If you’ve been following developments in open-source LLMs, you’ve probably heard the name Kimi K2 pop up a lot lately. Released by Moonshot AI, this new model is making a strong case as one of the most capable open-source LLMs ever released.
From coding and multi-step reasoning to tool use and agentic workflows, Kimi K2 delivers a level of performance and flexibility that puts it in serious competition with proprietary giants like GPT-4.1 and Claude Opus 4. And unlike those closed systems, Kimi K2 is fully open source, giving researchers and developers full access to its internals.
In this post, we’ll break down what makes Kimi K2 so special, from its Mixture-of-Experts architecture to its benchmark results and practical use cases.
Learn more about our Large Language Models in our detailed guide!
What is Kimi K2?

Kimi K2 is an open-source large language model developed by Moonshot AI, a rising Chinese AI company. It’s designed not just for natural language generation, but for agentic AI, the ability to take actions, use tools, and perform complex workflows autonomously.
At its core, Kimi K2 is built on a Mixture-of-Experts (MoE) architecture, with a total of 1 trillion parameters, of which 32 billion are active during any given inference. This design helps the model maintain efficiency while scaling performance on-demand.
Moonshot released two main variants:
-
Kimi-K2-Base: A foundational model ideal for customization and fine-tuning.
-
Kimi-K2-Instruct: Instruction-tuned for general chat and agentic tasks, ready to use out-of-the-box.
Under the Hood: Kimi K2’s Architecture
What sets Kimi K2 apart isn’t just its scale—it’s the smart architecture powering it.
1. Mixture-of-Experts (MoE)
Kimi K2 activates only a subset of its full parameter space during inference, allowing different “experts” in the model to specialize in different tasks. This makes it more efficient than dense models of a similar size, while still scaling to complex reasoning or coding tasks when needed.
Want a detailed understanding of how Mixture Of Experts works? Check out our blog!
2. Training at Scale
-
Token volume: Trained on a whopping 15.5 trillion tokens
-
Optimizer: Uses Moonshot’s proprietary MuonClip optimizer to ensure stable training and avoid parameter blow-ups.
-
Post-training: Fine-tuned with synthetic data, especially for agentic scenarios like tool use and multi-step problem solving.
Performance Benchmarks: Does It Really Beat GPT-4.1?
Early results suggest that Kimi K2 isn’t just impressive, it’s setting new standards in open-source LLM performance, especially in coding and reasoning tasks.
Here are some key benchmark results (as of July 2025):
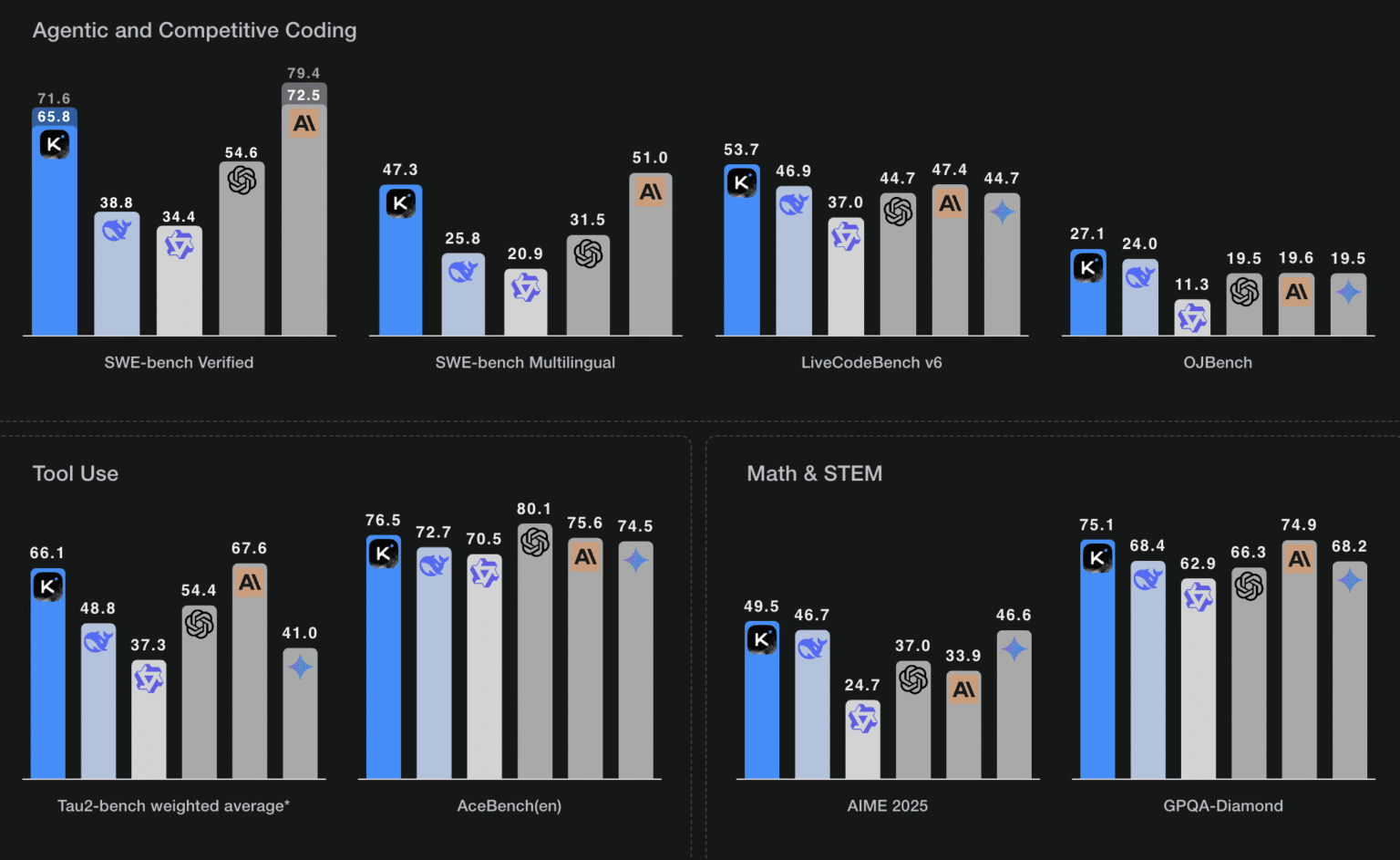
Key takeaway:
- Kimi k2 outperforms GPT-4.1 and Claude Opus 4 in several coding and reasoning benchmarks.
