

Welcome to Data Science Dojo’s weekly newsletter, “The Data-Driven Dispatch“.
Humans love to fantasize. Some of us keep those dreams locked up in our heads, while others get them down on paper with a bit of drawing. Then there are those who go all out, turning their dreams into movies or plays.
Now, with OpenAI dropping this new tool called Sora (meaning “Sky” in Japanese), pretty much anyone can turn their wild ideas into something you can see and hear, even if it’s just for a short bit.
Sounds like something straight out of a sci-fi movie. But guess what? It’s about to be real.
Before we all dive headfirst into this, we’ve got to stop and think a bit.
How are tools like Sora going to change things for all of us?
It’s a big deal, and it’s worth taking a moment to figure out what it all means for our society. Let’s dig in!

What is Sora? What does it have in store for us?
Sora is a generalist visual data model capable of producing videos and images across a wide range of durations, aspect ratios, and resolutions, including high-definition videos of up to one full minute.
In addition to generating videos from scratch, it can also add to existing images and videos. How? The graphic talks about this in detail.
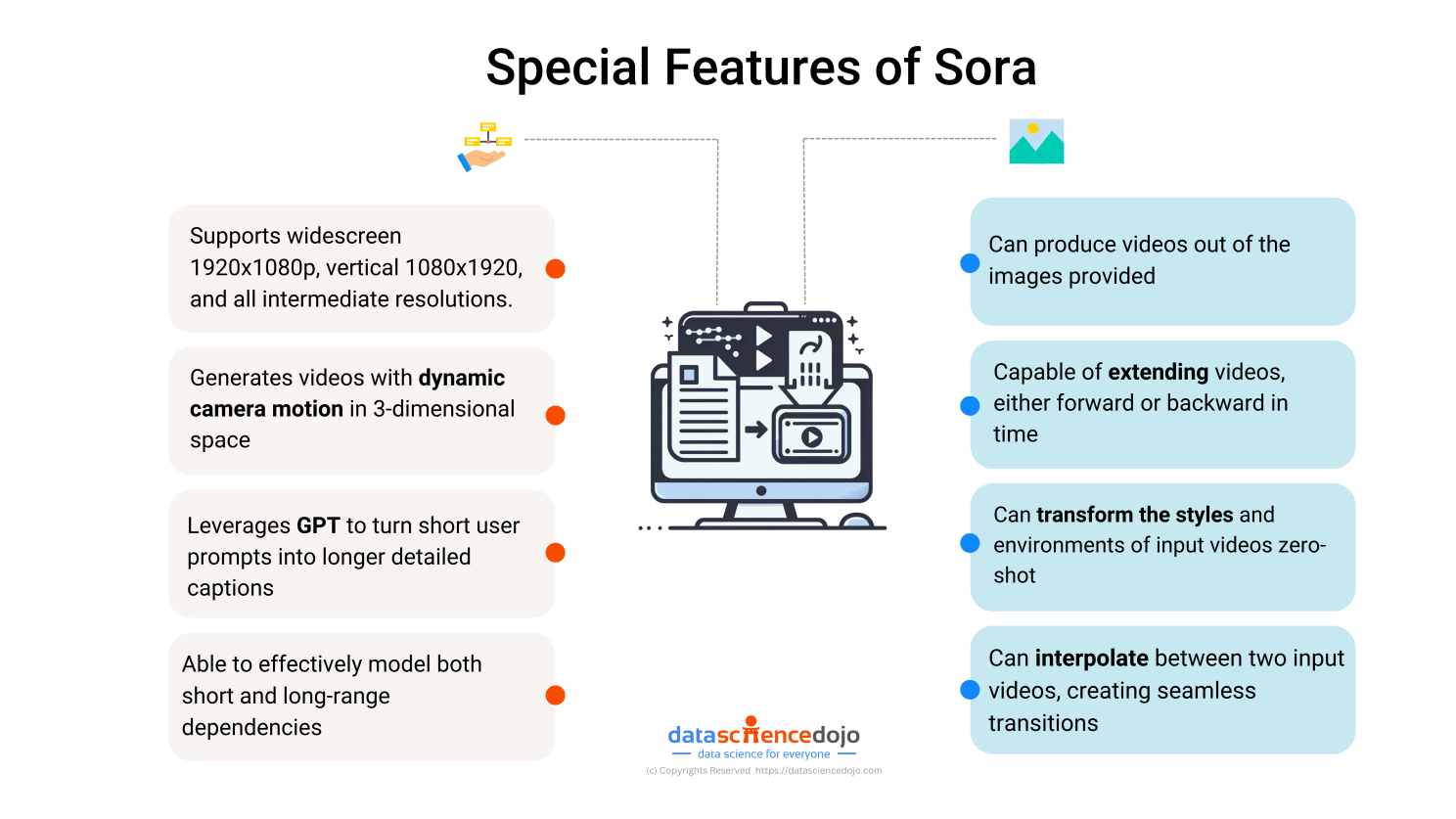
Explore More: Understanding Sora: An OpenAI Model for Video Generation
How does Sora work? How are its generative capabilities inspired by Large Language Models
Just as large language models excel in generating language due to their use of tokens that seamlessly incorporate information from a wide range of formats—including text, code, mathematics, and various natural languages—Sora achieves its accuracy through a similar mechanism adapted for visual content.
Instead of tokens, Sora utilizes ‘visual patches’. These patches allow it to effectively blend and interpret visual information.

This innovative approach is grounded in the integration of two foundational technologies i.e. diffusion models, and transformers, that were used separately before.
