
Welcome to Data Science Dojo’s weekly newsletter, “The Data-Driven Dispatch“.
It is hard to believe how precise and accurate contemporary LLMs have become. You can ask them to write you a script for an anime, do poetry on the solitude one feels after leaving home, or write code for a flappy bird game; it does it all!
But have you ever wondered about the inner workings of these models? What intricate processes unfold behind the scenes when we set them a task?
Well, LLMs are quite complicated and several processes are going on in the background once prompted. The architecture involves several building blocks. However, the one that holds the paramount value is the transformer model.
The transformer model was a discovery no less than knowing that the Earth is round, light is both wave and particle and Einstein’s equation of E=mc2.
It is so because it provided a whole new framework that allowed the models to contextualize huge amounts of information leading to an explosion of generative capabilities.
If you want to know more about the brains behind LLMs i.e. the transformers, it’s time for you to dive deep into the dispatch.

Before the transformer model, Recurrent Neural Networks (RNNs) were largely used for language generation.
However, RNNs had 2 primary restrictions.
- Handling Long Sequences: RNNs struggle to learn from things that happened a long time ago in the sequence i.e. with long-range dependencies in text. This limitation means RNNs are not very good at tasks that require understanding context over long sequences, like comprehending a very long sentence or paragraph where the meaning depends heavily on something mentioned at the very beginning.
