

This Azure tutorial will walk you through deploying a predictive model in Azure Machine Learning, using the Titanic dataset.
The classification model, covered in this article, uses the Titanic dataset to predict whether a passenger will live or die, based on demographic information. We’ve already built the model for you and the front-end UI. This tutorial will show you how to customize the Titanic model we built and deploy your own version.
MLaaS overview:
About the data
The Titanic dataset’s complexity scales up with feature engineering, making it one of the few datasets good for both beginners and experts. There are numerous public resources to obtain the Titanic dataset, however, the most complete (and clean) version of the data can be obtained from Kaggle, specifically their “train” data.
The “train” Titanic data ships with 891 rows, each one about a passenger on the RMS Titanic, the night of the disaster. The dataset also has 12 columns that record attributes of each passenger’s circumstances and demographics such as passenger id, passenger class, age, gender, name, number of siblings and spouses aboard, number of parents and children aboard, fare, ticket number, cabin number, port of embarkation, and whether or not they survived.
For additional reading, a repository of biographies about everyone aboard the RMS Titanic can be found here (complete with pictures).
Getting the experiment
About the Titanic Survival User Interface
From the dataset, we will build a predictive model and deploy the model in AzureML as a web service. Data Science Dojo has built a front-end UI to interact with such a web service.
Click on the link below to view a finished version of this deployed web service.
Use the app to see what your chance of survival might have been if you were on the Titanic. Play around with the different variables. What factors does the model deem important in calculating your predicted survival rate?
The following tutorial will walk you through how to deploy a titanic prediction model as a web service.
Get an Azure ML account
This MLaaS tutorial assumes that you already have an AzureML workspace. If you do not, please visit the following link for a tutorial on how to create one.
Please note that an Azure ML 88-hourfree trial does not have the option of deploying a web service.
Clone the experiment
For this MLaaS tutorial, we will provide you with the completed experiment by letting you clone ours. If you are curious about how we created the experiment, please view our companion tutorial where we talk about where we talk about the process of data mining.
Our experiment is hosted in the Azure ML public gallery. Navigate to the experiment by clicking on the link below or by clicking “Clone ont to Azure ML” within the Titanic Survival Predictor web page itself. The Azure ML Gallery is a place where people can showcase their experiments within the Azure ML community.
Gallery Titanic Experiment
Click on the “open in studio” button.
The experiment and dataset will be copied to your studio workspace. You should now see a bunch of modules linked together in a workflow. However, since we have not run the experiment, the workflow is only a set of instructions that Azure ML will use to build your models. We will have to run the experiment to produce anything.
Click the “run” button at the bottom middle of the AzureML window.
This will execute the workflow that is present within the experiment. The experiment will take about 2 minutes and 30 seconds to finish running. Wait until every module has a green checkmark next to it. This indicates that each module has finished running.
MLaaS predictive model evaluation and deployment
Select an algorithm
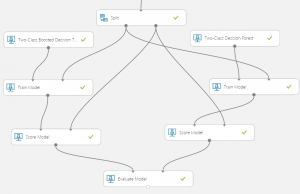
You may have noticed that the cloned experiment shipped with two predictive models–two different decision forests. However, because we can only deploy one predictive model, we should see which performs better. Right click on the output node of the evaluate model module and click “visualize.”
Evaluate your model
For the purpose of this tutorial, we will define the “better” performing model as the one that scored a higher RoC AuC. We will gloss over evaluating performance metrics of classification models since that would require a longer, more in-depth discussion.
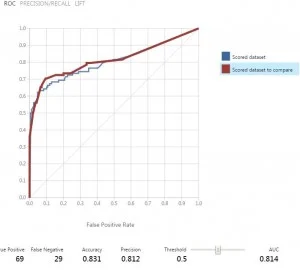
In the evaluate model module, you will see an “ROC” graph with a blue and red line graphed on it. The blue line represents the RoC performance of the model on the left and the red line represents the performance of the model on the right.
The higher the curve is on the graph, the better the performance. Since the red curve, the right model is higher on the graph than the blue curve, we can say that the right model is the better-performing model in this case. We will now deploy the corresponding decision tree model.
Deploy the experiment
Before deployment, all modules must have a green check mark next to them.
To deploy the selected decision forest model, select the “train model module” on the right.
While that is selected, hover over the “setup web service” button on the bottom middle of the screen. A pull-up menu will appear. Select “predictive web service”.
Azure ML will now remove and consolidate unnecessary modules, then it will automatically save the predictive model as a trained model and set up web service inputs and outputs.
Drop the response class
Our web service is almost complete. However, we need to tune the logic behind the web service function. The score model module is the module that will execute the algorithm against a given dataset. The score model module can also be called the “prediction module” because that is what happens when you apply a trained algorithm against a dataset.
You will notice that the score model module also takes in a dataset on the right input node. When deploying a predictive model, the score model module will need a copy of the required schema. The dataset used to train the model is fed back into the score model module because that is the schema that our trained algorithm currently knows.
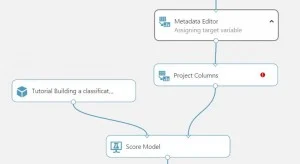
However, that schema also holds our response class “survived,” the attribute that we are trying to predict. We must now drop the survived column. To do this we will use the “project columns” module. Search for it in the search bar on the left side of the AzureML window, then drag it into the workspace.
Replicate the picture on the left by connecting the last metadata editor’s output node to the input of the new project columns module. Then connect the output of the new project columns module with the right input of the score model module.
Select the project columns module once the connections have been made. A “Properties” window will appear on the right side of the AzureML window. Click on “launch column selector.”
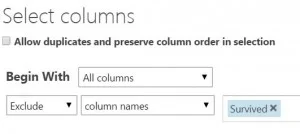
To drop the “Survived” column we will “Begin with: All Columns,” then choose to “Exclude” by “column names,” “Survived.”
Reroute web service input
We must now point our web service input in the correct direction. The web service input is currently pointing to the beginning of the workflow where data was cleaned, columns were renamed, and columns were dropped. However, the form on the Titanic Prediction App will do the cleansing for you.
Let’s reroute the web service input to point directly at our score model module. Drag the web service input module down toward the score model module and connect it to the right input node of the score model (the same node that the newly added project columns module is also connected to).
Deploy your model
Once all the rerouting has been done, run your experiment one last time. A “Deploy Web Service” button should now be clickable at the bottom middle of the Azure ML window. Click this and AzureML will automatically create and host your web service API with your own endpoints and post-URL.