Diffusion models have been pivotal in generating high-quality images, while transformers have excelled in processing sequential data, like text, to produce coherent and contextually relevant outputs.
Sora marries these two approaches by adapting the transformer architecture to handle the sequential nature of video data, thus ensuring temporal coherence, and harnessing the power of diffusion models to create detailed and visually appealing content.
Read More: Video Generation Models as World Simulators | OpenAI
How will video generation models impact society
Every new technology brings its own set of positives and negatives.
On the positive end, making videos with such ease could bring a lot of benefits to various industries. One of the major ones is education. Imagine all the developing world countries where AI could help make educational content in regional languages to educate children.
Applications like this will also greatly impact the film-making, marketing, and advertising industries. Highly tailored and personalized video ads could become commonplace.
On the negative end, there will be tons of challenges we’ll be facing, with the spread of misinformation, and misuse of deepfakes being at the top.
This makes it imperative for us to make mechanisms alongside such applications that can help differentiate between truth and AI-generated Farce.
How is OpenAI working towards the secure use of its video generation tools?
OpenAI is taking several measures to ensure the safe development of its video generation model.
- Fake-Image Detection: Leveraging technology developed for DALL-E 3, OpenAI is adapting a fake-image detector for use with Sora.
- Metadata Embedding: To enhance transparency, all of the tool’s outputs will include C2PA tags—industry-standard metadata that details how the content was generated.
- Content Filtering: It incorporates sophisticated filters that evaluate prompts. These filters are designed to block requests for creating content that’s violent, sexual, hateful, or features known individuals.