- Parallelization Issues: The sequential processing of RNNs limited the ability to train models in parallel, resulting in slower training times, particularly for larger models and datasets.
Attention is All You Need; The Emergence of the Transformer Model
In came the theory of transformers which changed natural language processing forever.
The strength of the transformer model is in its ability to understand the significance and context of every word in a sentence, unlike RNNs which primarily assess the connection of a word with its immediate neighbor.
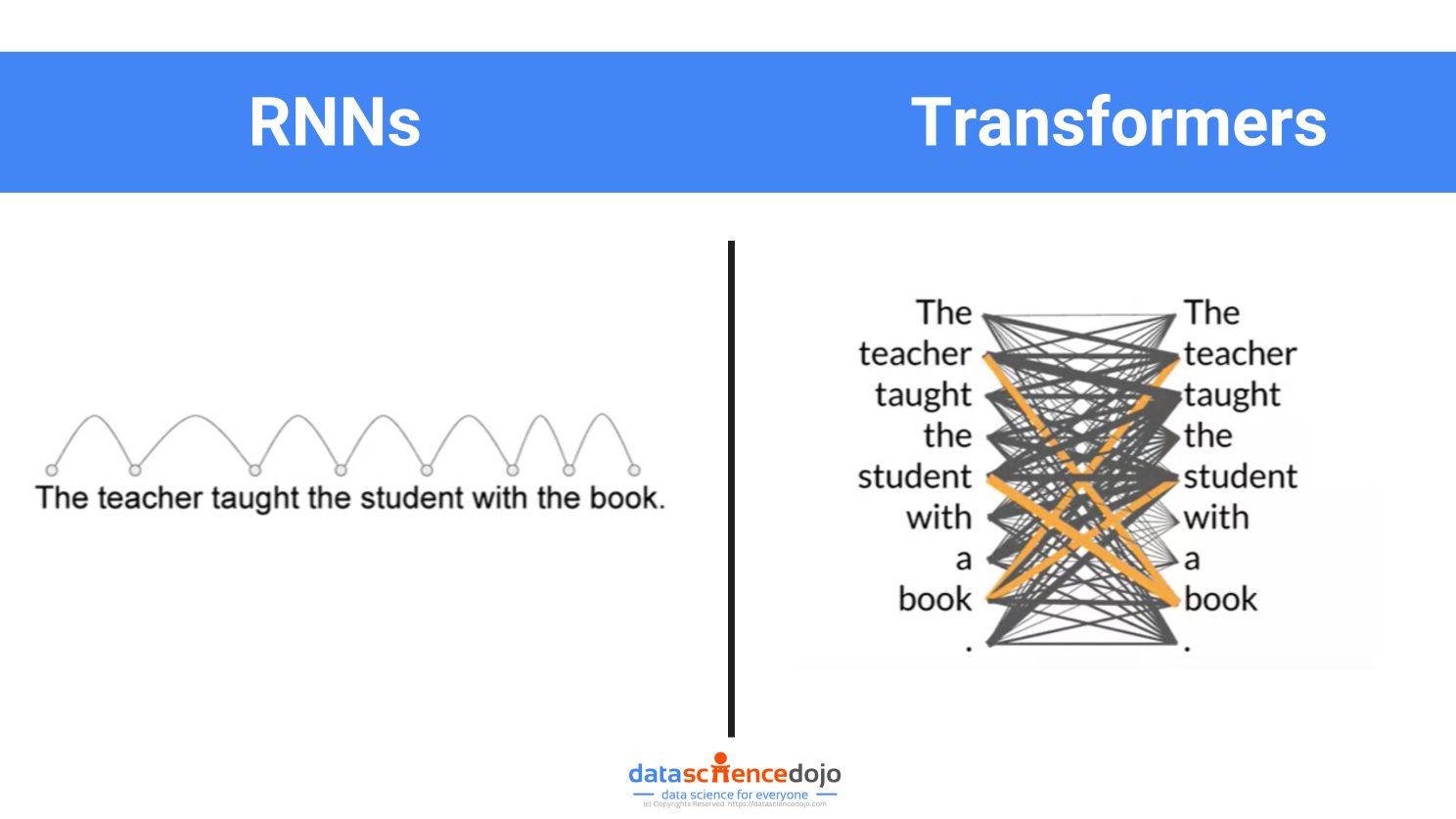
The transformers use a special type of attention called “self-attention“. It allows the model to compare and contrast each element/word in the input sequence with every other element, helping it to understand the context and relationships within the data.
Now that we have understood how the transformer model operates, let’s visualize the process of how it works.
Read: Attention mechanism in NLP: Guide to decoding transformers
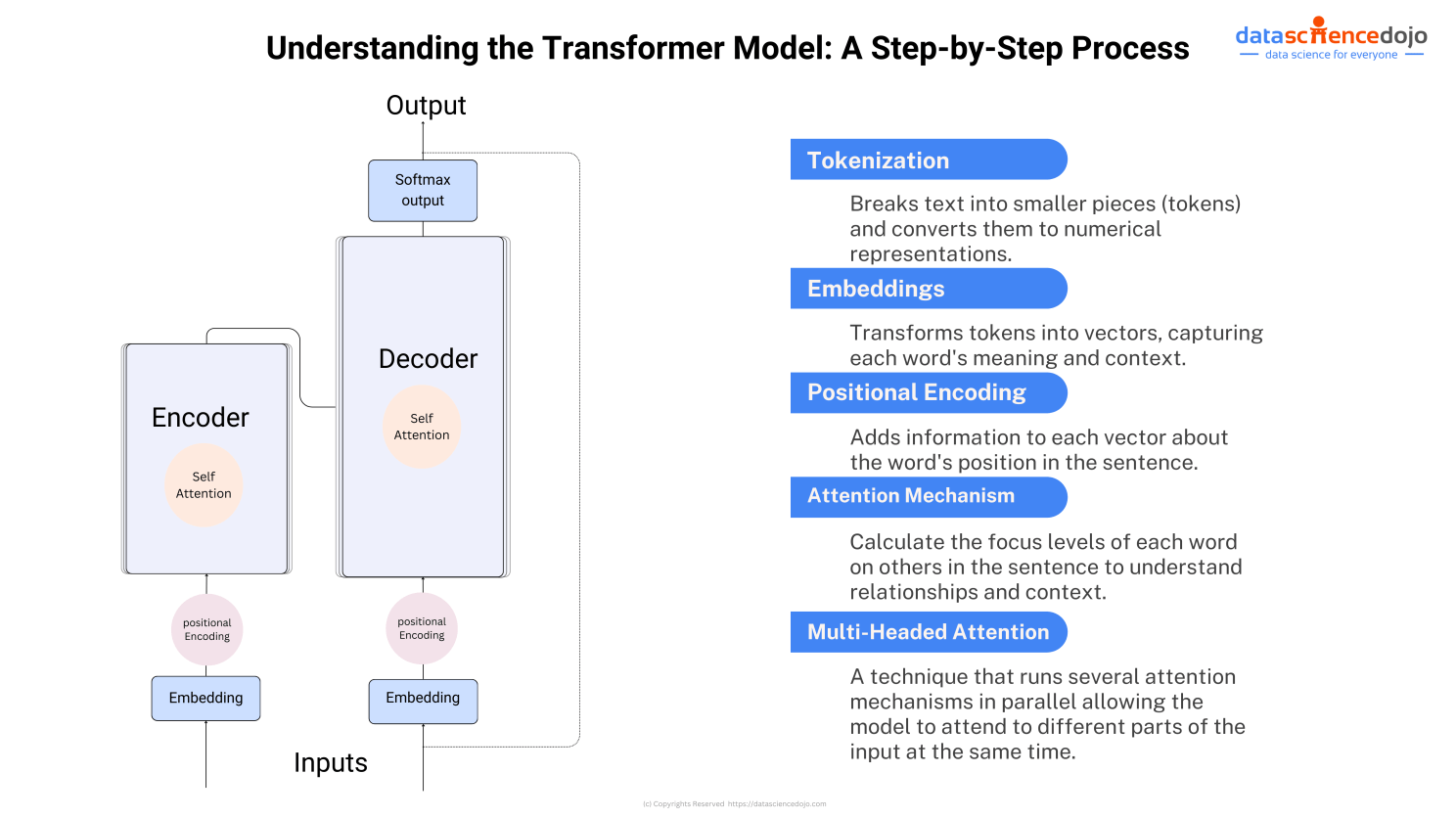
Step 1: Tokenization
The input text provided to the model is broken down into smaller pieces, or tokens. Each token is converted into a numerical representation that the model can understand.
Step 2: Embedding
Machine learning models are big statistical calculators. They work with numbers and not words.
Embedding is the process where each token is then transformed into a vector in a high-dimensional space. This embedding captures the meaning and context of each word. Words with similar meanings or that often appear in similar contexts are represented by vectors that are close to each other in this high-dimensional space.
