
Graph rag is rapidly emerging as the gold standard for context-aware AI, transforming how large language models (LLMs) interact with knowledge. In this comprehensive guide, we’ll explore the technical foundations, architectures, use cases, and best practices of graph rag versus traditional RAG, helping you understand which approach is best for your enterprise AI, research, or product development needs.
Why Graph RAG Matters
Graph rag sits at the intersection of retrieval-augmented generation, knowledge graph engineering, and advanced context engineering. As organizations demand more accurate, explainable, and context-rich AI, graph rag is becoming essential for powering next-generation enterprise AI, agentic AI, and multi-hop reasoning systems.
Traditional RAG systems have revolutionized how LLMs access external knowledge, but they often fall short when queries require understanding relationships, context, or reasoning across multiple data points. Graph rag addresses these limitations by leveraging knowledge graphs—structured networks of entities and relationships—enabling LLMs to reason, traverse, and synthesize information in ways that mimic human cognition.
For organizations and professionals seeking to build robust, production-grade AI, understanding the nuances of graph rag is crucial. Data Science Dojo’s LLM Bootcamp and Agentic AI resources are excellent starting points for mastering these concepts.
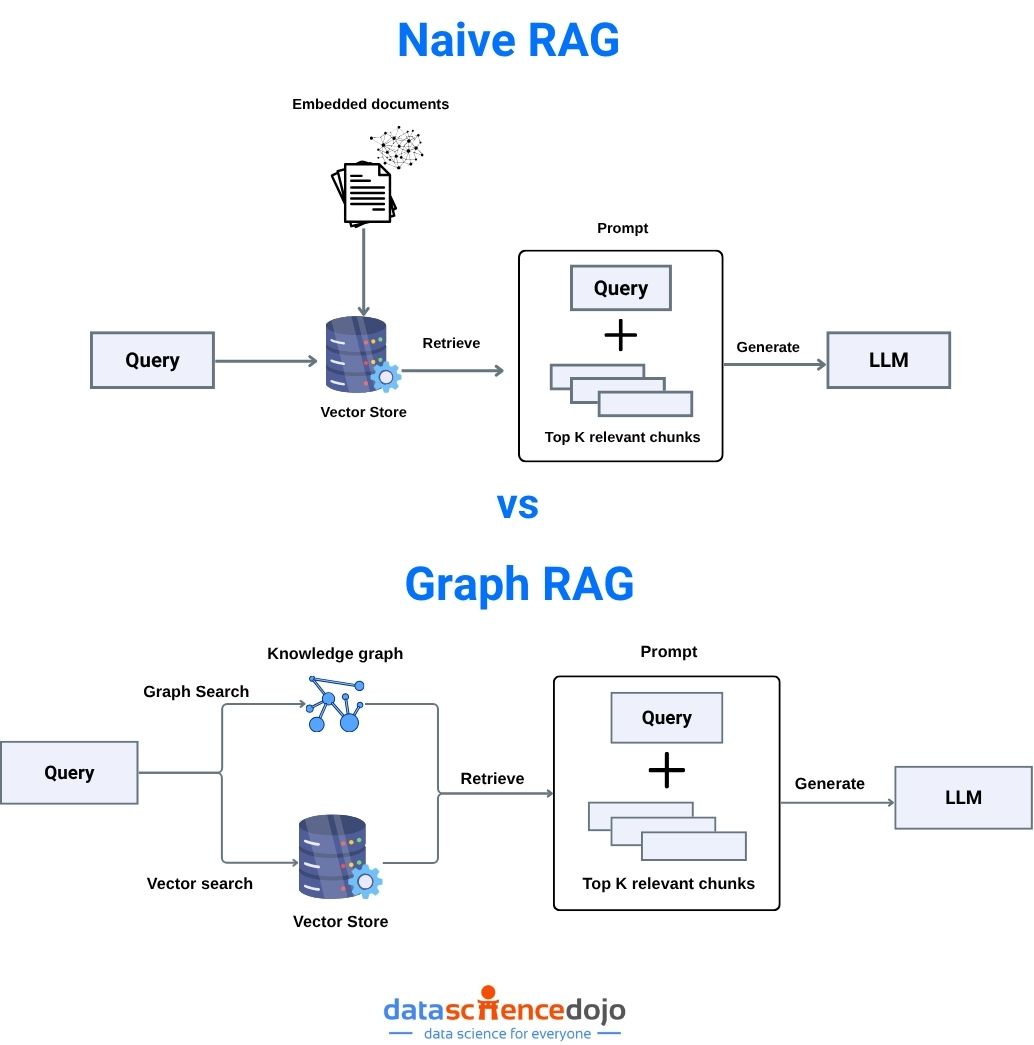
What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a foundational technique in modern AI, especially for LLMs. It bridges the gap between static model knowledge and dynamic, up-to-date information by retrieving relevant data from external sources at inference time.