Unpopular opinion: MS Excel was living in the generative AI era long before it started! 🙈
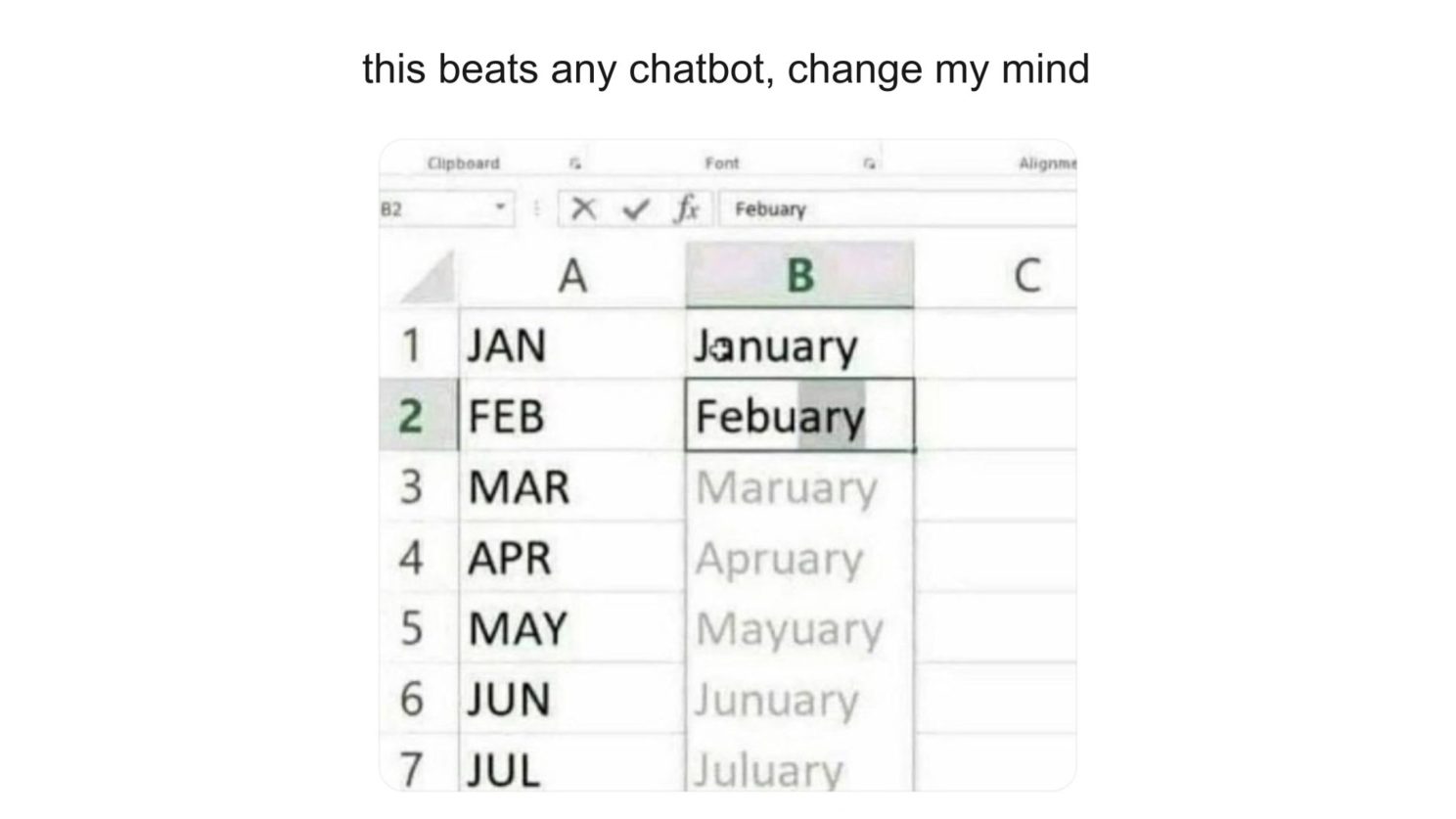

Leading the generative AI motion with large language models
With video-making being added to the generative capabilities of gen AI tools, we can already see a new dawn of AI on the horizon.
It is important for us to lead this new AI revolution by learning most about LLMs and then implementing them in our day-to-day tasks for maximized productivity.
Here’s a roadmap that covers the necessary domains you ought to learn to master LLMs.