- Excels in agentic tasks, tool use, and complex STEM challenges.
- Delivers top-tier results while remaining open-source and cost-effective.
Learn more about Benchmarks and Evaluation in LLMs
Distinguishing Features of Kimi K2
1. Agentic AI Capabilities
Kimi k2 is not just a chatbot, it’s an agentic AI capable of executing shell commands, editing and deploying code, building interactive websites, integrating with APIs and external tools, and orchestrating multi-step workflows. This makes kimi k2 a powerful tool for automation and complex problem-solving.
2. Tool Use Training
The model was post-trained on synthetic agentic data to simulate real-world scenarios like:
-
Booking a flight
-
Cleaning datasets
-
Building and deploying websites
-
Self-evaluation using simulated user feedback
3. Open Source + Cost Efficiency
-
Free access via Kimi’s web/app interface
-
Model weights available on Hugging Face and GitHub
-
Inference compatibility with popular engines like vLLM, TensorRT-LLM, and SGLang
-
API pricing: Much lower than OpenAI and Anthropic—about $0.15 per million input tokens and $2.50 per million output tokens
Real-World Use Cases
Here’s how developers and teams are putting Kimi K2 to work:
Software Development
-
Generate, refactor, and debug code
-
Build web apps via natural language
-
Automate documentation and code reviews
Data Science
-
Clean and analyze datasets
-
Generate reports and visualizations
-
Automate ML pipelines and SQL queries
Business Automation
-
Automate scheduling, research, and email
-
Integrate with CRMs and SaaS tools via APIs
Education
-
Tutor users on technical subjects
-
Generate quizzes and study plans
-
Power interactive learning assistants
Research
-
Conduct literature reviews
-
Auto-generate technical summaries
-
Fine-tune for scientific domains
Example: A fintech startup uses Kimi K2 to automate exploratory data analysis (EDA), generate SQL from English, and produce weekly business insights—reducing analyst workload by 30%.
How to Access and Fine-Tune Kimi K2
Getting started with Kimi K2 is surprisingly simple:
Access Options
-
Web/App: Use the model via Kimi’s chat interface
-
API: Integrate via Moonshot’s platform (supports agentic workflows and tool use)
-
Local: Download weights (via Hugging Face or GitHub) and run using:
-
vLLM
-
TensorRT-LLM
-
SGLang
-
KTransformers
-
Fine-Tuning
-
Use LoRA, QLoRA, or full fine-tuning techniques
-
Customize for your domain or integrate into larger systems
-
Moonshot and the community are developing open-source tools for production-grade deployment
What the Community Thinks
So far, Kimi K2 has received an overwhelmingly positive response—especially from developers and researchers in open-source AI.
-
Praise: Strong coding performance, ease of integration, solid benchmarks
-
Concerns: Like all LLMs, it’s not immune to hallucinations, and there’s still room to grow in reasoning consistency
The release has also stirred broader conversations about China’s growing AI influence, especially in the open-source space.
Final Thoughts
Kimi K2 isn’t just another large language model. It’s a statement—that open-source AI can be state-of-the-art. With powerful agentic capabilities, competitive benchmark performance, and full access to weights and APIs, it’s a compelling choice for developers looking to build serious AI applications.
If you care about performance, customization, and openness, Kimi K2 is worth exploring.
What’s Next?
-
Try it out at chat.kimi.com
-
Explore the weights on Hugging Face
-
Follow Moonshot AI’s GitHub for updates
-
Learn more about finetuning in our Large Language Model Bootcamp
FAQs
Q1: Is Kimi K2 really open-source?
Yes—weights and model card are available under a permissive license.
Q2: Can I run it locally?
Absolutely. You’ll need a modern inference engine like vLLM or TensorRT-LLM.
Q3: How does it compare to GPT-4.1 or Claude Opus 4?
In coding benchmarks, it performs on par or better. Full comparisons in reasoning and chat still evolving.
Q4: Is it good for tool use and agentic workflows?
Yes—Kimi K2 was explicitly post-trained on tool-use scenarios and supports multi-step workflows.
Q5: Where can I follow updates?
Moonshot AI’s GitHub and community forums are your best bets.