

Context engineering is quickly becoming the new foundation of modern AI system design, marking a shift away from the narrow focus on prompt engineering. While prompt engineering captured early attention by helping users coax better outputs from large language models (LLMs), it is no longer sufficient for building robust, scalable, and intelligent applications. Today’s most advanced AI systems—especially those leveraging Retrieval-Augmented Generation (RAG) and agentic architectures—demand more than clever prompts. They require the deliberate design and orchestration of context: the full set of information, memory, and external tools that shape how an AI model reasons and responds.
This blog explores why context engineering is now the core discipline for AI engineers and architects. You’ll learn what it is, how it differs from prompt engineering, where it fits in modern AI workflows, and how to implement best practices—whether you’re building chatbots, enterprise assistants, or autonomous AI agents.
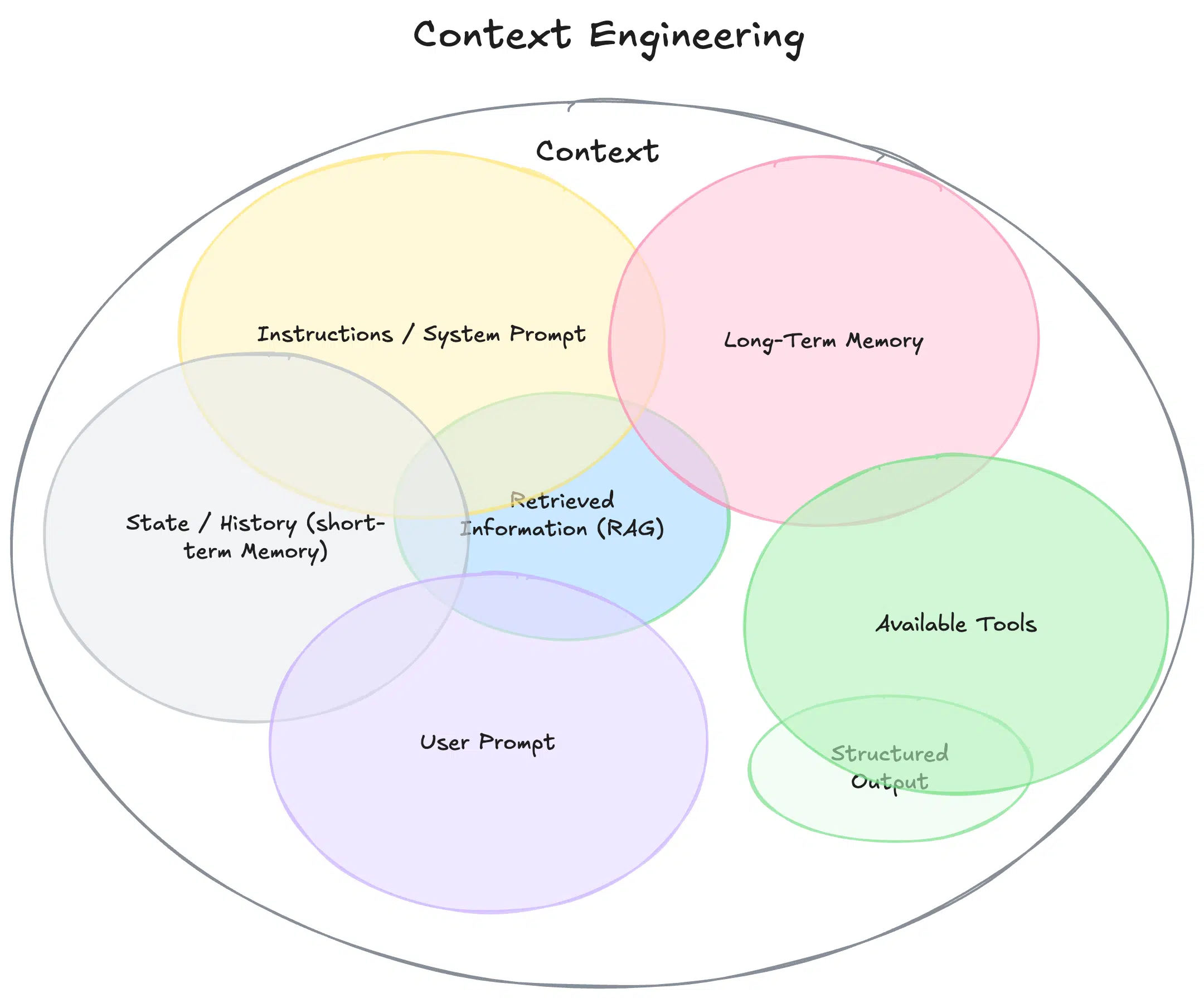
What is Context Engineering?