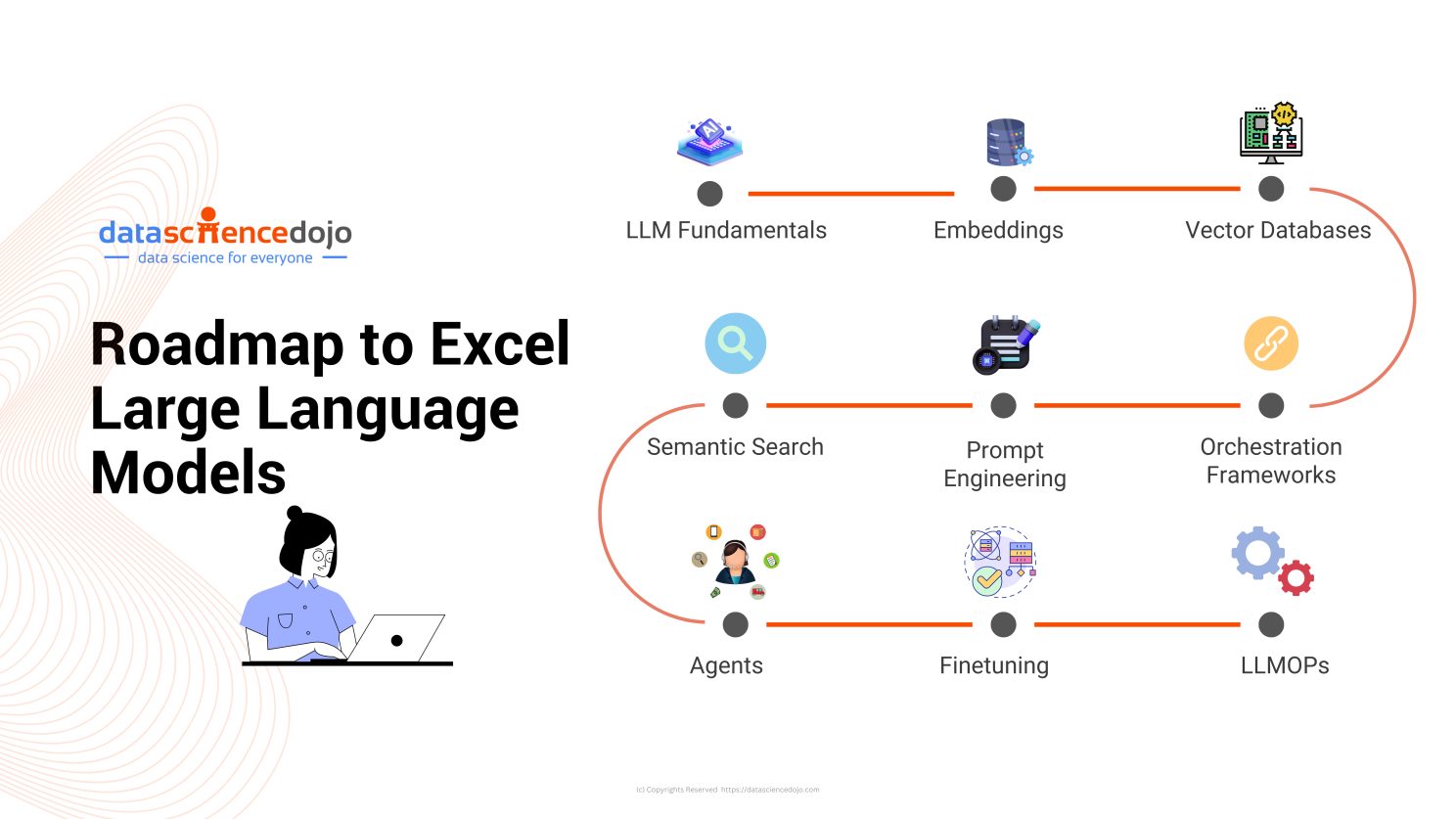
Dive deeper: The Journey to LLM Expertise: Part 1 – Dominating 9 Essential Domains
You can also learn more about these domains from expert speaker sessions on this YouTube playlist.

This week was one of the craziest weeks in AI. Here are some highlights worth reading:
- Google launches Gemini 1.5 featuring breakthrough long-context understanding and superior performance. Read more
- Apple readies AI tool to rival Microsoft’s GitHub Copilot as part of its plan to expand the capabilities of Xcode. Read more
- ChatGPT introduces a memory feature for enhanced personalization, offering users control over conversational continuity. Read more
- Over 20 tech giants including Google, Meta, Microsoft, OpenAI, and TikTok pledge to combat AI-generated election misinformation with transparency and collaboration efforts. Read more
- Meta advances AI with V-JEPA model for enhanced video understanding, aiming for human-like learning. Read more