

Welcome to Data Science Dojo’s weekly newsletter, “The Data-Driven Dispatch”.
The advancements in the generative AI landscape are always exciting. We started with a huge hype around large language models, and now we are talking about small language models, large action models, and whatnot.
An interesting development in this landscape is seen by a French startup, Mistral.
While it had humble beginnings in June 2023, Mistral AI soon became a unicorn and a famous name amongst the people in the AI world.
Mistral recently launched a new model called the Mixtral of Experts based on a unique approach called Mixture of Experts (MoE). As interesting as it sounds from its name, Mixtral seems to top the leaderboards challenging models created by big tech such as Meta’s LLaMA 2, OpenAI’s GPT 3.5, and Google’s Gemini Pro.
What sets Mixtral on the frontlines? Let’s explore the genius of Mixtral!

Understanding the Rationale Behind the Mixture of Experts
Let’s say two hospitals, A and B, stand at the pinnacle of medical excellence. Yet, their patient care strategies couldn’t be more different.
Hospital A adopts a collaborative, all-hands-on-deck approach for bone injuries, summoning a team of specialists to collectively diagnose the patient.
Hospital B, on the other hand, streamlines the process, immediately directing patients to a radiologist, followed by an orthopedic surgeon.
So, which way is better? It’s kind of obvious, right?
