In the first part of this series, we dug into why the KV cache exists, why it matters, and why it dominates the runtime characteristics of LLM inference. In Part 2, we’re going deeper into the systems-level issues that the KV cache introduces, particularly memory fragmentation and how this motivated the design of a new memory architecture for attention: paged attention, the foundational idea behind the vLLM inference engine.
Before diving into paged attention, you may want to revisit Part 1 of this series, where we unpack the fundamentals of the KV cache and why it dominates LLM memory behavior: KV Cache — How to Speed Up LLM Inference.
This post has one objective: make the vLLM paper’s ideas feel intuitive. The original work is dense (and excellent), but with the right framing, paged attention is actually a very natural idea — almost inevitable in hindsight. It’s essentially applying well-established operating systems concepts (paging, copy-on-write, block tables) to the KV cache problem that LLMs face. Once you see it, you can’t unsee it.
Let’s start with the root cause.
The Real Problem: KV Cache Is Huge, Dynamic, and Unpredictable
The KV cache holds one Key vector and one Value vector for every token in a sequence, across every layer and every attention head. For a typical 7B–13B model, this quickly grows into hundreds of megabytes per request. But the real challenge isn’t just size, it’s unpredictability.
Different requests vary wildly in:
prompt length,
generation length,
decoding strategy (sampling, beam search),
number of branch paths,
when they finish.
An LLM serving system cannot know in advance how long a request will run or how many tokens it will eventually accumulate. Yet GPUs require strict, contiguous, pre-allocated tensor layouts for optimal kernel execution. This mismatch — dynamic workload vs. static memory assumptions, is the source of nearly all downstream problems.
The traditional answer is: “Allocate a single contiguous tensor chunk large enough for the maximum possible length.”
And this is where the trouble starts.
How Contiguous Allocation Breaks GPU Memory: Internal and External Fragmentation
To understand why this is harmful, picture the GPU memory as a long shelf. Each LLM request needs to reserve a large rectangular box for its KV cache, even if the request only ends up filling a fraction of the box. And since every box must be contiguous, the allocator cannot place a request’s box unless it finds one uninterrupted region of memory of the right size.
source: https://arxiv.org/pdf/2309.06180
This creates three distinct kinds of waste, all described in the vLLM paper:
1. Reserved but Unused Slots
If the system allocates space for 2,048 possible tokens, but the request only produces 600 tokens, the remaining 1,448 positions are permanently wasted for the lifetime of that request. These unused slots cannot be repurposed.
2. Internal Fragmentation
Even within a request’s reserved slab, the actual KV cache grows token-by-token. Since the final length is unknown until the request finishes, internal fragmentation is unavoidable — you always over-allocate.
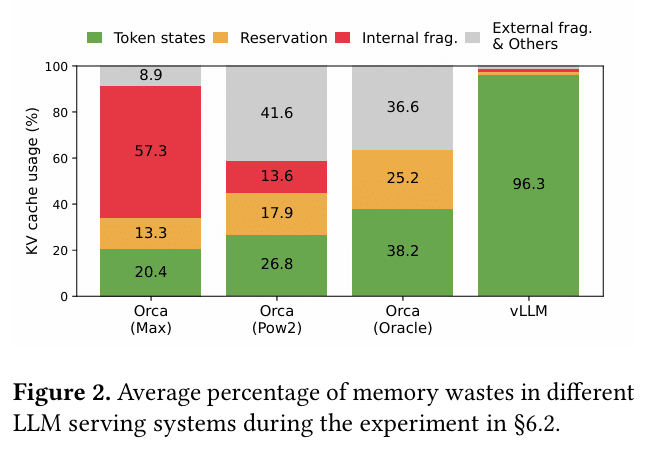
The paper observes that many real-world requests only use 20–30% of their allocated capacity. That means 70–80% of the reserved memory is dead weight for most of the request’s lifetime.
Even worse, after many different requests have allocated and freed slabs of different sizes, the GPU memory layout ends up looking like Swiss cheese. The allocator may have plenty of free space in total, but not enough contiguous free space to fit a new request’s slab.
This causes new requests to fail even though the GPU technically has enough memory in aggregate.
The vLLM paper measures that only 20–38% of the allocated KV cache memory is actually used in existing systems. That’s an astonishingly low utilization for the largest memory component in LLM inference.
source: https://arxiv.org/pdf/2309.06180
This is the core problem: even before we run out of computation or bandwidth, we run out of contiguous GPU memory due to fragmentation.
Fine-Grained Batching: A Great Idea That Accidentally Worsens Memory Pressure
Before paged attention arrived, researchers attempted to improve throughput using smarter batching. Two techniques are important here:
These mechanisms work at token-level granularity instead of request-level granularity. Instead of waiting for entire requests to complete before adding new ones, the server can add or remove sequences each decoding iteration. This dramatically improves compute utilization because it keeps the GPU busy with fresh work every step.
In fact, iteration-level batching is almost required for modern LLM serving: it avoids the inefficiency where one long-running request delays the whole batch.