Exposing the deployed webservice
Test your web service
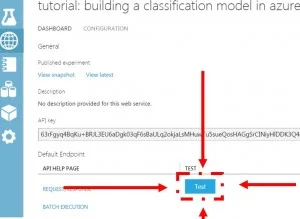
You should now be on the web deployment screen for your web service. Congratulations! You are now in possession of a web service that is connected to a live predictive model. Let’s test this model to see if it behaves properly.
Click the “test” button in the middle of the web deployment screen. A window with a form should pop up. This form should look familiar because it is the same form that the Titanic Predictor App was showing you.
Send the form a few values to see what it returns. The predictions will come in JSON format. The last number in JSON is the prediction itself, which should be a decimal akin to a percentage. This percentage is the predicted likelihood of survival based upon the given parameters, or in this case the passenger’s circumstances while aboard the Titanic.
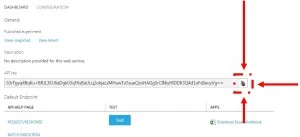
Find your API key
The API key is located on the web deployment screen, above the test button that you clicked on earlier. The API key input box comes with a copy to clipboard button, click on that button to copy the key. Paste the key into the “Add Your Own Model” page.
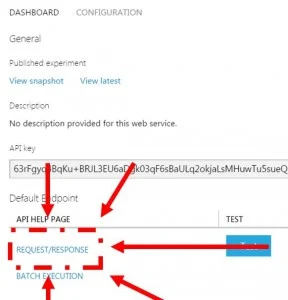
Get your post URL
To grab the post-URL, click on the “REQUEST/RESPONSE” button, to the left of the test button. This will take you to the API help page.
Under “Request” and to the right of “POST” is the URL. Copy and paste this URL into the “Add Your Own Model” form.

Enjoy and share
You now have your very own web service! Remember to save the URL because it is your own web page that you may share with others.
If you have a free trial Azure ML account please note that your web service may discontinue when your free trial subscription ends.
Written by Phuc Duong