
Refrag is the latest innovation from Meta Superintelligence Labs, designed to supercharge retrieval-augmented generation (RAG) systems. As large language models (LLMs) become central to enterprise AI, the challenge of efficiently processing long-context inputs—especially those packed with retrieved knowledge has grown significantly.
Refrag tackles this problem head-on. It introduces a new way to represent, compress, and retrieve information, offering up to 30× acceleration in time-to-first-token (TTFT) and 16× context window expansion, all without compromising accuracy or reliability.
What is Retrieval-Augmented Generation (RAG)?
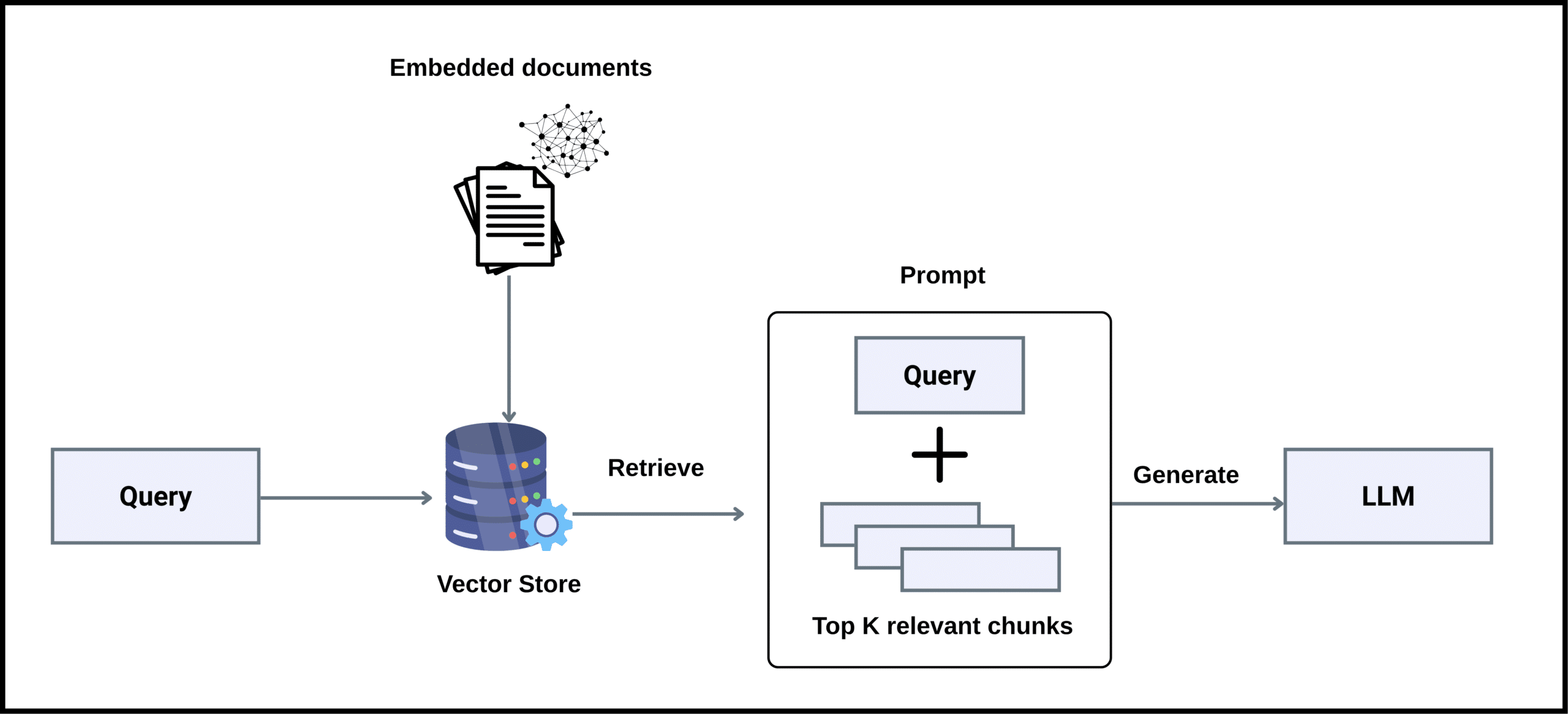
Retrieval-Augmented Generation (RAG) is a technique that enhances large language models by connecting them to external knowledge sources. Instead of relying solely on their internal parameters, RAG models retrieve relevant documents, passages, or data snippets from external corpora to ground their responses in factual, up-to-date information.
In a typical RAG pipeline:
-
The user submits a query.
-
A retriever searches an external database for top-k relevant documents.
-
The retrieved text is concatenated with the original query and sent to the LLM for generation.
This approach reduces hallucinations, improves factual grounding, and enables models to adapt quickly to new or domain-specific information—without expensive retraining.