But here’s the catch that the vLLM paper highlights:
Fine-grained batching increases the number of concurrently active sequences.
And therefore:
Every active sequence maintains its own full, contiguous KV cache slab.
So while compute utilization goes up, memory pressure skyrockets.
If you have 100 active sequences simultaneously interleaved at the decoding step, you effectively have 100 large, partially empty, but reserved KV cache slabs sitting in memory. Fragmentation becomes even worse, and the chance of running out of contiguous space increases dramatically.
In other words:
Fine-grained batching solves the compute bottleneck but amplifies the memory bottleneck.
The system becomes memory-bound, not compute-bound.
This brings us to the core insight in the vLLM paper.
“Why not treat the KV cache like an operating system treats virtual memory?”
In other words:
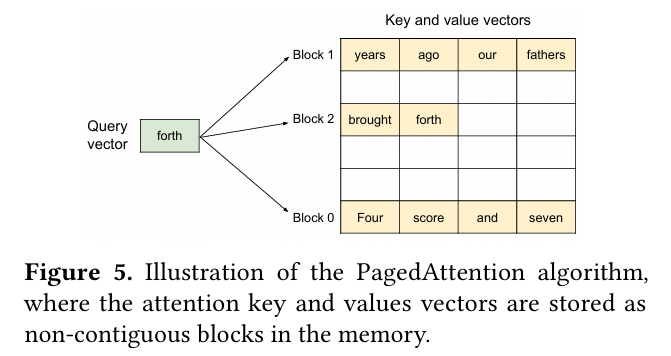
Break memory into fixed-size blocks (like OS pages).
Each block stores KV vectors for a small number of tokens (e.g., 16 tokens).
Maintain a mapping from logical blocks (the sequence’s view) to physical blocks (actual GPU memory).
Blocks can live anywhere in GPU memory — no need for contiguous slabs.
Blocks can be shared across sequences.
Use copy-on-write to handle divergence.
Reclaim blocks immediately when sequences finish.
This block-based KV representation is what the paper names paged attention.
source: https://arxiv.org/pdf/2309.06180
You might think: “Doesn’t attention require K and V to be in one contiguous array?” Mathematically, no — attention only needs to iterate over all previous K/V vectors. Whether those vectors live contiguously or are chunked into blocks is irrelevant to correctness.
This means we can rewrite attention in block form: for each block:
read its Keys
compute dot-product scores with the Query
apply softmax normalization
read block’s Values
accumulate outputs
The underlying math is identical; only the memory layout changes.
Paged attention eliminates the need for large contiguous slabs. Each sequence grows its KV cache block-by-block, and each block can be placed anywhere in GPU memory. There is no long slab to reserve, so external fragmentation largely disappears.
Internal fragmentation also collapses.
The only unused memory per sequence is inside its final partially filled block — at most the space for block_size − 1 tokens. If the block size is 16 tokens, the maximum internal waste is 15 tokens. Compare that to 1,000+ tokens wasted in the old approach.
Reserved-but-unused memory disappears entirely.
There are no pre-allocated full-size slabs. Blocks are allocated on demand.
Memory utilization becomes extremely predictable.
For N tokens, the system allocates exactly ceil(N / block_size) blocks. Nothing more.
This is the same structural benefit that operating systems gain from virtual memory: the illusion of a large contiguous space, backed by small flexible pages underneath.
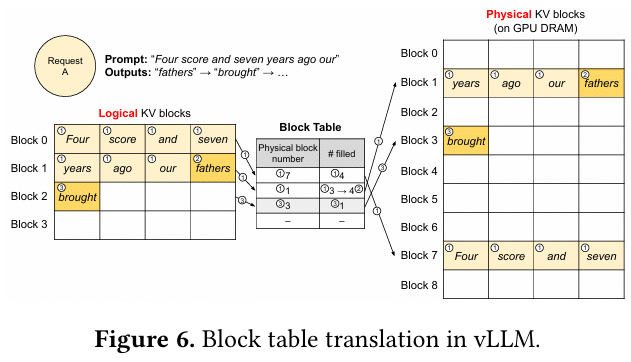
Logical Blocks, Physical Blocks, and Block Tables
The vLLM architecture uses a simple but powerful structure to track blocks:
Logical blocks: the sequence’s view of its KV cache
Physical blocks: actual GPU memory chunks
Block table: a mapping from logical indices to physical block IDs
This is visually similar to the page table in any OS textbook.
When a sequence generates tokens:
It writes K/V into the current physical block.
If the block fills up, vLLM allocates a new one and updates the table.
If two sequences share a prefix, their block tables point to the same physical blocks.
All of this is efficient because the attention kernel is redesigned to loop over blocks instead of a single contiguous tensor.
Sharing and Copy-on-Write: Why Paged Attention Helps Beam Search and Sampling
This is one of the most elegant parts of the paper.
When doing:
beam search, or
parallel sampling, or
agentic branching
many sequences share long prefixes.
