
Welcome to Data Science Dojo’s weekly newsletter, The Data-Driven Dispatch! In this week’s dispatch, we’ll share a generative AI learning pathway for you.
In mere months, Generative AI has surged forward with unstoppable momentum. McKinsey forecasts that Large Language Models (LLMs) can supercharge 15% of the US workforce’s tasks while preserving quality. But when we include software and tools harnessing LLMs, the figure soars high to 47-56%. Talk about bracing for a paradigm shift!
Naturally, organizations are racing to harness LLMs for boosted productivity, creating a high demand for LLM professionals.
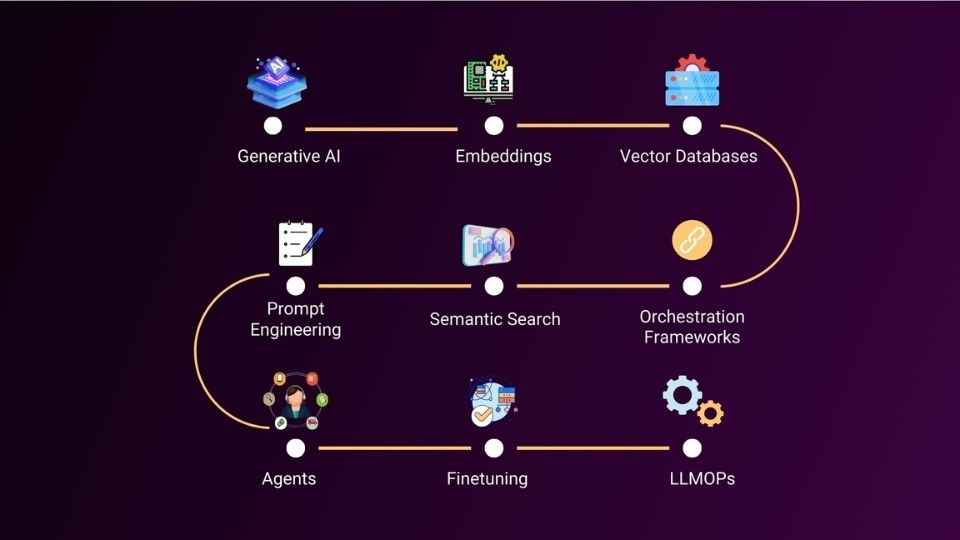
Now’s your chance to capitalize on this wave. Dive into these 9 essential domains that pave the path to LLM expertise. Ready for the journey? Let’s dig in!

Mapping Your Generative AI Learning Path
Your aim: Creating LLM-powered apps for any domain– be it customer support, content creation, or more. The challenge? Finding an effective and efficient path.
Enter the generative AI learning path. It covers vital areas to master on your journey to success.
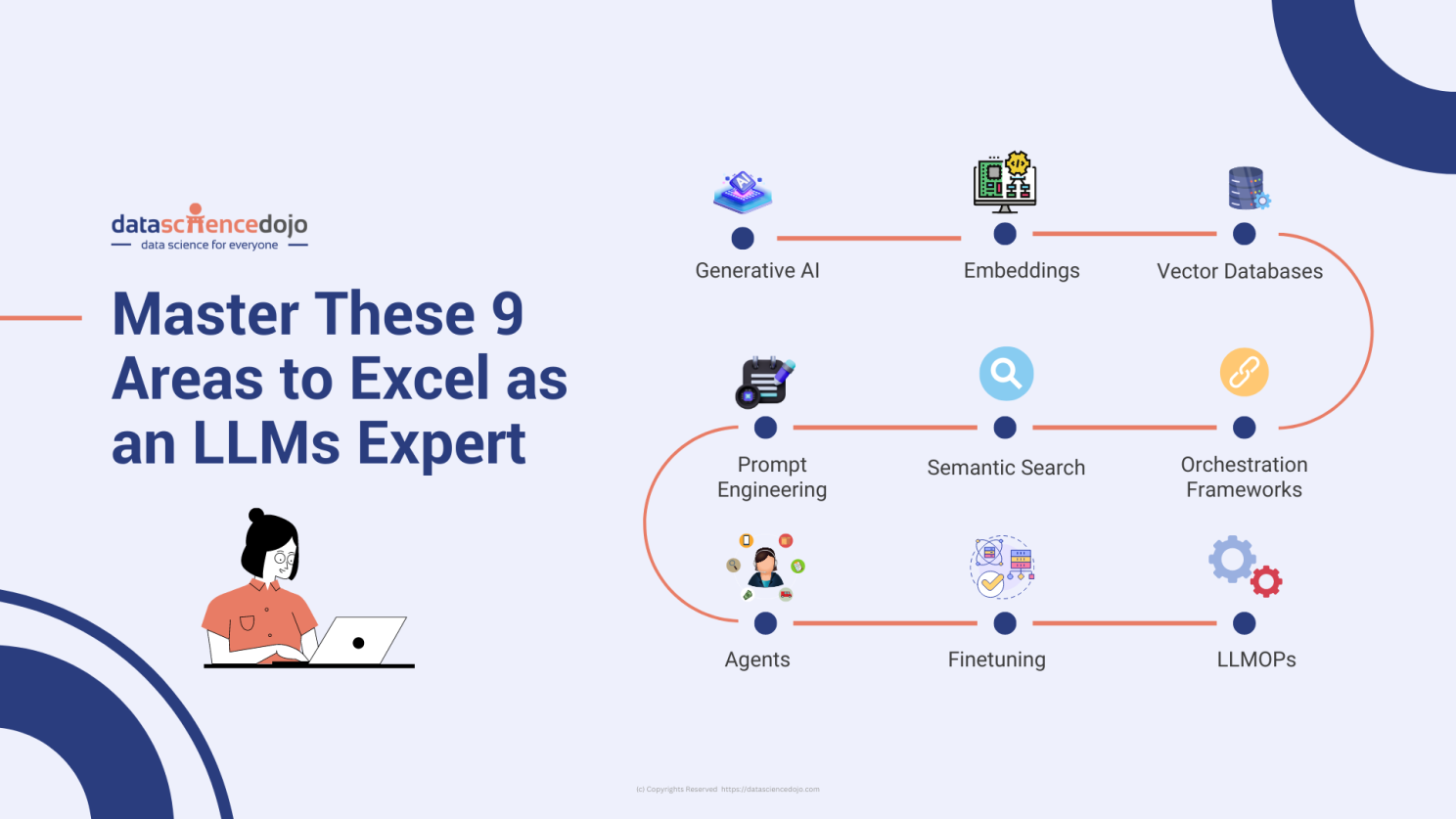
Let’s explore how you can conquer these domains step-by-step.