Context engineering is the systematic design, construction, and management of all information—both static and dynamic—that surrounds an AI model during inference. While prompt engineering optimizes what you say to the model, context engineering governs what the model knows when it generates a response.
In practical terms, context engineering involves:
- Assembling system instructions, user preferences, and conversation history
- Dynamically retrieving and integrating external documents or data
- Managing tool schemas and API outputs
- Structuring and compressing information to fit within the model’s context window
In short, context engineering expands the scope of model interaction to include everything the model needs to reason accurately and perform autonomously.
Why Context Engineering Matters in Modern AI
The rise of large language models and agentic AI has shifted the focus from model-centric optimization to context-centric architecture. Even the most advanced LLMs are only as good as the context they receive. Without robust context engineering, AI systems are prone to hallucinations, outdated answers, and inconsistent performance.
Context engineering solves foundational AI problems:
-
Hallucinations → Reduced via grounding in real, external data
-
Statelessness → Replaced by memory buffers and stateful user modelling
-
Stale knowledge → Solved via retrieval pipelines and dynamic knowledge injection
-
Weak personalization → Addressed by user state tracking and contextual preference modeling
-
Security and compliance risks → Mitigated via context sanitization and access controls
As Sundeep Teki notes, “The most capable models underperform not due to inherent flaws, but because they are provided with an incomplete, ‘half-baked view of the world’.” Context engineering fixes this by ensuring AI models have the right knowledge, memory, and tools to deliver meaningful results.
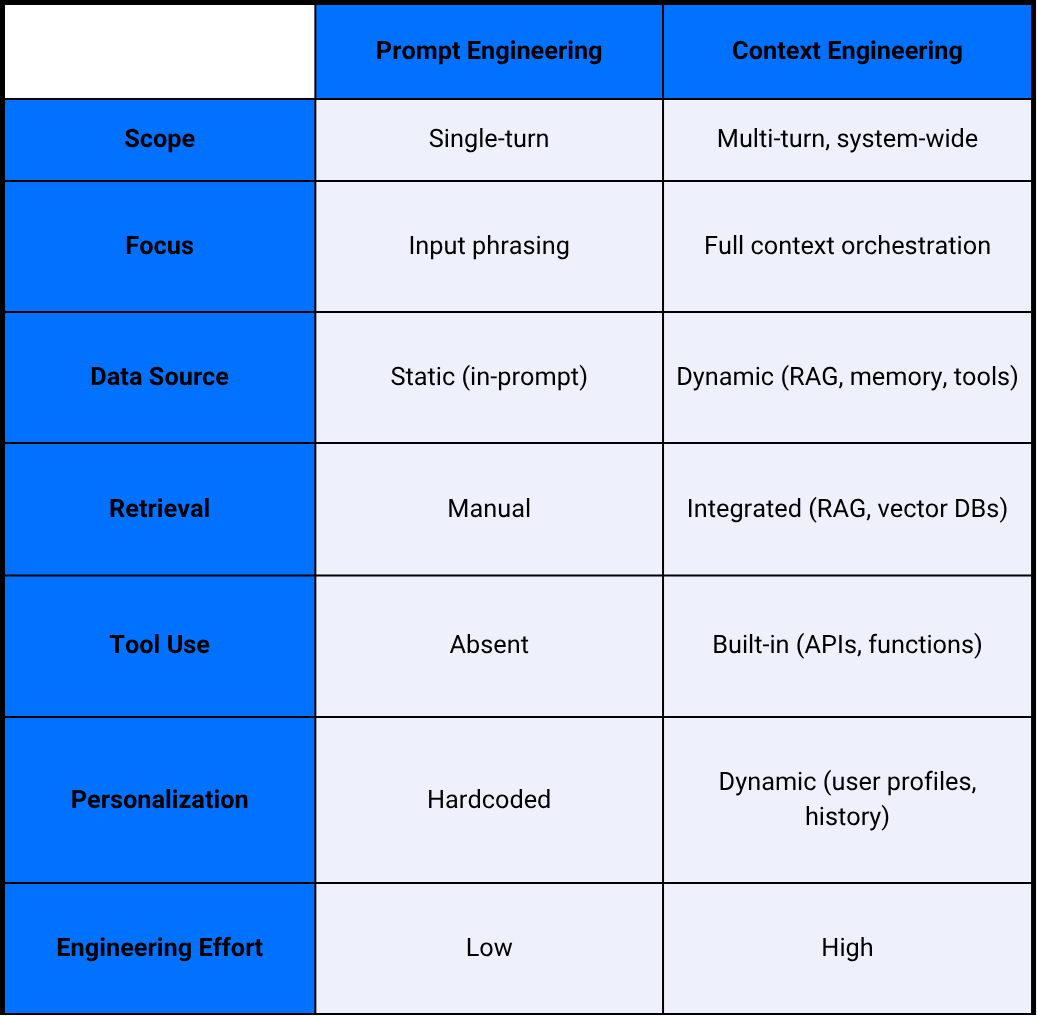
Context Engineering vs. Prompt Engineering
While prompt engineering is about crafting the right question, context engineering is about ensuring the AI has the right environment and information to answer that question. Every time, in every scenario.