However, the process comes at a cost. RAG systems often feed very long contexts into the model, and as these contexts grow, computational complexity explodes.
The Bottleneck: Long Contexts in LLMs
Modern transformers process input sequences using an attention mechanism, where every token attends to every other token in the sequence. This operation scales quadratically with sequence length. In practice, doubling the input length can quadruple compute and memory requirements.
For RAG applications, this creates several bottlenecks:
- Increased latency: The model takes longer to generate the first token (TTFT).
- High memory usage: Large key-value (KV) caches are needed to store token representations.
- Reduced throughput: Fewer parallel requests can be processed at once.
- Scalability limits: Context length constraints prevent using extensive retrieved data.
Worse, not all retrieved passages are useful. Many are marginally relevant, yet the model still expends full computational effort to process them. This inefficiency creates a trade-off between knowledge richness and system performance, a trade-off Refrag is designed to eliminate.
Why Refrag Matters for the Future of RAG
Traditional RAG pipelines prioritize retrieval precision but neglect representation efficiency. Meta recognized that while retrieval quality had improved, context handling had stagnated. Large contexts were becoming the single biggest latency bottleneck in real-world AI systems—especially for enterprises deploying production-scale assistants, search engines, and document analyzers.
Refrag redefines how retrieved knowledge is represented and processed. By encoding retrieved text into dense chunk embeddings and selectively deciding what information deserves full attention, it optimizes both speed and accuracy bridging the gap between compactness and completeness.
Discover how RAG compares with fine-tuning in real-world LLMs.
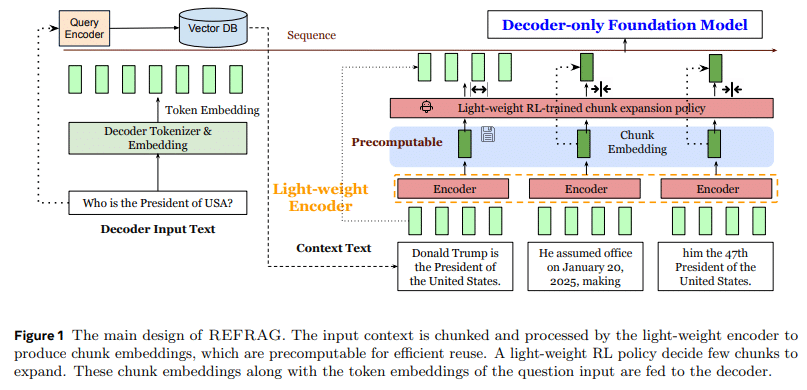
How REFRAG Works: Technical Deep Dive
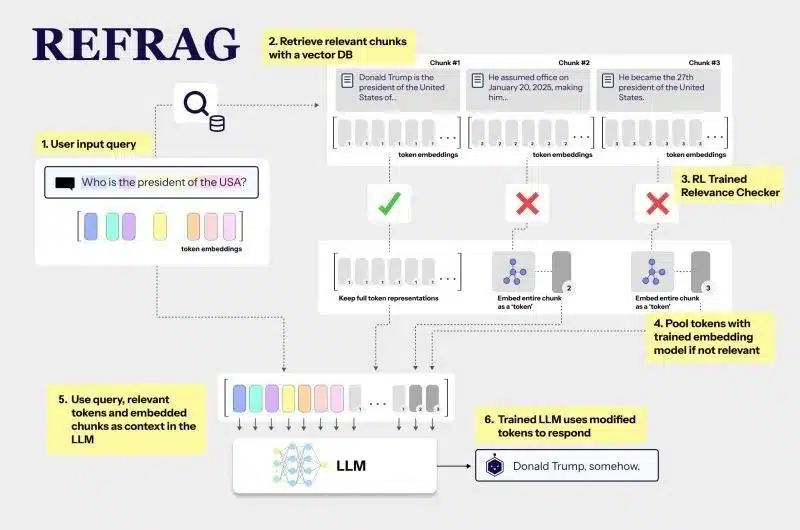
Refrag introduces a modular, plug-and-play framework built on four key pillars: context compression, selective expansion, efficient decoding, and architectural compatibility.
1. Context Compression via Chunk Embeddings
Refrag employs a lightweight encoder that divides retrieved passages into fixed-size chunks—typically 16 tokens each. Every chunk is then compressed into a dense vector representation, also known as a chunk embedding.
Instead of feeding thousands of raw tokens to the decoder, the model processes a much shorter sequence of embeddings. This reduces the effective input length by up to 16×, leading to massive savings in computation and memory.
This step alone dramatically improves efficiency, but it introduces the risk of information loss. That’s where it’s reinforcement learning (RL) policy comes in.