Generative AI and Large Language Models
Generative AI is a type of artificial intelligence that can generate new content, like humans based on LLM technology. There are mainly two types of generative AI models including text-based AI models such as ChatGPT and image-based AI models like MidJourney.
The building blocks for Large Language Models are essentially transformers and attention mechanisms. Here’s what they do:
- Transformers are a type of neural network architecture that is particularly well-suited for natural language processing (NLP) tasks. They are based on the attention mechanism, which allows them to learn long-range dependencies between different parts of a sequence.
- Attention is the mechanism that allows a neural network to focus on specific parts of an input sequence. This is important for NLP tasks because it allows the network to learn the relationships between different words in a sentence.
Explore more about Large Language Models.
Embeddings
The next step into your generative AI learning path is Embeddings.
Embeddings are simply numerical representations of words or concepts that capture their semantic relationships in a multi-dimensional space, enabling algorithms to understand and compare textual information.
In the case of GPT-3, each word or token is represented as a high-dimensional vector, strategically positioned in the vector space to capture word similarities. This arrangement aids the model in understanding word relationships, enabling the generation of coherent and contextually relevant text.
Here’s a detailed guide about embeddings and how they work:
Demystifying Embeddings 101: The Foundation of Large Language Models
Vector Databases
Vector databases store pre-computed vectors from a wide range of text, enabling efficient retrieval and comparison. When a query is made, the LLM can use these vectors to find relevant content quickly.
Read this interesting tutorial to get a complete hold of vector databases, how they work, and the most trusted ones in the market:
Prompt Engineering
Well-crafted prompts guide the LLM’s output. They provide context, instructions, or queries to influence the generated response’s relevance and accuracy.
However, prompt engineering gets complex when you want to drive highly specific and curated responses from an LLM model. What to do in such situations?
Hop on to this useful blog -> 10 Steps to Become a Prompt Engineer: A Comprehensive Guide.
Semantic Search
Ever imagined how ChatGPT understands exactly what you want?
Well, semantic search – a breakthrough in information retrieval – allows the system to do so. It grasps user intent beyond mere keywords. This happens through vector databases where data is encoded into vectors. When you query, the system seeks answers with high cosine similarity to your input vector. This approach ensures robust information retrieval, enhancing search precision and relevance for professionals
This video will explain the entire process in greater detail.
Orchestration Frameworks
Orchestration frameworks are responsible for allowing an LLM to answer queries based on the custom data that you provide to it. These frameworks handle the sequencing of inputs, responses, and actions, guaranteeing a smooth and contextually appropriate user experience.
LangChain is a prominent orchestration framework employed by companies to develop AI-powered applications. Learn about its pivotal role in LLM app development by exploring this article:
Learn the power of LangChain: A comprehensive guide to building custom Q&A chatbots
Agents
Agents serve as virtual conversational entities that bridge the interaction between users and the LLM. They leverage prompt engineering to guide the LLM’s output, ensuring contextually relevant and coherent interactions.
Imagine you’re using ChatGPT’s code interpreter to categorize your database entries by country. In this situation, an agent plays a crucial role by translating your human language into a specific SQL query. It then carries out the task and presents the results back to you in your natural language.
Explore a detailed LangChain agent tutorial demonstrating how they enable the creation of apps capable of dynamically selecting optimal sequences of actions.
It’s amazing how agents can be used to build LLM-powered applications that are more flexible, adaptive, and intelligent than traditional applications.
Finetuning Large Language Models
Pre-trained LLMs offer impressive capabilities like text generation, summarization, and coding. However, they aren’t universally fitting for every scenario especially when the information required is relevant to a specific domain.
Fine-tuning helps in specialized tasks. It involves enhancing the foundational model with specialized data in domains like medicine, finance, law, etc.
Read this article to get a deeper understanding of what fine-tuning is, and how it is carried out. -> Everything You Need to Know About Finetuning of LLMs.
LLMOps (Large Language Model Operations)
LLMOps(Large Language Model Operations) encompass a set of practices that handle the deployment, scaling, monitoring, and maintenance of the LLM application in production environments.
LLMOps ensures the application’s reliability, stability, and optimal performance over time. This involves tasks such as setting up infrastructure, managing server resources, implementing load balancing, monitoring response times, and addressing potential issues like model drift or degradation.
Wondering how LLMOps are different from MLOps? Find out here:
LLMOps demystified: Why it’s crucial and best practices for 2023
This concludes all the 9 essential domains that you must know in order to become an LLM expert.