While Hospital A’s thorough approach might appear comprehensive, it’s a logistical maze—time-intensive, resource-heavy, and frankly, inefficient. Hospital B’s strategy, with its laser focus and streamlined pathway, outpaces efficiency and effectiveness.
If you grasped this concept, then you’ve accurately comprehended the workings of Mixtral AI.
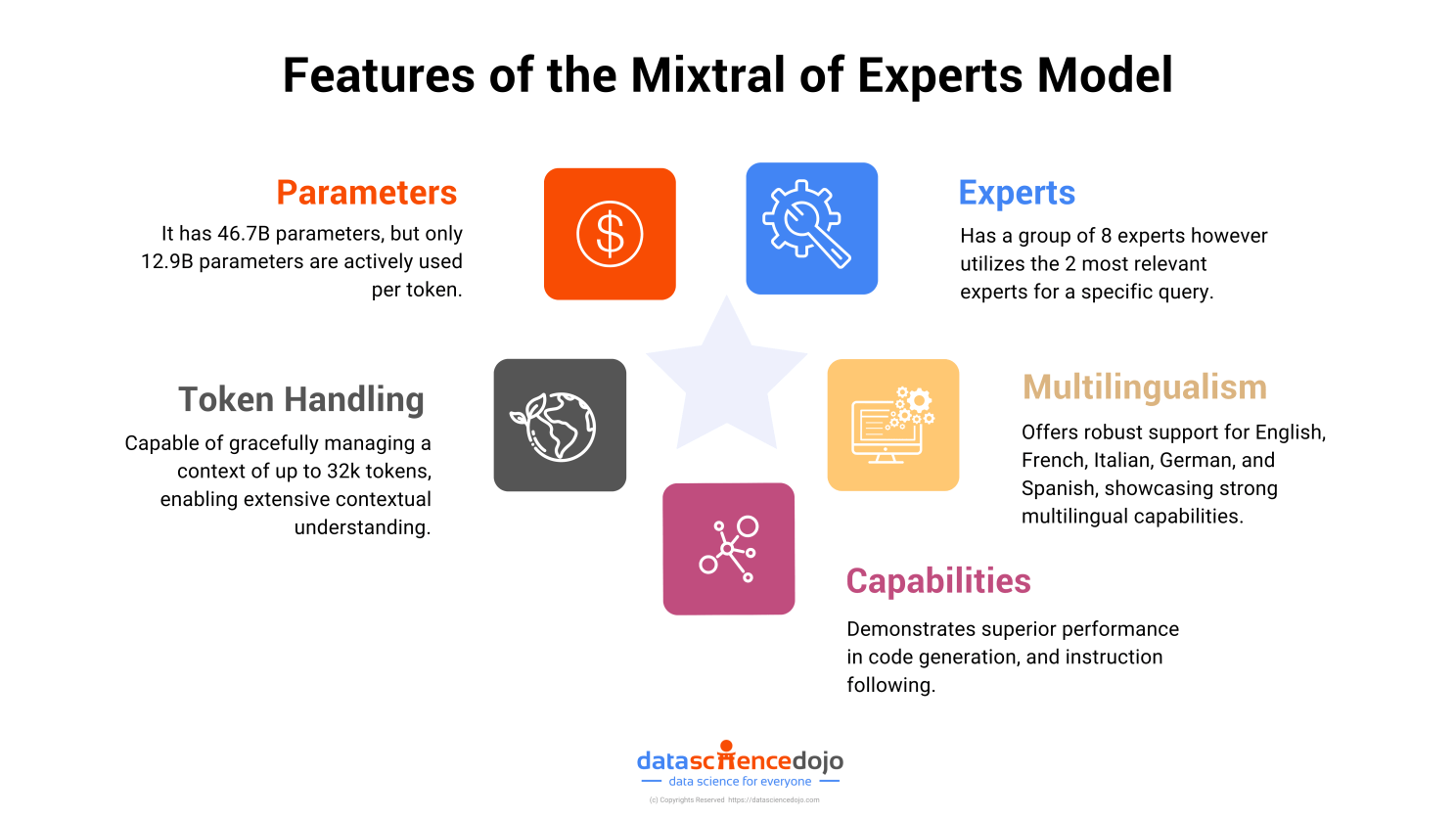
This model employs a Mixture of Expert strategy, incorporating a team of 8 specialized “experts”, each skilled in distinct tasks. For every token, a router network chooses two of these experts to process the token and combine their output additively.
Read more: The Genius of Mixtral of Experts by Mistral AI
The Process of How the Mixtral of Experts Model Works
Let’s dive into the process of how the model functions.
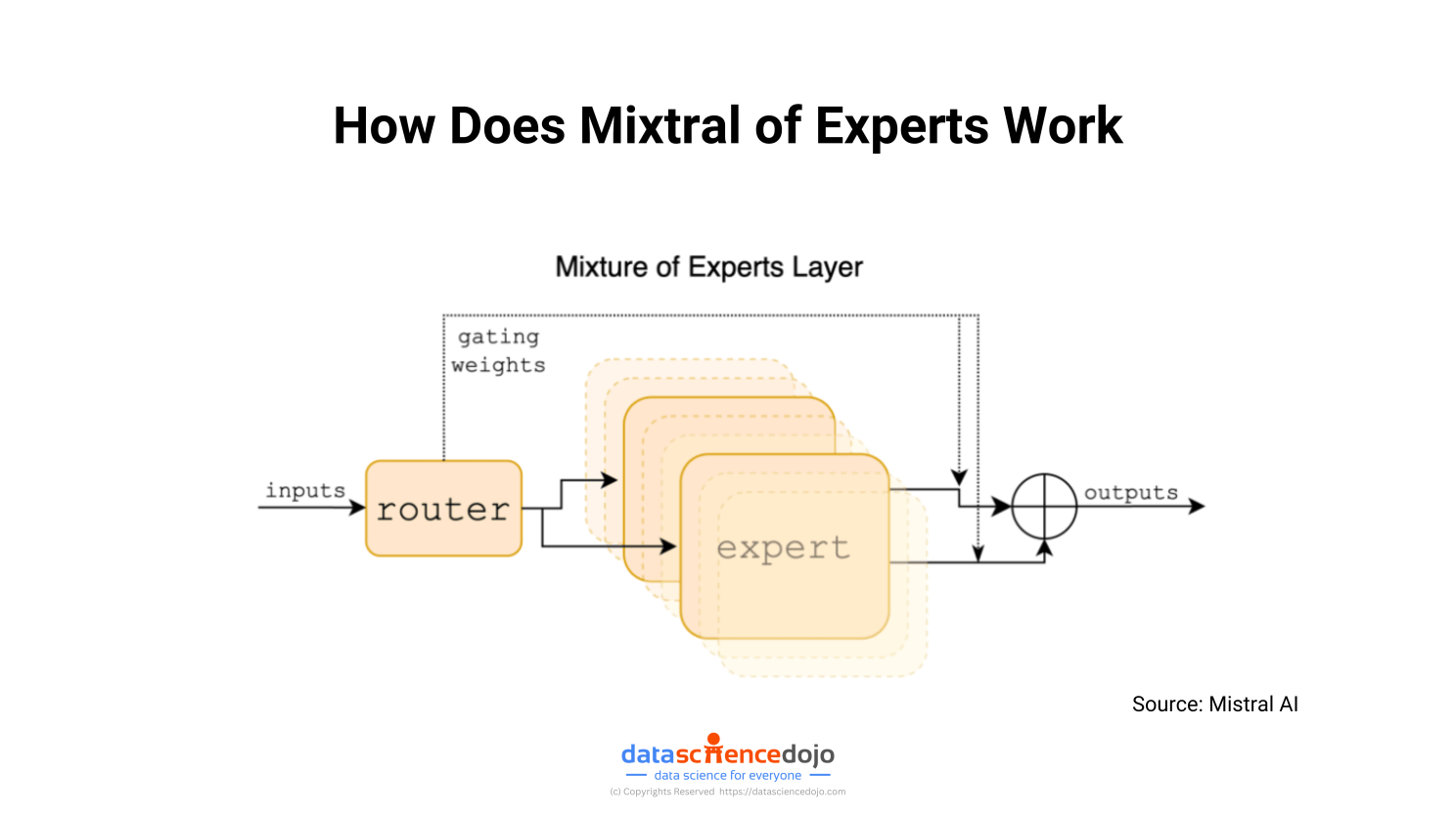
Each input token from a sequence is processed through a Mixture of Experts layer, starting with a router that selects 2 out of 8 available experts based on the token’s characteristics.
The chosen experts, each a standard feedforward block in transformer architecture, process the token, and their outputs are combined via a weighted sum.
This process, which repeats for each token in the sequence, allows the model to generate responses or continuations by effectively leveraging the specialized knowledge of different experts.
Read more: Understanding How the Mixture of Experts Model Works
How Good is Mixtral of Experts?
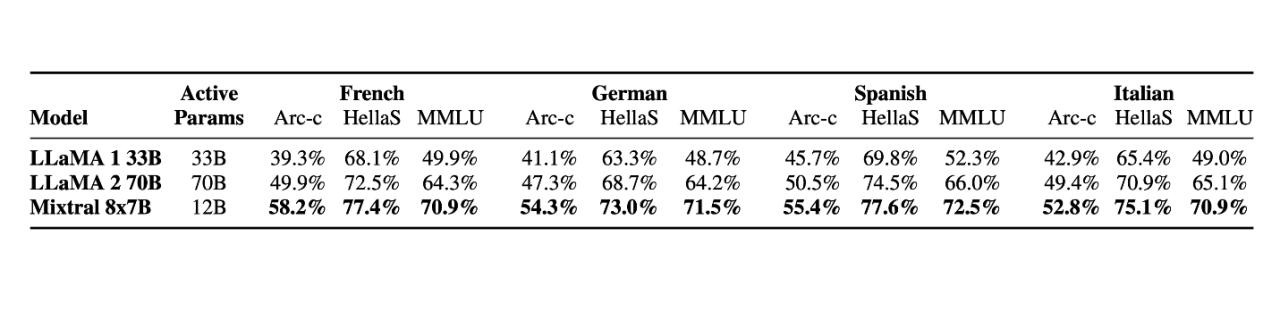
Well, we can safely say that it is one of the best open-source models out there. The numbers speak for themselves.