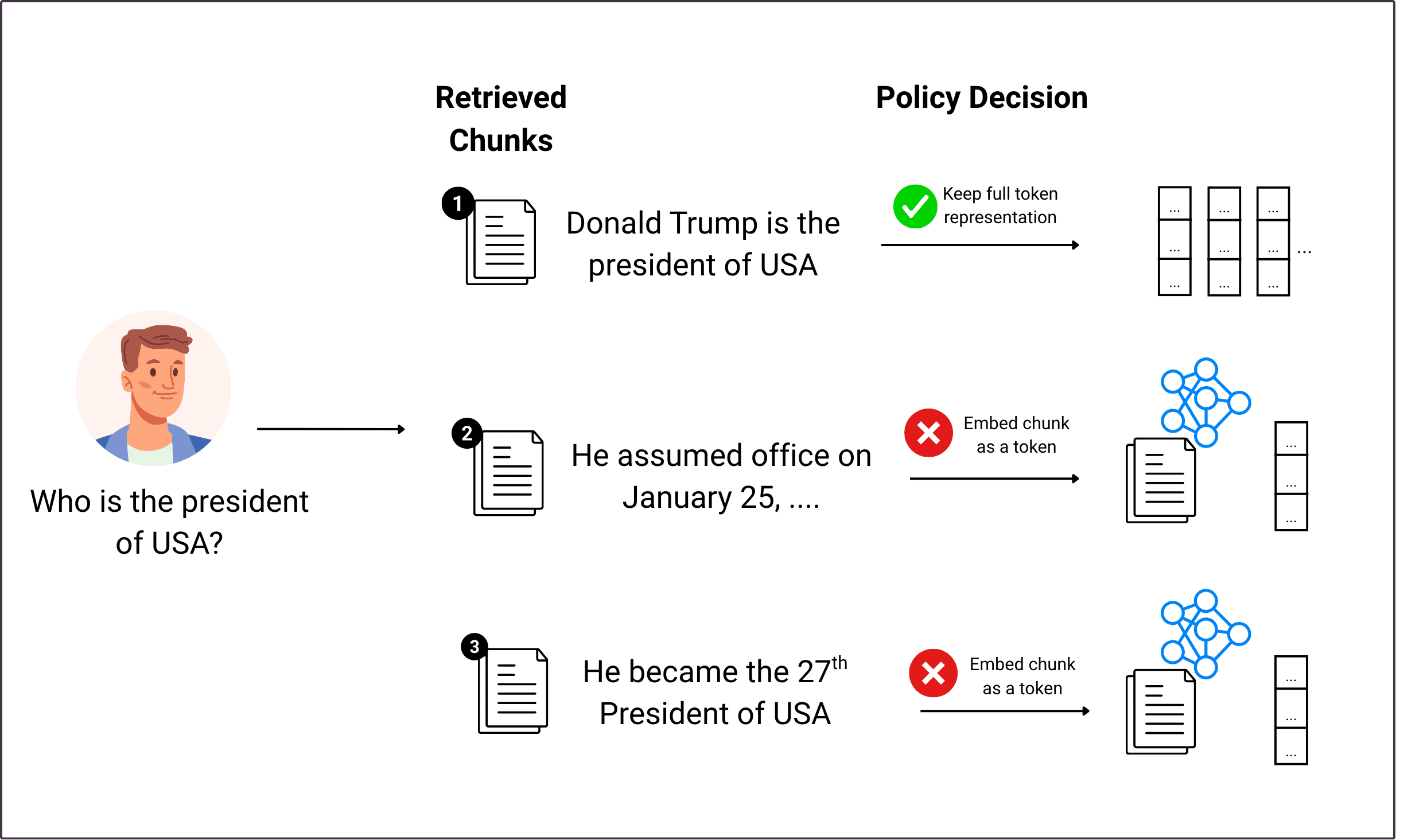
2. Selective Expansion with Reinforcement Learning
Not all tokens can be compressed safely. Some contain critical details—numbers, named entities, or unique terms that drive the model’s reasoning.
Refrag trains a reinforcement learning policy that identifies these high-information chunks and allows them to bypass compression. The result is a hybrid input sequence:
-
Dense chunk embeddings for general context.
-
Raw tokens for critical information.
This selective expansion preserves essential semantics while still achieving large-scale compression. The RL policy is guided by reward signals based on model perplexity and downstream task accuracy.
3. Efficient Decoding and Memory Utilization
By shortening the decoder’s input sequence, it minimizes quadratic attention costs. The decoder no longer needs to attend to thousands of raw tokens; instead, it focuses on a smaller set of compressed representations.
