Evaluating the performance of Large Language Models (LLMs) is an important and necessary step in refining it. LLMs are used in solving many different problems ranging from text classification and information extraction.
Choosing the correct metrics to measure the performance of an LLM can greatly increase the effectiveness of the model.
In this blog, we will explore one such crucial metric – the F1 score. This blog will guide you through what the F1 score is, why it is crucial for evaluating LLMs, and how it is able to provide users with a balanced view of model performance, particularly with imbalanced datasets.

By the end, you will be able to calculate the F1 score and understand its significance, which will be demonstrated with a practical example.
Read more about LLM evaluation, its metrics, benchmarks, and leaderboards
What is F1 Score?
F1 score is a metric used to evaluate the performance of a classification model. It combines both precision and recall.
- Precision: measures the proportion of true positive predictions out of total positive predictions by the model
- Recall: measures the proportion of true positive predictions out of actual positive predictions made by the model
The F1 score combines these two metrics into a single harmonic mean:
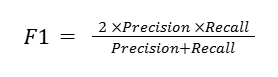
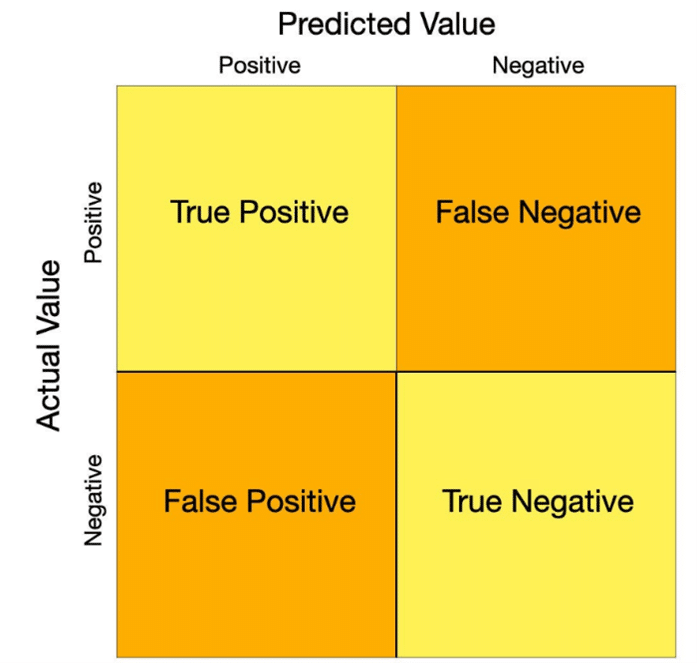
The F1 score is particularly useful for imbalanced datasets – distribution of classes is uneven. In this case a metric such as accuracy (Accuracy = Correct predictions/All predictions) can be misleading whereas the F1 score will take in to account both false positives as well as false negatives ensuring a more refined evaluation.
There are many real-world instances where a false positive or false negative can be very costly to the application of the model. For example:
- In spam detection, a false positive (marking a real email as spam) can lead to losing important emails.
- In medical diagnosis, a false negative (failing to detect a disease) could have severe consequences.
Here’s a list of key LLM evaluation metrics you must know about
Why Are F1 Scores Important in LLMs?
The evaluation of NLP tasks requires a metric that is able to effectively encapsulate the subtlety in its performance. The F1 score does a great job in these tasks.
- Text Classification: evaluate the performance of an LLM in categorizing texts into distinct categories – for example, sentiment analysis or spam detection.
- Information Extraction: evaluate the performance of an LLM in accurately identifying entities or key phrases – for example, personally identifiable information (PII) detection.
The trade-off between precision and recall is addressed by the F1 score and due to the nature of the complexity of an LLM, it is pertinent to ensure the model’s performance is evaluated across all metrics.
In fields like healthcare, finances, and legal settings, ensuring high precision is very useful but considering the false positives and negatives (recall) are essential as making small mistakes could be very costly.
Explore a list of key LLM benchmarks for evaluation
Real-World Example: Spam Detection
Let’s examine how the F1 score can help in the evaluation of an LLM- based spam detection system. Spam detection is a critical classification task where both false positives and false negatives could be causes for high alert.
- False Positives: Legitimate emails mistakenly marked as spam can cause missed communication.
- False Negatives: Spam emails that bypass the filters may expose users to phishing attacks.
Initial Model
Consider a synthetic dataset with a clear imbalance in classes: most emails are real with reduced spam (which is a likely scenario in the real world).
Result – Accuracy: 0.80
Despite having a high accuracy, it is not safe to assume that we have created an ideal model. Because we could have just easily created a model that predicts all emails as real and in certain scenarios, would be highly accurate.
Result
Precision: 1.00
Recall: 0.50
F1 Score: 0.67
To confirm our suspicion, we can go ahead and calculate the precision, recall, and F1 scores. We notice that there is a disparity between our precision and recall scores.
- High Precision, Low Recall: Minimizes false positives but misses in filtering spam emails
- Low Precision, High Recall: Correctly filters most spam, but also marks real emails as spam

In the real-world application of a spam detection system, an LLM needs to be very diligent with marking the false positives and false negatives. That is why the F1 score is more representative of how well the model is working, whereas the accuracy score wouldn’t capture that insightful nuance.
A balanced assessment of both precision and recall is certainly necessary as the false positives and negatives carry a huge risk to a spam detector’s classification task. Upon noting these remarks, we can fine-tune our LLM to better optimize precision and recall – using the F1 score for evaluation.
Improved Model
Result – Improved Accuracy: 0.80
Result
Improved Precision: 0.75
Improved Recall: 0.75
Improved F1 Score: 0.75
As you can see from the above, after simulating fine-tuning of our model to address the low F1 score, we get similar accuracy, but a higher F1 score. Here’s why, despite the lower precision score, this is still a more refined and reliable LLM.
- A recall score of 0.5 in the previous iteration of the model would suggest that many actual spam emails would go unmarked, a vital classification task of our spam detector
- F1 score improves balancing false positives and false negatives. Yes, this is a very repeated rhetoric, but it is essential to understand its importance in the evaluation, both for our specific example and many other classification tasks
- False Positives: Sure, a few legitimate emails will be marked as spam, but the trade-off is accepted considering the vast improvement in the coverage of detecting spam emails
- False Negatives: A classification task needs to be reliable, and this is achieved by the reduction in missed spam emails. Reliability shows the robustness of an LLM as it demonstrates the ability for the model to address false negatives, rather than simplifying the model on account of the bias (imbalance) in the data.
Navigate through the top 5 LLM leaderboards and their impact
In the real world, a spam detector that prioritizes high precision would be inadequate in protecting users from actual spam. In another example, if we had created a model with high recall and lower precision, important emails would never reach the user.
That is why it is fundamental to properly understand the F1 score and its ability to balance both the precision and recall, which was something that the accuracy score did not reflect.

When building or evaluating your next LLM, remember that accuracy is only part of the picture. The F1 score offers a more complete and insightful metric, particularly for critical and imbalanced tasks like spam detection.
Ready to dive deeper into LLM evaluation metrics? Explore our LLM bootcamp and master the art of creating reliable Gen AI models!