

Welcome to Data Science Dojo’s weekly AI newsletter, “The Data-Driven Dispatch“.
Without Open-Source AI, there is no AI startup ecosystem, and no academic research on language models – Yann LeCun, Chief AI Scientist at Meta
Meta AI has consistently championed open-source AI, setting itself apart from giants like OpenAI, Google, and Microsoft from the outset.
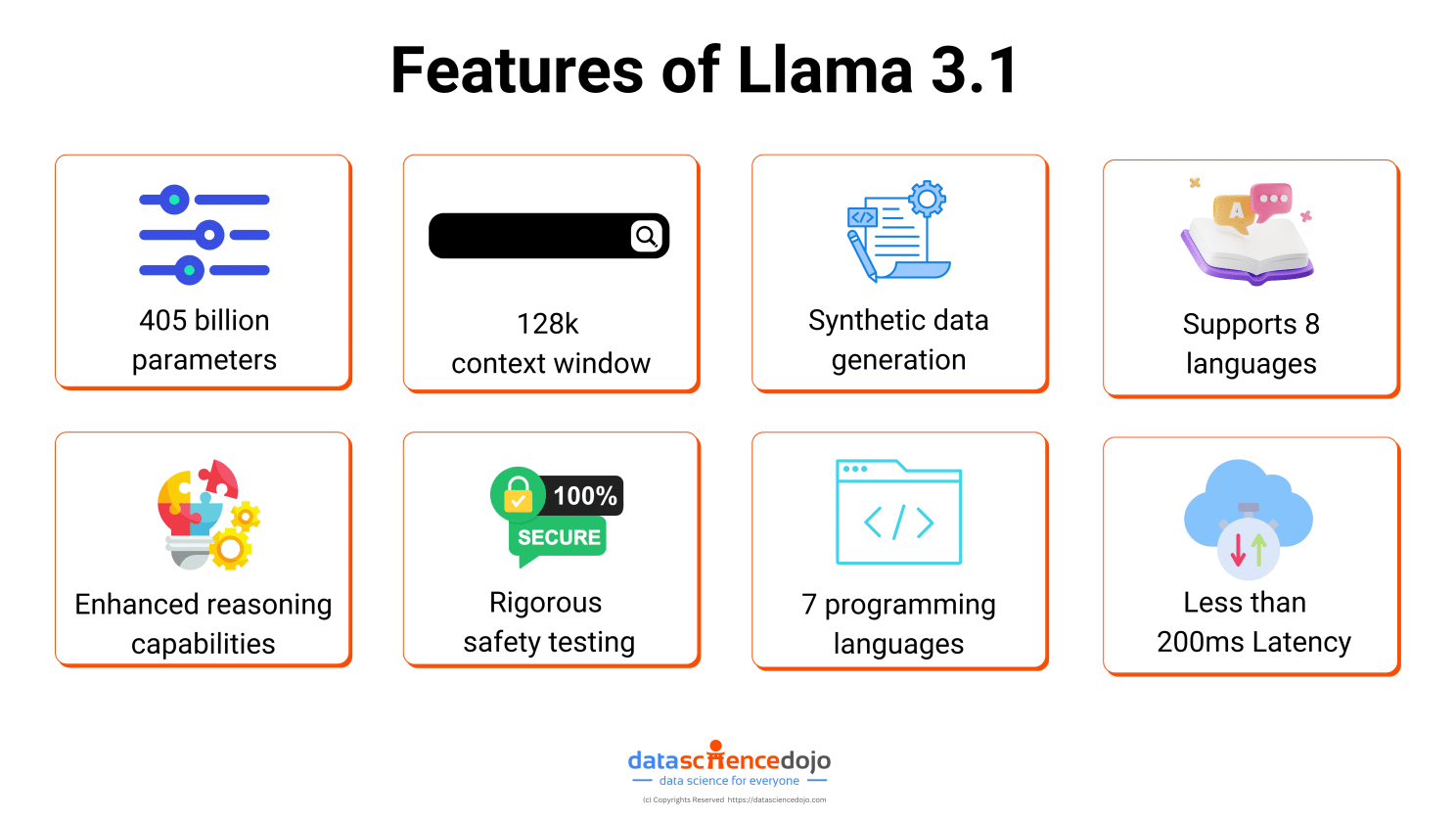
They’ve recently released Llama 3.1, a robust model with 405 billion parameters that surpasses Nvidia’s Nemotron and its 340 billion parameters.
This model is undoubtedly a gateway to massive innovation and democratization of AI globally.
Let’s dive deeper to understand how good Llama 3.1 is, and why it is a massive step in the AI world.

