teams to deploy, run, and scale trained AI models from any standard backend on GPU (or CPU) hardware.
Depending on the source, volume, and variety of data, a number of pre-processing steps will also need to be included in the pipeline (including embedding models to create vectors from text).
Serving
After a client enters a query along with some optional filters (e.g. year, category), the query text is converted into an embedding projected into the same vector space as the pre-processed documents. This allows for discovery of the most relevant documents from the entire corpus.
With the right vector database solution, these searches could be performed over hundreds of millions of documents in 100ms or less.
We recently put this into action and built redis-arXiv-search on top of the arXiv dataset (provided by Kaggle) as a live demo. Under the hood, we’re using Redis Vector Similarity Search, a Dockerized Python FastAPI, and a React Typescript single-page app (SPA).
Paper abstracts were converted into embeddings and stored in RediSearch. With this app, we show how you can search over these papers with natural language.
Let’s try an example: “Machine learning helps me get healthier”. When you enter this query, the text is sent to a Python server that converts the text to an embedding and performs a vector search.
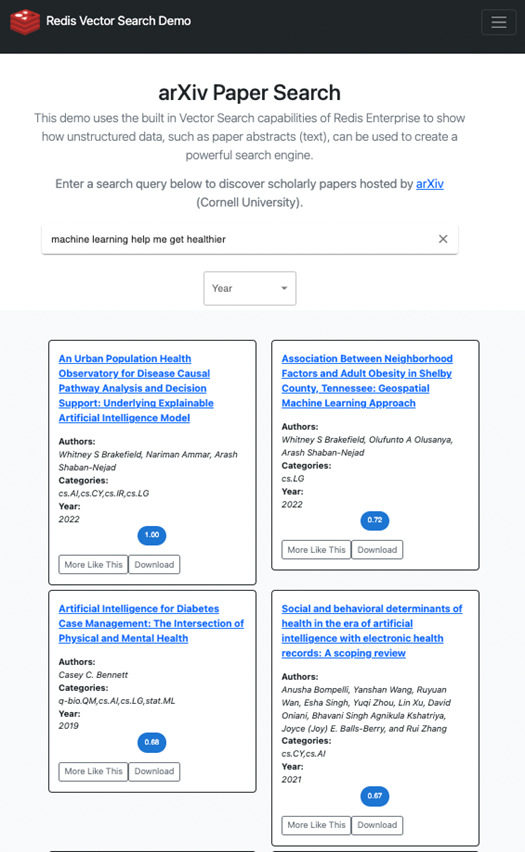
As you can see, the top four results are all related to health outcomes and policy. If you try to confuse it with something even more complex like: “jay z and Beyonce”, the top results are as follows:
- Elites, communities and the limited benefits of mentorship in electronic music
- Can Celebrities Burst Your Bubble?
- Forbidden triads and Creative Success in Jazz: The Miles Davis Factor
- Popularity and Centrality in Spotify Networks: Critical transitions in eigenvector centrality
We are pretty certain that the names of these two icons don’t show up verbatim in the paper abstracts… Because of the semantic properties encoded in the sentence embeddings, this application is able to associate “Jay Z” and “Beyonce” with topics like Music, Celebrities, and Spotify.
Scaling embedding workflows
That was the happy path. Realistically, most production-grade document retrieval systems rely on hundreds of millions or even billions of docs. It’s the price to pay for a system that can actually solve real-world problems over unstructured data.
Beyond scaling the embedded workflows, you’ll also need to have a database with enough horsepower to build the search index in a timely fashion.
GPU acceleration
In 2022, giving out free computers is the best way to make friends with anybody. Thankfully, our friends at Saturn Cloud have partnered with us to share access to GPU hardware.
They have a solid free tier that gives us access to an NVIDIA T4 with the ability to upgrade for a fee. Recently, Google Colab also announced a new pricing structure, a “Pay As You Go” format, which allows users to have flexibility in exhausting their compute quota over time.
These are both great options when running workloads on your CPU bound laptop or instance won’t cut it.
What’s even better is that Hugging Face Transformers can take advantage of GPU acceleration out-of-the-box. This can speed up ad-hoc embedding workflows quite a bit. However, for production use cases with massive amounts of data, a single GPU may not cut it.
Multi-GPU with Dask and cuDF
What if data will not fit into RAM of a single GPU instance, and you need the boost? There are many ways a data engineer might address this issue, but here I will focus on one particular approach leveraging Dask and cuDF.

The RAPIDS team at NVIDIA is dedicated to building open-source tools for executing data science and analytics on GPUs. All of the Python libraries have a comfortable feel to them, empowering engineers to take advantage of powerful hardware under the surface.
Scaling out workloads on multiple GPUs w/ RAPIDS tooling involves leveraging multi-node Dask clusters and cuDF data frames. Most Pythonista’s are familiar with the popular Pandas data frame library. cuDF, built on Apache Arrow, provides an interface very similar to Pandas, running on a GPU, all without having to know the ins and outs of CUDA development.
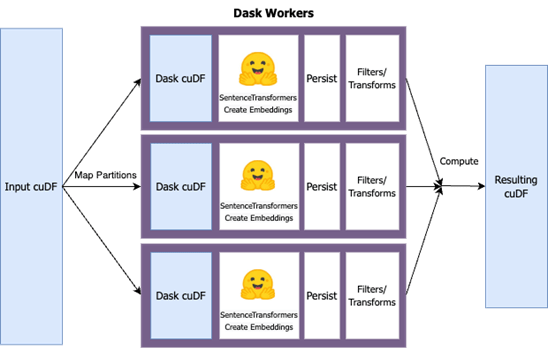
In the above workflow, a cuDF data frame of arXiv papers was loaded and partitions were created across a 3 node Dask cluster (with each worker node as an NVIDIA T4). In parallel, a user-defined function was applied to each data frame partition that processed and embedded the text using a Sentence Transformer model.
This approach provided linear scalability with the number of nodes in the Dask cluster. With 3 worker nodes, the total runtime decreased by a factor of 3.
Even with multi-GPU acceleration, data is mapped to and from machines. It’s heavily dependent on RAM, especially after the large embedding vectors have been created.
A few variations to consider:
- Load and process iterative batches of documents from a source database.
- Programmatically load partitions of data from a source database to several Dask workers for parallel execution.
- Perform streaming updates from the Dask workers directly to the vector database rather than loading embeddings back to single GPU RAM.
Call to action – it’s YOUR turn!
Inspired by the initial work on the arXiv search demo, Redis is officially launching a Vector Search Engineering Lab (Hackathon) co-sponsored by MLOps Community and Saturn Cloud.

This is the future. Vector search & document retrieval is now more accessible than ever before thanks to open-source tools like Redis, RAPIDS, Hugging Face, Pytorch, Kaggle, and more! Take the opportunity to get ahead of the curve and join in on the action. We’ve made it super simple to get started and acquire (or sharpen) an emerging set of skills.
In the end, you will get to showcase what you’ve built and win $$ prizes.
The hackathon will run from October 24 – November 4 and include folks across the globe, professionals and students alike. Register your team (up to 4 people) today! You don’t want to miss it.