How RAG Works
- Indexing: Documents are chunked and embedded into a vector database.
- Retrieval: At query time, the system finds the most semantically relevant chunks using vector similarity search.
- Augmentation: Retrieved context is concatenated with the user’s prompt and fed to the LLM.
- Generation: The LLM produces a grounded, context-aware response.
Benefits of RAG:
- Reduces hallucinations
- Enables up-to-date, domain-specific answers
- Provides source attribution
- Scales to enterprise knowledge needs
For a hands-on walkthrough, see RAG in LLM – Elevate Your Large Language Models Experience and What is Context Engineering?.
What is Graph RAG?
Graph rag is an advanced evolution of RAG that leverages knowledge graphs—structured representations of entities (nodes) and their relationships (edges). Instead of retrieving isolated text chunks, graph rag retrieves interconnected entities and their relationships, enabling multi-hop reasoning and deeper contextual understanding.
Key Features of Graph RAG
- Multi-hop Reasoning: Answers complex queries by traversing relationships across multiple entities.
- Contextual Depth: Retrieves not just facts, but the relationships and context connecting them.
- Structured Data Integration: Ideal for enterprise data, scientific research, and compliance scenarios.
- Explainability: Provides transparent reasoning paths, improving trust and auditability.
Learn more about advanced RAG techniques in the Large Language Models Bootcamp.
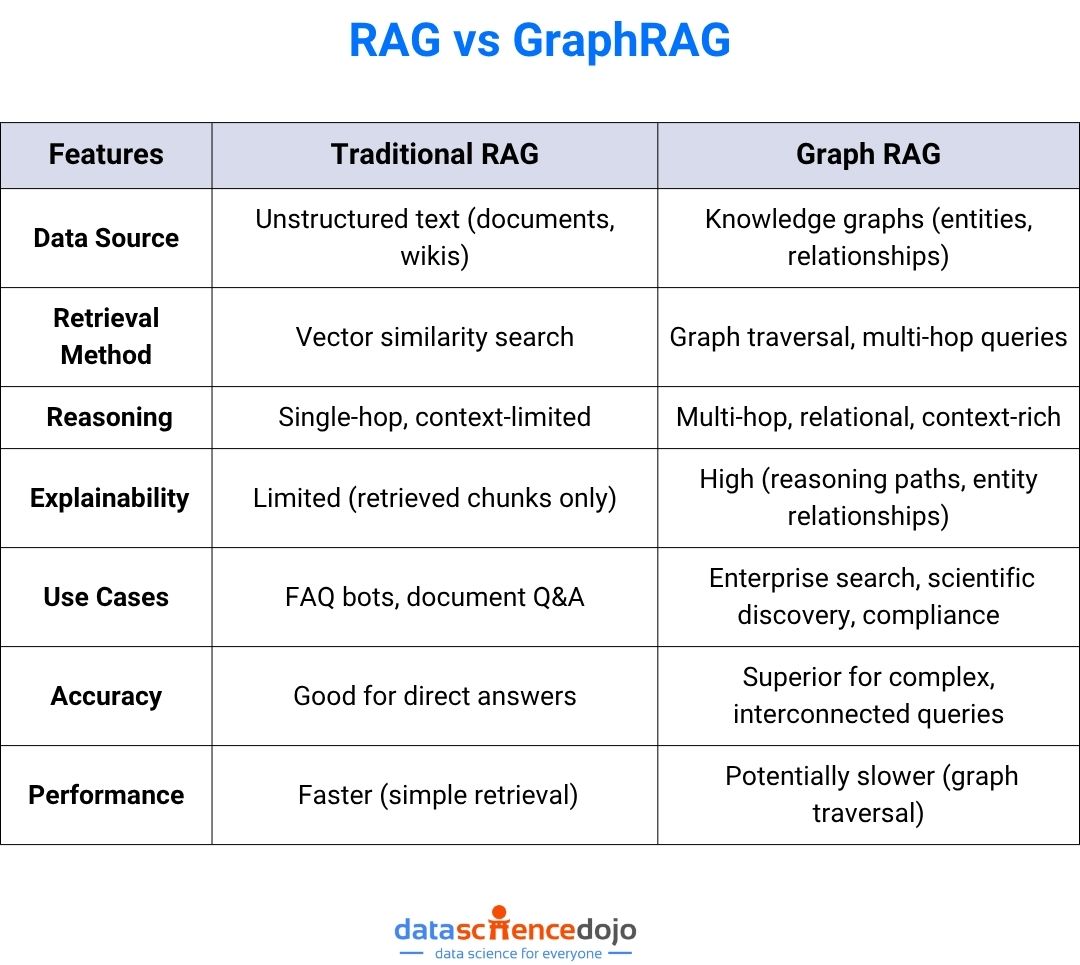
Technical Architecture: RAG vs Graph RAG
Traditional RAG Pipeline
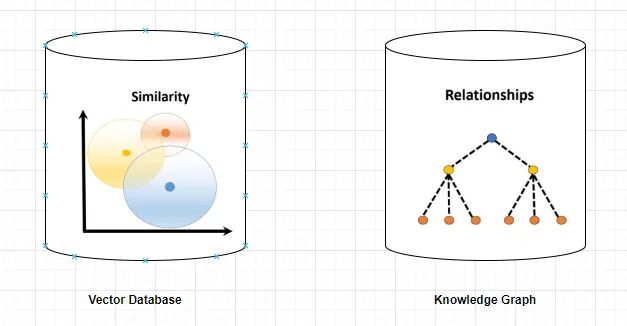
- Vector Database: Stores embeddings of text chunks.
- Retriever: Finds top-k relevant chunks for a query using vector similarity.
- LLM: Generates a response using retrieved context.
Limitations:
Traditional RAG is limited to single-hop retrieval and struggles with queries that require understanding relationships or synthesizing information across multiple documents.
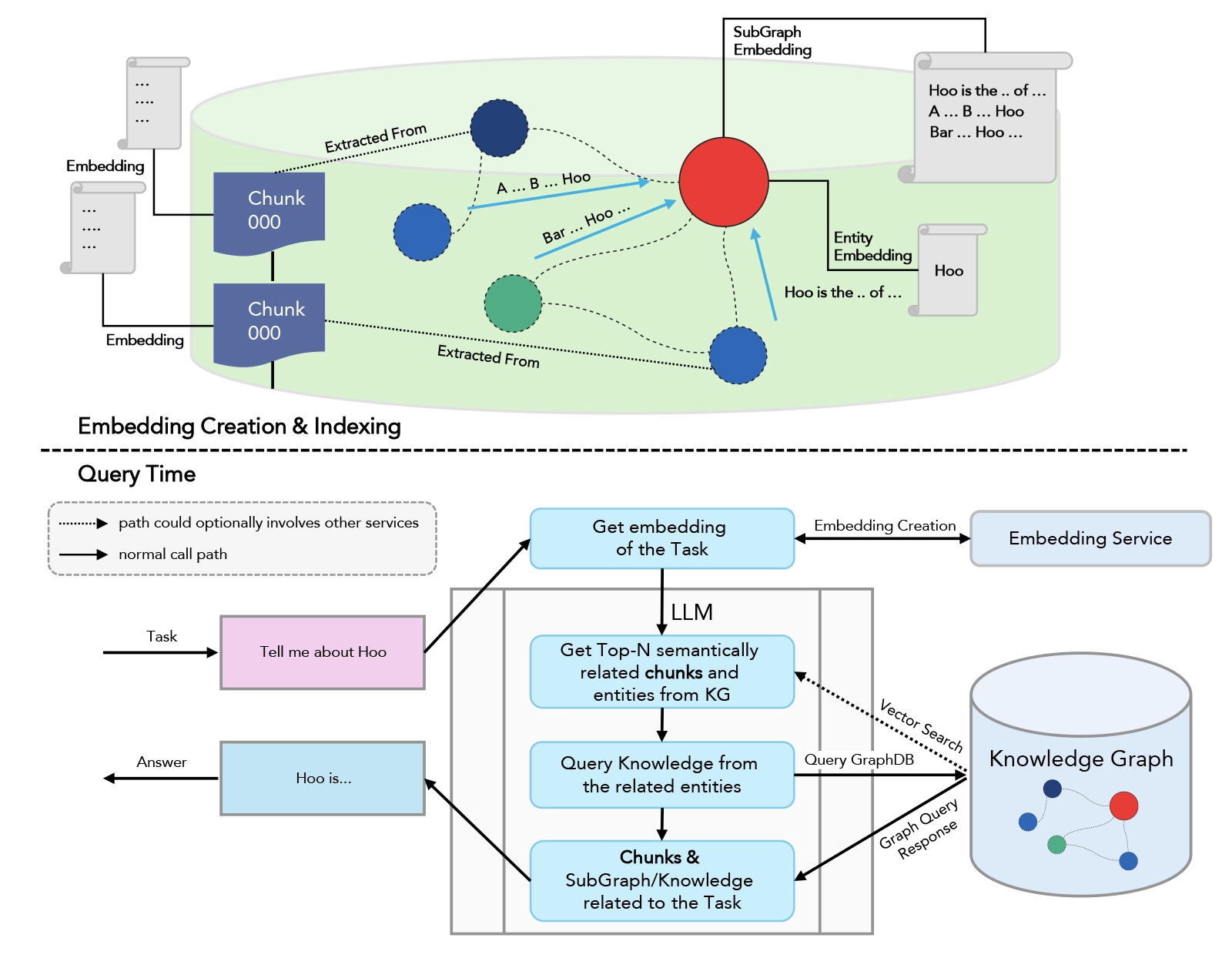
Graph RAG Pipeline
- Knowledge Graph: Stores entities and their relationships as nodes and edges.
- Graph Retriever: Traverses the graph to find relevant nodes, paths, and multi-hop connections.
- LLM: Synthesizes a response using both entities and their relationships, often providing reasoning chains.
Why Graph RAG Excels:
Graph rag enables LLMs to answer questions that require understanding of how concepts are connected, not just what is written in isolated paragraphs. For example, in healthcare, graph rag can connect symptoms, treatments, and patient history for more accurate recommendations.
For a technical deep dive, see Mastering LangChain and Retrieval Augmented Generation.
Key Differences and Comparative Analysis
Use Cases: When to Use RAG vs Graph RAG
Traditional RAG
- Customer support chatbots
- FAQ answering
- Document summarization
- News aggregation
- Simple enterprise search
Graph RAG
- Enterprise AI: Unified search across siloed databases, CRMs, and wikis.
- Healthcare: Multi-hop reasoning over patient data, treatments, and research.
- Finance: Compliance checks by tracing relationships between transactions and regulations.
- Scientific Research: Discovering connections between genes, diseases, and drugs.
- Personalization: Hyper-personalized recommendations by mapping user preferences to product graphs.
Explore more enterprise applications in Data and Analytics Services.
Case Studies: Real-World Impact
Case Study 1: Healthcare Knowledge Assistant
A leading hospital implemented graph rag to power its clinical decision support system. By integrating patient records, drug databases, and medical literature into a knowledge graph, the assistant could answer complex queries such as:
- “What is the recommended treatment for a diabetic patient with hypertension and a history of kidney disease?”
Impact:
- Reduced diagnostic errors by 30%
- Improved clinician trust due to transparent reasoning paths
Case Study 2: Financial Compliance
A global bank used graph rag to automate compliance checks. The system mapped transactions, regulations, and customer profiles in a knowledge graph, enabling multi-hop queries like:
- “Which transactions are indirectly linked to sanctioned entities through intermediaries?”