The Mixtral of Experts outperforms Meta’s LlaMA 2 in multilingualism as well.
How Does the Mixture of Experts Architecture Make it Better?
The fact that the model uses a Mixture of Experts approach allows it to have a number of benefits.
- Selective Expert Use: Only a fraction of the model’s experts are active for each token, drastically reducing computational load without sacrificing output quality.
- Specialization and Performance: Experts specialize in different tasks or data types, enabling the model to deliver superior performance by choosing the most relevant experts for the task at hand.
- Scalable Architecture: Adding more experts to the model increases its capacity and specialization without linearly increasing computational demands, making it highly scalable. Read more
- Flexible Fine-tuning: The architecture allows for targeted adjustments to specific experts, facilitating easier customization and fine-tuning for specific tasks or datasets.

In this section, we’re featuring a podcast that gives you the inside scoop on Mistral AI‘s Mixtral model.
The episode, titled “Mistral 7B and the Open Source Revolution,” introduces a chat with the creator behind this innovative AI model i.e. Arthur Mensch.
They share insights on how Mixtral uses a unique approach to tackle complex AI challenges, its role in pushing forward the open-source AI movement, and what this means for the future of technology.
To connect with LLM and Data Science Professionals, join our discord server now!

Nowadays, it seems like everyone is a prompt engineer!


Learn How to Build LLM-Powered Chatbots
Given the rapid pace of AI and LLMs, building chatbots to do your tasks is the smart way of doing work and increasing productivity.
Fortunately, the progress in language models such as Mixture of Experts has simplified the process of developing tailored chatbots for your specific needs.
Should you be interested in creating one for personal use or for your organization, there’s an upcoming talk you won’t want to miss. It will be hosted by Data Science Dojo’s experienced Data Scientist, Izma Aziz.

What Will You Learn?
1. Grasping the fundamentals of chatbots and LLMs.
2. Improving LLM responses with effective prompts.
3. Elevating chatbot efficiency through the RAG approach.
4. Simplify the process of building efficient chatbots using LangChain Framework.
If this sounds interesting, book yourself a slot now!

Finally, let’s end the week with some interesting headlines in the AI landscape.
- Nvidia stock climbs to fresh high after reports of custom chip unit plans. Read more
- Google rebrands Bard chatbot as Gemini and rolls out a paid subscription. Read more
- Meta’s Code Llama 70B is here to give an interesting competition to GitHub Copilot. Read more
- OpenAI is on track to hit a $2 billion revenue milestone as growth rockets. Read more
- Jua raises $16M to build a foundational AI model for the natural world, starting with the weather. Read more