Under the traditional contiguous layout, you either:
duplicate the KV cache for each branch (expensive), or
compromise batch flexibility (restrictive).
With paged attention:
multiple sequences simply reference the same physical blocks,
and only when a sequence diverges do we perform copy-on-write at the block level.
Copying one block is far cheaper than copying an entire slab. This leads to substantial memory savings — the paper reports that shared prefixes during beam search reduce KV memory usage by up to 55% in some scenarios.
How the Paged Attention Kernel Works (Intuitive View)
Even though the memory layout changes, the math of attention remains untouched.
Here’s the intuitive flow inside the kernel:
Take the Query for the new token.
Loop over each logical block of previous tokens.
For each block:
Look up the physical block address through the block table.
Load the Keys in that block.
Compute attention scores (Q · Kᵀ).
Load the Values in that block.
Multiply and accumulate.
Normalize across all blocks.
Produce the final attention output.
Kernel optimizations in the paper include:
fused reshape-and-write kernels for block writes,
block-aware attention kernels,
efficient memory coalescing strategies,
minimizing per-block overhead.
While the block-aware kernels are slightly slower than fully contiguous ones, the system throughput increases dramatically because vLLM can batch far more requests simultaneously.
Paging Enables Swapping and Recomputing KV Blocks
Once KV data is broken into blocks, vLLM gains a capability that is nearly impossible with contiguous slabs: flexible eviction policies.
If GPU memory is full, vLLM can:
swap blocks to CPU memory, or
drop blocks entirely and recompute them if needed,
evict entire sequences’ blocks immediately.
The paper notes that recomputation can be faster than swapping small blocks over PCIe for certain workloads — an insight that wouldn’t be possible without block-level memory.
source: https://arxiv.org/pdf/2309.06180
This is a fundamental shift in how LLM serving systems deal with memory pressure.
Why Block Size Matters
Block size is the main tuning knob. A smaller block size:
reduces internal fragmentation,
increases sharing granularity,
but increases kernel overhead,
and increases the number of memory lookups.
A larger block size:
improves kernel efficiency,
but wastes more memory.
The vLLM authors test many configurations and find that around 16 tokens per block strikes a balance. But workloads differ, and this is a tunable dimension in future variations of paged attention.
Paged Attention vs. Traditional Systems: Throughput Gains
While paged attention increases per-kernel latency (~20–26% overhead), the end-to-end throughput improves by 2–4× because:
batches become much larger,
memory is no longer the bottleneck,
iteration-level scheduling can run without exploding memory use,
shared prefixes do not duplicate KV cache,
requests no longer fail due to lack of contiguous space.
This is the core result: paged attention trades tiny per-kernel overhead for massive system-wide gains.
Why Paged Attention Works: A Systems Perspective
The beauty of paged attention is that it doesn’t try to fight the GPU or the attention kernel. Instead, it sidesteps the original constraint entirely.
Traditional systems try to squeeze dynamic workloads into rigid, contiguous layouts and then fight the consequences (compaction, large reservations, fragmentation). Paged attention flips the model: accept that token sequences grow unpredictably, and design memory as though you were building a small operating system for the KV cache.
Once you see it through that lens, the entire design becomes obvious:
block tables
shared blocks
copy-on-write
demand-based allocation
block-level eviction
block-level recomputation
fragmentation elimination
higher effective batch sizes
Paged attention is the kind of engineering idea that feels both novel and inevitable.
Practical Lessons for Engineers Using Paged Attention
If you’re building LLM services or agentic systems, here are some practical takeaways:
Measure how much of your KV cache memory is actually used. Traditional systems waste the majority of it.
If your batch sizes are small because of memory, paged attention will help dramatically.
If you rely on beam search, multi-sampling, or agent branching, block-level prefix sharing is a huge win.
If you use iteration-level scheduling, you need a KV cache representation that doesn’t explode memory.
Understand block size trade-offs (paging is not free; kernel overhead exists).
Consider recomputation as a valid alternative to swapping for certain workloads.
Conclusion: Paged Attention as the New Default Mental Model
Paged attention is not just another incremental optimization. It is a new lens for thinking about how KV cache memory should be managed in autoregressive models.
The math of attention stays the same. What changes is everything around it — the memory layout, the allocator, the scheduler, and the way prefix sharing works. The payoff is enormous: far less waste, far more flexibility, and significantly higher throughput. In many ways, paged attention is to KV memory what virtual memory was to general-purpose computing: a foundational concept that unlocks better utilization of hardware resources.
If you’re serving LLMs in production — or building agentic systems that rely on long-running multi-step reasoning — paged attention is now a core idea you should keep in your toolkit.
Ready to build robust and scalable LLM Applications? Explore Data Science Dojo’s LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI systems.
Stay tuned — this is part of a 3-part deep-dive series. In the upcoming posts, we’ll unpack Radix Attention, and a few other emerging techniques that push context efficiency even further. If you’re serious about building fast, scalable LLM systems, you’ll want to check back in for the next installments.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.