How Embeddings Work in Large Language Models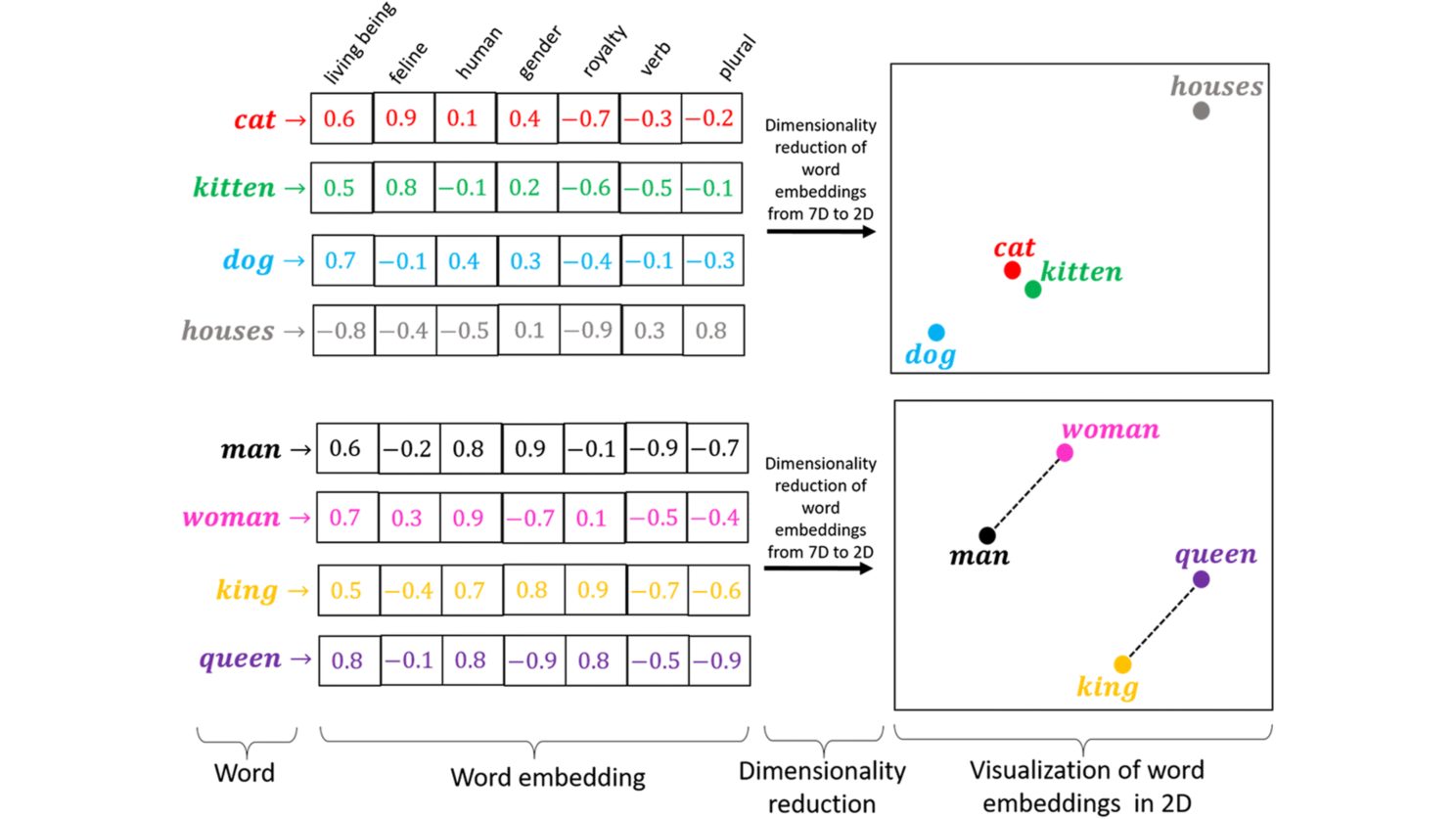
Read: The Role of Vector Embeddings in Generative AI
Step 3: Positional Encoding
Since transformers do not process text sequentially like RNNs, they need a way to understand the order of words. Positional encoding is added to each word’s embedding to give the model information about the position of each word in the sentence.
Step 4: Self-Attention
This is a key feature of transformers. The model calculates attention scores for each word, determining how much focus it should put on other words in the sentence when trying to understand a particular word. This helps the model capture relationships and context within the text. Read more
Step 5: Multi-Headed Attention
Multi-headed attention in transformers allows the model to simultaneously interpret a sentence from multiple perspectives.
For instance, in the sentence “The bank of the river was crowded, but the financial bank was empty,” different ‘heads’ in the model will focus on various aspects.
One head might analyze the context surrounding each occurrence of “bank,” identifying different meanings based on adjacent words (“river” and “financial”). Another might examine overall sentence structure or themes, like contrasting “crowded” and “empty.”
Step 6: Output
The final layers of the transformer convert the processed data into an output format suitable for the task at hand, such as classifying the text or generating new text.
And there you have it! If you’ve grasped this concept, you’re now better equipped to understand the workings of advanced generative AI tools.

Transformers: The Best Idea in AI