This architectural shift leads to:
-
30.85× faster TTFT (time-to-first-token)
-
6.78× improvement in throughput compared to LLaMA baselines
-
16× context window expansion, enabling models to reason across entire books or multi-document corpora
In practical terms, this means that enterprise-grade RAG systems can operate with lower GPU memory, reduced latency, and greater scalability—all while maintaining accuracy.
4. Plug-and-Play Architecture
A standout advantage of Refrag is its compatibility. It doesn’t require modifying the underlying LLM. The encoder operates independently, producing pre-computed embeddings that can be cached and reused.
This plug-and-play design allows seamless integration with popular architectures like LLaMA, RoBERTa, and OPT—enabling organizations to upgrade their RAG pipelines without re-engineering their models.
Key Innovations: Compression, Chunk Embeddings, RL Selection
| Component | Description | Impact |
|---|---|---|
| Chunk Embeddings | Compresses 16 tokens into a single dense vector | 16× reduction in input length |
| RL Selection Policy | Identifies and preserves critical chunks for decoding | Maintains accuracy, prevents info loss |
| Pre-computation | Embeddings can be cached and reused | Further latency reduction |
| Curriculum Learning | Gradually increases compression difficulty during training | Robust encoder-decoder alignment |
Benchmark Results: Speed, Accuracy, and Context Expansion
REFRAG was pretrained on 20B tokens (SlimPajama corpus) and tested on long-context datasets (Books, Arxiv, PG19, ProofPile). Key results:
- Speed: Up to 30.85× TTFT acceleration at k=32 compression
- Context: 16× context extension beyond standard LLaMA-2 (4k tokens)
- Accuracy: Maintained or improved perplexity compared to CEPE and LLaMA baselines
- Robustness: Outperformed in weak retriever settings, where irrelevant passages dominate
| Model | TTFT Acceleration | Context Expansion | Perplexity Improvement |
|---|---|---|---|
| REFRAG | 30.85× | 16× | +9.3% over CEPE |
| CEPE | 2–8× | 8× | Baseline |
| LLaMA-32K | 1× | 8× | Baseline |
Uncover the next evolution beyond classic RAG — a perfect companion to Refrag.
Real-World Applications
Refrag’s combination of compression, retrieval intelligence, and scalability opens new frontiers for enterprise AI and large-scale applications:
- Web-Scale Search Engines: Process millions of retrieved documents for real-time question answering.
- Multi-Turn Conversational Agents: Retain entire dialogue histories without truncation, enabling richer multi-agent interactions.
- Document Summarization: Summarize long research papers, financial reports, or legal documents with full context awareness.
- Enterprise RAG Pipelines: Scale to thousands of retrieved passages while maintaining low latency and cost efficiency.
- Knowledge Management Systems: Dynamically retrieve and compress knowledge bases for organization-wide AI assistants.
Benefits for Production-Scale LLM Applications
- Cost Efficiency: Reduces hardware requirements for long-context LLMs
- Scalability: Enables larger context windows for richer, more informed outputs
- Accuracy: Maintains or improves response quality, even with aggressive compression
- Plug-and-Play: Integrates with existing LLM architectures and retrieval pipelines
For hands-on RAG implementation, see Building LLM applications with RAG.
Challenges and Future Directions
Although Refrag demonstrates remarkable gains, several open challenges remain:
-
Generalization across data domains: How well does the RL chunk selector perform on heterogeneous corpora such as code, legal, and multimodal data?
-
Limits of compression: What is the theoretical compression ceiling before semantic drift or factual loss becomes unacceptable?
-
Hybrid architectures: Can it be combined with prompt compression, streaming attention, or token pruning to further enhance efficiency?
-
End-to-end optimization: How can retrievers and Refrag encoders be co-trained for domain-specific tasks?
Meta has announced plans to release the source code on GitHub under the repository facebookresearch/refrag, inviting the global AI community to explore, benchmark, and extend its capabilities.
FAQs
Q1. What is REFRAG?
It’s Meta’s decoding framework for RAG systems, compressing retrieved passages into embeddings for faster, longer-context LLM inference.
Q2. How much faster is REFRAG?
Up to 30.85× faster TTFT and 6.78× throughput improvement compared to LLaMA baselines.
Q3. Does compression reduce accuracy?
No. RL-based selection ensures critical chunks remain uncompressed, preserving key details.
Q4. Where can I find the code?
Meta will release REFRAG at facebookresearch/refrag.
Conclusion & Call to Action
Meta’s Refrag marks a transformative leap in the evolution of retrieval-augmented generation. By combining compression intelligence, reinforcement learning, and context expansion, it finally makes large-context LLMs practical for real-world, latency-sensitive applications.
For enterprises building retrieval-heavy systems—from customer support to scientific research assistants, it offers a path toward faster, cheaper, and smarter AI.
Ready to implement RAG and Refrag in your enterprise?
Explore Data Science Dojo’s LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI systems.