What is Llama 3.1
Llama 3.1 is the most powerful open-source language model that has been created, yet.
It has been released in 3 versions.
-
Llama 3.1 405b
-
Llama 3.1 70b
-
Llama 3.1 8b
Trained using a massive 16,000 GPUs, Llama 3.1 405B stands alone as a benchmark for flexibility, control, and advanced capabilities, rivaling even the most powerful proprietary models like GPT-4 Omni, Claude 3 Sonnet, and more.
Read more: Llama 3.1: All You Need to Know About Meta’s Latest LLM
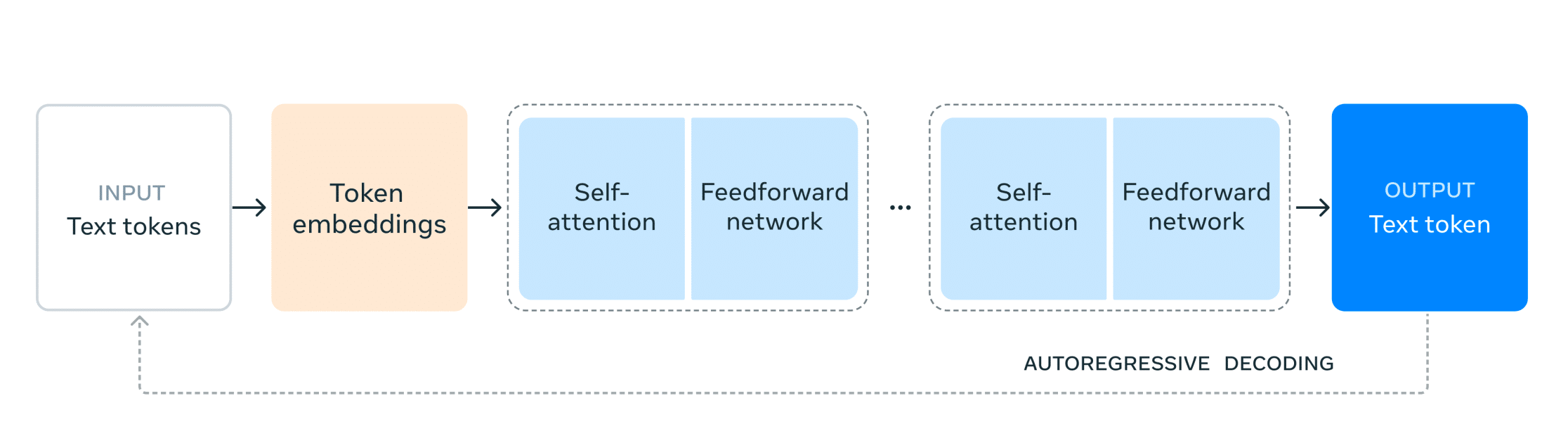
The Architecture of Llama 3.1
-
Decoder-only transformer: Llama 3.1 uses a transformer model that only consists of decoder layers, which is different from traditional transformer models that have both encoder and decoder layers.
-
Iterative post-training procedure: The model is fine-tuned using an iterative post-training procedure that involves supervised fine-tuning, rejection sampling, and direct preference optimization.
-
Quantization: The model is quantized from 16-bit (BF16) to 8-bit (FP8) numerics to reduce compute requirements and allow for faster inference.
Performance of the Model
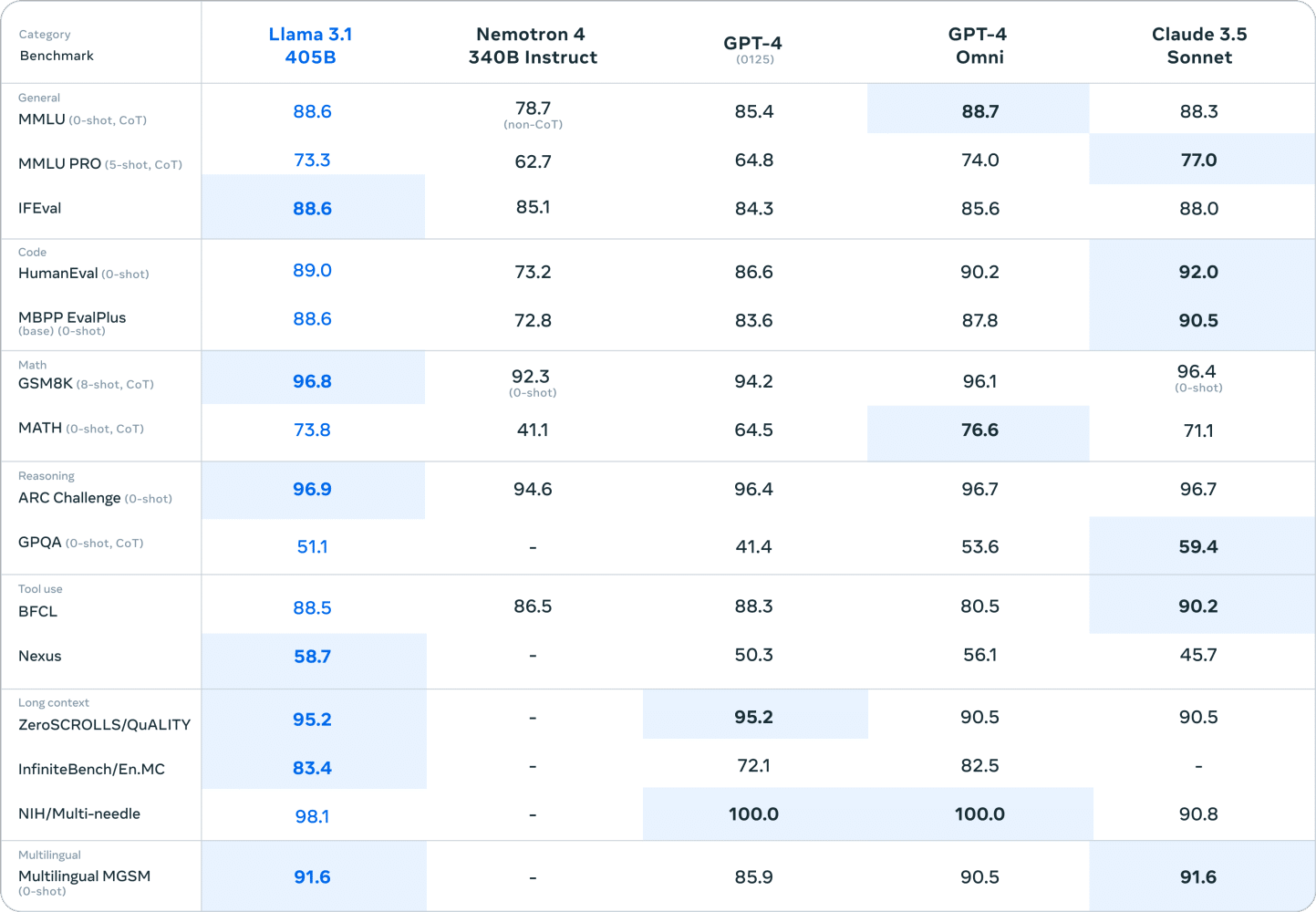
The performance of Llama 3.1 405B matches that of the top large language models, while its smaller versions compete strongly with well-known small language models.
Why is it Important?
Meta’s goal in building Llama 3.1 is clear: democratizing AI.
And they’ve proved it in many ways.
-
They’ve partnered with over 25 companies, including AWS, NVIDIA, Databricks, Groq, and more building a strong and vast ecosystem.
-
Builders can use Llama 3.1 openly to create any type of application using fine-tuning, real-time batch inference, retrieval-augmented generation (RAG), continual pre-training, and more.
-
Llama supports over 8 languages allowing people across the globe to build applications targeted for a variety of audiences.
-
The team is continuing to add to the Llama experience by working on different tools that can work with the model including custom AI agents, complex agentic frameworks, and more.
Why is Llama 3.1 Not Released in Europe?
Meta has withheld its multimodal models from Europe due to concerns over potential violations of EU privacy laws.
The company fears hefty fines and bans if it proceeds without addressing regulatory uncertainties surrounding data usage for AI model training.
This decision highlights the growing tension between tech giants and European regulators over AI development and data privacy.