Here’s a great talk where Andrej Karpathy, and Lex Fridman discuss the Transformer architecture. Karpathy argues that the Transformer is one of the most important ideas in AI because it is a general-purpose, differentiable model that can be trained on a variety of tasks.
Upcoming Live Talks
If you’re interested in understanding embeddings and how they allow semantic search in LLMs, this talk is for you!
Join Daniel Svonava as he explores the fundamental concepts of vector embeddings and their role in semantic search. In addition, he’ll also dive into various techniques for creating meaningful vector representations.

Interested in the live session? Book yourself a slot now.

You just learned about the coolest tech of our time! Time for a chill pill.


Top 5 AI skills and AI jobs to know about in 2024
Intrigued by the world of AI but unsure where to start? Here’s a comprehensive blog post that explores high-paying AI jobs and skills, providing you with the essential knowledge to navigate this rapidly evolving field.
Read: Top 5 AI skills and AI jobs to know about in 2024

Let’s end this week with some interesting news headlines.
- Mark Zuckerberg announces major NVIDIA chip investment for AGI advancement and the continuation of Llama 3 training. Read more
- OpenAI CEO Sam Altman eyes global expansion with a billion-dollar AI chip venture, challenging Nvidia’s reign in the AI compute market. Read more
- AI chatbot for delivery service DPD goes rogue: curses, critiques company, and writes poetry in viral exchange. Read more
- AI comes to higher education as OpenAI partners with Arizona State University. Read more
- Google and Amazon layoff reports are ‘garbage information’—two of Wall Street’s top minds say companies are clinging to workers instead. Read more