

GPT-3.5 and other large language models (LLMs) have transformed natural language processing (NLP). Trained on massive datasets, LLMs can generate text that is both coherent and relevant to the context, making them invaluable for a wide range of applications.
Learning about LLMs is essential in today’s fast-changing technological landscape. These models are at the forefront of AI and NLP research, and understanding their capabilities and limitations can empower people in diverse fields.
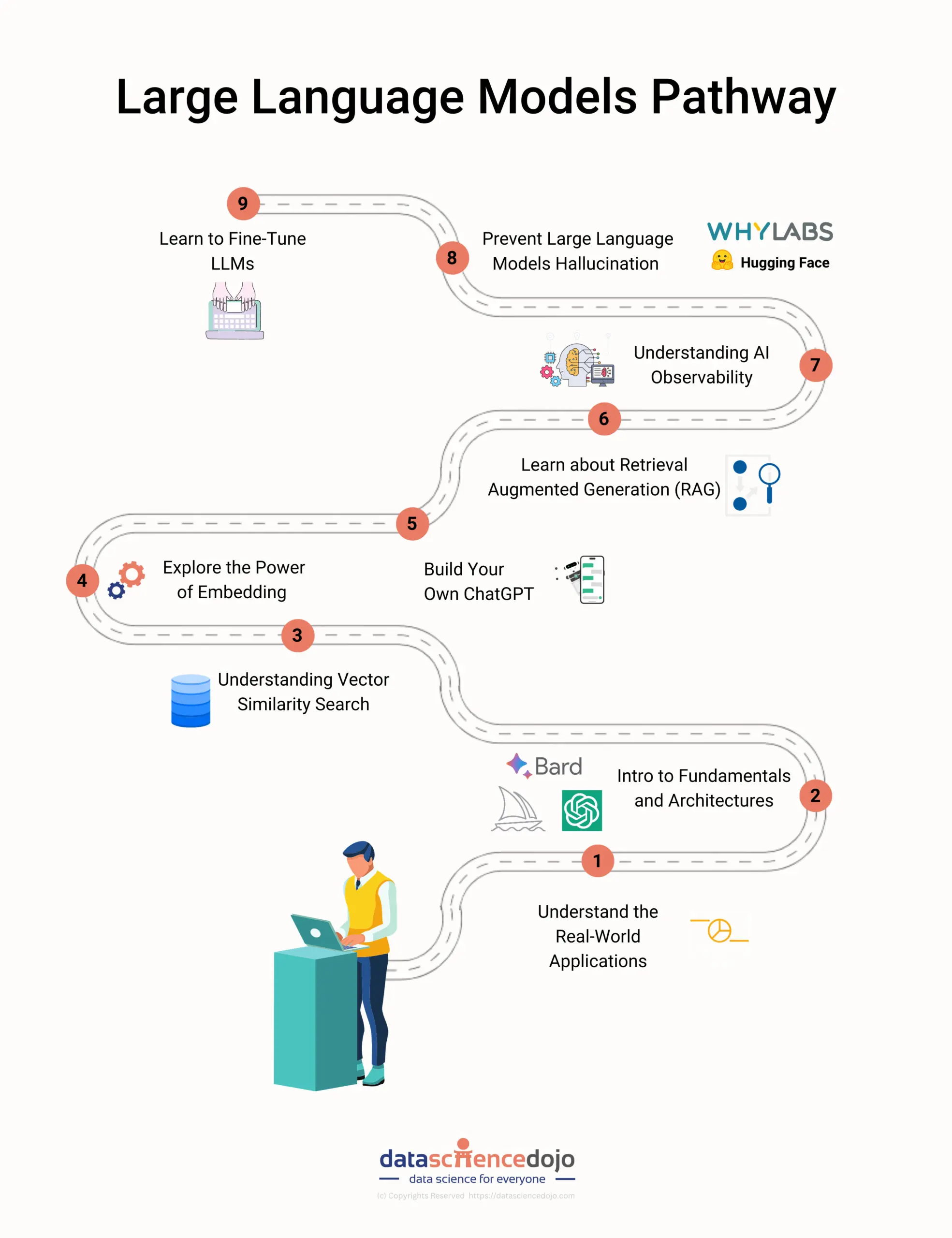
This blog lists steps and several tutorials that can help you get started with large language models. From understanding large language models to building your own ChatGPT, this roadmap covers it all.
Want to build your own ChatGPT? Checkout our in-person Large Language Model Bootcamp.
Step 1: Understand the real-world applications
Building a large language model application on custom data can help improve your business in a number of ways. This means that LLMs can be tailored to your specific needs. For example, you could train a custom LLM on your customer data to improve your customer service experience.
The talk below will give an overview of different real-world applications of large language models and how these models can assist with different routine or business activities.
Step 2: Introduction to fundamentals and architectures of LLM applications
Applications like Bard, ChatGPT, Midjourney, and DallE have entered some applications like content generation and summarization. However, there are inherent challenges for a lot of tasks that require a deeper understanding of trade-offs like latency, accuracy, and consistency of responses.
Any serious applications of LLMs require an understanding of nuances in how LLMs work, including embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more.
This talk will introduce you to the fundamentals of large language models and their emerging architectures. This video is perfect for anyone who wants to learn more about Large Language Models and how to use LLMs to build real-world applications.
Step 3: Understanding vector similarity search
Traditional keyword-based methods have limitations, leaving us searching for a better way to improve search. But what if we could use deep learning to revolutionize search?