Prompt Engineering:
- Focuses on single-turn instructions
- Optimizes for immediate output quality
- Limited by the information in the prompt
For a full guide on prompt engineering, check out Master Prompt Engineering Strategies
Context Engineering:
- Dynamically assembles all relevant background- the prompt, retrieved docs, conversation history, tool metadata, internal memory, and more
- Supports multi-turn, stateful, and agentic workflows
- Enables retrieval of external knowledge and integration with APIs
In short, prompt engineering is a subset of context engineering. As AI systems become more complex, context engineering becomes the primary differentiator for robust, production-grade solutions.
The Pillars of Context Engineering
To build effective context engineering pipelines, focus on these core pillars:
1. Dynamic Context Assembly
Context is built on the fly, evolving as conversations or tasks progress. This includes retrieving relevant documents, maintaining memory, and updating user state.
2. Comprehensive Context Injection
The model should receive:
-
Instructions (system + role-based)
-
User input (raw + refined)
-
Retrieved documents
-
Tool output / API results
-
Prior conversation turns
-
Memory embeddings
3. Context Sharing
In multi-agent systems, context must be passed across agents to maintain task continuity and semantic alignment. This requires structured message formats, memory synchronization, and agent protocols (e.g., A2A protocol).
4. Context Window Management
With fixed-size token limits (e.g., 32K, 100K, 1M), engineers must compress and prioritize information intelligently using:
-
Scoring functions (e.g., TF-IDF, embeddings, attention heuristics)
-
Summarization and saliency extraction
-
Chunking strategies and overlap tuning
Learn more about the context window paradox in The LLM Context Window Paradox: Is Bigger Always Better?
5. Quality and Relevance
Only the most relevant, high-quality context should be included. Irrelevant or noisy data leads to confusion and degraded performance.
6. Memory Systems
Build both:
-
Short-term memory (conversation buffers)
-
Long-term memory (vector stores, session logs)
Memory recall enables continuity and learning across sessions, tasks, or users.
7. Integration of Knowledge Sources
Context engineering connects LLMs to external databases, APIs, and tools, often via RAG pipelines.
8. Security and Consistency
Apply principles like:
-
Prompt injection detection and mitigation
-
Context sanitization (PII redaction, policy checks)
-
Role-based context access control
-
Logging and auditability for compliance
RAG: The Foundation of Context Engineering
Retrieval-Augmented Generation (RAG) is the foundational pattern of context engineering. RAG combines the static knowledge of LLMs with dynamic retrieval from external knowledge bases, enabling AI to “look up” relevant information before generating a response.
Get the ultimate RAG walk through in RAG in LLM – Elevate Your Large Language Models Experience
How RAG Works
-
Indexing:
Documents are chunked and embedded into a vector database.
-
Retrieval:
At query time, the system finds the most semantically relevant chunks.
-
Augmentation:
Retrieved context is concatenated with the prompt and fed to the LLM.
-
Generation:
The model produces a grounded, context-aware response.
Benefits of RAG in Context Engineering:
- Reduces hallucinations
- Enables up-to-date, domain-specific answers
- Provides source attribution
- Scales to enterprise knowledge needs
Advanced Context Engineering Techniques
1. Agentic RAG
Embed RAG into multi-step agent loops with planning, tool use, and reflection. Agents can:
-
Search documents
-
Summarize or transform data
-
Plan workflows
-
Execute via tools or APIs
This is the architecture behind assistant platforms like AutoGPT, BabyAGI, and Ejento.
2. Context Compression
With million-token context windows, simply stuffing more data is inefficient. Use proxy models or scoring functions (e.g., Sentinel, ContextRank) to:
-
Prune irrelevant context
-
Generate summaries
-
Optimize token usage
3. Graph RAG
For structured enterprise data, Graph RAG retrieves interconnected entities and relationships from knowledge graphs, enabling multi-hop reasoning and richer, more accurate responses.
Learn Advanced RAG Techniques in Large Language Models Bootcamp
Context Engineering in Practice: Enterprise
Enterprise Knowledge Federation
Enterprises often struggle with knowledge fragmented across countless silos: Confluence, Jira, SharePoint, Slack, CRMs, and various databases. Context engineering provides the architecture to unify these disparate sources. An enterprise AI assistant can use a multi-agent RAG system to query a Confluence page, pull a ticket status from Jira, and retrieve customer data from a CRM to answer a complex query, presenting a single, unified, and trustworthy response.