How to Fine-Tune Llama Models for Domain-Specific Tasks
Do you want to build powerful applications using models like Llama 3, and more?
Here’s a video tutorial where Zaid Ahmed, a Data Scientist at Data Science Dojo teaches how to fine-tune Llama-2 on RunPod for different business use cases.
Whether you’re in finance, healthcare, or any other industry, learning how to fine-tune LLMs can give your business a significant competitive edge.
To connect with LLM and Data Science Professionals, join our discord server now!

Comment down if you can relate.


Learn to Build Powerful Applications Using LLMs
The emerging technology surrounding LLMs is making it easier and easier to build powerful AI applications that can solve huge business problems.

Invest your time in the LLM bootcamp today and gain the skills for tomorrow.

This week has been one of the craziest weeks in AI so far. Here’s a wrap of what happened.
-
Meta releases the biggest and best open-source AI model yet. Explore more
-
Mistral shocks with new open model Mistral Large 2, taking on Llama 3.1. Find out
-
OpenAI announces SearchGPT, its AI-powered search engine. Discover more
-
OpenAI unveils GPT-4o mini, a smaller and cheaper AI model. Find out
-
Stability AI steps into a new-gen AI dimension with Stable Video 4D. Explore more
-
DeepMind AI gets a silver medal at the International Mathematical Olympiad. Discover more