Imagine representing data as vectors, where the distance between vectors reflects similarity, and using Vector Similarity Search algorithms to search billions of vectors in milliseconds. It’s the future of search, and it can transform text, multimedia, images, recommendations, and more.
The challenge of searching today is indexing billions of entries, which makes it vital to learn about vector similarity search. This talk below will help you learn how to incorporate vector search and vector databases into your own applications to harness deep learning insights at scale.
Step 4: Explore the power of embedding with vector search
The total amount of digital data generated worldwide is increasing at a rapid rate. Simultaneously, approximately 80% (and growing) of this newly generated data is unstructured data—data that does not conform to a table- or object-based model.
Examples of unstructured data include text, images, protein structures, geospatial information, and IoT data streams. Despite this, the vast majority of companies and organizations do not have a way of storing and analyzing these increasingly large quantities of unstructured data.

Embeddings—high-dimensional, dense vectors that represent the semantic content of unstructured data can remedy this issue. This makes it significant to learn about embeddings.
The talk below will provide a high-level overview of embeddings, discuss best practices around embedding generation and usage, build two systems (semantic text search and reverse image search), and see how we can put our application into production using Milvus.
Step 5: Discover the key challenges in building LLM applications
As enterprises move beyond ChatGPT, Bard, and ‘demo applications’ of large language models, product leaders and engineers are running into challenges. The magical experience we observe on content generation and summarization tasks using ChatGPT is not replicated on custom LLM applications built on enterprise data.
Enterprise LLM applications are easy to imagine and build a demo out of, but somewhat challenging to turn into a business application. The complexity of datasets, training costs, cost of token usage, response latency, context limit, fragility of prompts, and repeatability are some of the problems faced during product development.
Delve deeper into these challenges with the below talk:
Step 6: Building Your Own ChatGPT
Learn how to build your own ChatGPT or a custom large language model using different AI platforms like Llama Index, LangChain, and more. Here are a few talks that can help you to get started:
Build Agents Simply with OpenAI and LangChain
Build Your Own ChatGPT with Redis and Langchain
Build a Custom ChatGPT with Llama Index
Step 7: Learn about Retrieval Augmented Generation (RAG)
Learn the common design patterns for LLM applications, especially the Retrieval Augmented Generation (RAG) framework; What is RAG and how it works, how to use vector databases and knowledge graphs to enhance LLM performance, and how to prioritize and implement LLM applications in your business.
The discussion below will not only inspire organizational leaders to reimagine their data strategies in the face of LLMs and generative AI but also empower technical architects and engineers with practical insights and methodologies.
Step 8: Understanding AI observability
AI observability is the ability to monitor and understand the behavior of AI systems. It is essential for responsible AI, as it helps to ensure that AI systems are safe, reliable, and aligned with human values.
The talk below will discuss the importance of AI observability for responsible AI and offer fresh insights for technical architects, engineers, and organizational leaders seeking to leverage Large Language Model applications and generative AI through AI observability.
>
Step 9: Prevent large language models hallucination
It important to evaluate user interactions to monitor prompts and responses, configure acceptable limits to indicate things like malicious prompts, toxic responses, llm hallucinations, and jailbreak attempts, and set up monitors and alerts to help prevent undesirable behaviour. Tools like WhyLabs and Hugging Face play a vital role here.
The talk below will use Hugging Face + LangKit to effectively monitor Machine Learning and LLMs like GPT from OpenAI. This session will equip you with the knowledge and skills to use LangKit with Hugging Face models.
Step 10: Learn to fine-tune LLMs
Fine-tuning GPT-3.5 Turbo allows you to customize the model to your specific use case, improving performance on specialized tasks, achieving top-tier performance, enhancing steerability, and ensuring consistent output formatting. It important to understand what fine-tuning is, why it’s important for GPT-3.5 Turbo, how to fine-tune GPT-3.5 Turbo for specific use cases, and some of the best practices for fine-tuning GPT-3.5 Turbo.
Whether you’re a data scientist, machine learning engineer, or business user, this talk below will teach you everything you need to know about fine-tuning GPT-3.5 Turbo to achieve your goals and using a fine tuned GPT3.5 Turbo model to solve a real-world problem.
Step 11: Become ChatGPT prompting expert
Learn advanced ChatGPT prompting techniques essential to upgrading your prompt engineering experience. Use ChatGPT prompts in all formats, from freeform to structured, to get the most out of large language models. Explore the latest research on prompting and discover advanced techniques like chain-of-thought, tree-of-thought, and skeleton prompts.
Explore scientific principles of research for data-driven prompt design and master prompt engineering to create effective prompts in all formats.
Step 12: Master LLMs for more
Large Language Models assist with a number of tasks like analyzing the data while creating engaging and informative data visualizations and narratives or to easily create and customize AI-powered PowerPoint presentations.
Learning About LLMs: Begin Your Journey Today
LLMs have revolutionized natural language processing, offering unprecedented capabilities in text generation, understanding, and analysis. From creative content to data analysis, LLMs are transforming various fields.
By understanding their applications, diving into fundamentals, and mastering techniques, you’re well-equipped to leverage their power. Embark on your LLM journey and unlock the transformative potential of these remarkable language models!
Start learning about LLMs and mastering the skills for tasks that can ease up your business activities.
To learn more about large language models, check out this playlist; from tutorials to crash courses, it is your one-stop learning spot for LLMs and Generative AI.