Developer Platforms
The next evolution of coding assistants is moving beyond simple autocomplete. Systems are being built that have full context of an entire codebase, integrating with Language Server Protocols (LSP) to understand type errors, parsing production logs to identify bugs, and reading recent commits to maintain coding style. These agentic systems can autonomously write code, create pull requests, and even debug issues based on a rich, real-time understanding of the development environment.
Hyper-Personalization
In sectors like e-commerce, healthcare, and finance, deep context is enabling unprecedented levels of personalization. A financial advisor bot can provide tailored advice by accessing a user’s entire portfolio, their stated risk tolerance, and real-time market data. A healthcare assistant can offer more accurate guidance by considering a patient’s full medical history, recent lab results, and even data from wearable devices.
Best Practices for Context Engineering
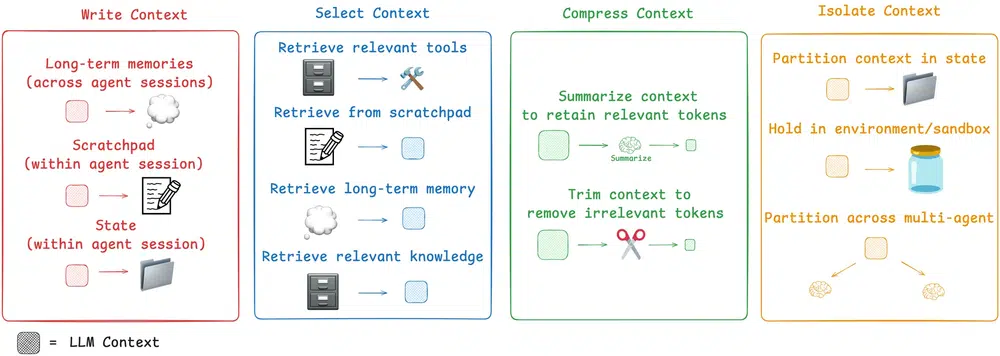
-
Treat Context as a Product:
Version control, quality checks, and continuous improvement.
-
Start with RAG:
Use RAG for external knowledge; fine-tune only when necessary.
-
Structure Prompts Clearly:
Separate instructions, context, and queries for clarity.
-
Leverage In-Context Learning:
Provide high-quality examples in the prompt.
-
Iterate Relentlessly:
Experiment with chunking, retrieval, and prompt formats.
-
Monitor and Benchmark:
Use hybrid scorecards to track both AI quality and engineering velocity.
If you’re a beginner, start with this comprehensive guide What is Prompt Engineering? Master GenAI Techniques
Challenges and Future Directions
-
Context Quality Paradox:
More context isn’t always better—balance breadth and relevance.
-
Context Consistency:
Dynamic updates and user corrections require robust context refresh logic.
-
Security:
Guard against prompt injection, data leakage, and unauthorized tool use.
-
Scaling Context:
As context windows grow, efficient compression and navigation become critical.
-
Ethics and Privacy:
Context engineering must address data privacy, bias, and responsible AI use.
Emerging Trends:
- Context learning systems that adapt context strategies automatically
- Context-as-a-service platforms
- Multimodal context (text, audio, video)
- Contextual AI ethics frameworks
Frequently Asked Questions (FAQ)
Q: How is context engineering different from prompt engineering?
A: Prompt engineering is about crafting the immediate instruction for an AI model. Context engineering is about assembling all the relevant background, memory, and tools so the AI can respond effectively—across multiple turns and tasks.
Q: Why is RAG important in context engineering?
A: RAG enables LLMs to access up-to-date, domain-specific knowledge by retrieving relevant documents at inference time, reducing hallucinations and improving accuracy.
Q: What are the biggest challenges in context engineering?
A: Managing context window limits, ensuring context quality, maintaining security, and scaling context across multimodal and multi-agent systems.
Q: What tools and frameworks support context engineering?
A: Popular frameworks include LangChain, LlamaIndex, which offer orchestration, memory management, and integration with vector databases.
Conclusion: The Future is Context-Aware
Context engineering is the new foundation for building intelligent, reliable, and enterprise-ready AI systems. By moving beyond prompt engineering and embracing dynamic, holistic context management, organizations can unlock the full potential of LLMs and agentic AI.
Ready to elevate your AI strategy?
- Explore Data Science Dojo’s LLM Bootcamp for hands-on training.
- Stay updated with the latest in context engineering by subscribing to leading AI newsletters and blogs.
The future of AI belongs to those who master context engineering. Start engineering yours today.