Impact:
- Detected 2x more suspicious patterns than traditional RAG
- Streamlined audit trails for regulatory reporting
Case Study 3: Data Science Dojo’s LLM Bootcamp
Participants in the LLM Bootcamp built both RAG and graph rag pipelines. They observed that graph rag consistently outperformed RAG in tasks requiring reasoning across multiple data sources, such as legal document analysis and scientific literature review.
Best Practices for Implementation
-
Start with RAG:
Use traditional RAG for unstructured data and simple Q&A.
-
Adopt Graph RAG for Complexity:
When queries require multi-hop reasoning or relationship mapping, transition to graph rag.
-
Leverage Hybrid Approaches:
Combine vector search and graph traversal for maximum coverage.
-
Monitor and Benchmark:
Use hybrid scorecards to track both AI quality and engineering velocity.
-
Iterate Relentlessly:
Experiment with chunking, retrieval, and prompt formats for optimal results.
-
Treat Context as a Product:
Apply version control, quality checks, and continuous improvement to your context pipelines.
-
Structure Prompts Clearly:
Separate instructions, context, and queries for clarity.
-
Leverage In-Context Learning:
Provide high-quality examples in the prompt.
-
Security and Compliance:
Guard against prompt injection, data leakage, and unauthorized tool use.
-
Ethics and Privacy:
Ensure responsible use of interconnected personal or proprietary data.
For more, see What is Context Engineering?
Challenges, Limitations, and Future Trends
Challenges
- Context Quality Paradox: More context isn’t always better—balance breadth and relevance.
- Scalability: Graph rag can be resource-intensive; optimize graph size and traversal algorithms.
- Security: Guard against data leakage and unauthorized access to sensitive relationships.
- Ethics and Privacy: Ensure responsible use of interconnected personal or proprietary data.
- Performance: Graph traversal can introduce latency compared to vector search.
Future Trends
- Context-as-a-Service: Platforms offering dynamic context assembly and delivery.
- Multimodal Context: Integrating text, audio, video, and structured data.
- Agentic AI: Embedding graph rag in multi-step agent loops with planning, tool use, and reflection.
- Automated Knowledge Graph Construction: Using LLMs and data pipelines to build and update knowledge graphs in real time.
- Explainable AI: Graph rag’s reasoning chains will drive transparency and trust in enterprise AI.
Emerging trends include context-as-a-service platforms, multimodal context (text, audio, video), and contextual AI ethics frameworks. For more, see Agentic AI.
Frequently Asked Questions (FAQ)
Q1: What is the main advantage of graph rag over traditional RAG?
A: Graph rag enables multi-hop reasoning and richer, more accurate responses by leveraging relationships between entities, not just isolated facts.
Q2: When should I use graph rag?
A: Use graph rag when your queries require understanding of how concepts are connected—such as in enterprise search, compliance, or scientific discovery.
Q3: What frameworks support graph rag?
A: Popular frameworks include LangChain and LlamaIndex, which offer orchestration, memory management, and integration with vector databases and knowledge graphs.
Q4: How do I get started with RAG and graph rag?
A: Begin with Retrieval Augmented Generation and explore advanced techniques in the LLM Bootcamp.
Q5: Is graph rag slower than traditional RAG?
A: Graph rag can be slower due to graph traversal and reasoning, but it delivers superior accuracy and explainability for complex queries 1.
Q6: Can I combine RAG and graph rag in one system?
A: Yes! Many advanced systems use a hybrid approach, first retrieving relevant documents with RAG, then mapping entities and relationships with graph rag for deeper reasoning.
Conclusion & Next Steps
Graph rag is redefining what’s possible with retrieval-augmented generation. By enabling LLMs to reason over knowledge graphs, organizations can unlock new levels of accuracy, transparency, and insight in their AI systems. Whether you’re building enterprise AI, scientific discovery tools, or next-gen chatbots, understanding the difference between graph rag and traditional RAG is essential for staying ahead.
Ready to build smarter AI?
- Explore Data Science Dojo’s LLM Bootcamp for hands-on training.
- Dive into Mastering LangChain for practical graph rag workflows.
- Stay updated with the latest in Agentic AI.