

Building a powerful machine learning model isn’t just about feeding it data and training it to get the best possible accuracy. Sometimes, a model learns too well — capturing noise, overfitting the training data, and stumbling when faced with real-world scenarios. On the other end of the spectrum, a model might be too simplistic to catch important patterns, leading to underfitting. That’s where regularization in machine learning comes into play.
Regularization is like a balancing act. It helps machine learning models stay flexible enough to learn from data while avoiding the trap of becoming too complex or too rigid. Whether you’re just getting started or brushing up your skills, understanding how regularization works — and when to use techniques like Lasso (L1) and Ridge (L2) — is essential for building models that perform well in the wild.
In this blog, we’ll break down the concept of regularization, why it matters, and how you can apply it effectively to train more reliable models. Let’s dive in!

What is Overfitting?
In machine learning, when we build a model, we typically begin by training it on a set of data known as the training set. The ultimate goal is to create a model that can generalize well, meaning it should make accurate predictions on new, unseen data (known as the test set).
However, things don’t always go according to plan. In some cases, a model can become too specialized to the training data, causing it to perform exceptionally well on that data but fail to predict outcomes accurately on the test data. This is known as overfitting.
Overfitting occurs when the model is too complex relative to the amount of data available. It essentially “memorizes” the training data rather than learning the underlying patterns and relationships. When this happens, the model gets overly attuned to the specific details and noise within the training data, such as irrelevant fluctuations, outliers, or anomalies. While the model might show excellent accuracy on the training set, it struggles to generalize to new data, leading to poor performance when tested on data it hasn’t seen before.
How Does Overfitting Happen?
Overfitting can happen in various ways, such as when:
-
Too many features are used: If there are a large number of input features (variables), the model may fit too closely to the training data, incorporating noise and irrelevant features into its predictions.
-
Excessive model complexity: Complex models, such as deep neural networks with many layers, have high flexibility and can easily model every minor fluctuation in the data, leading to overfitting. Models like decision trees can also overfit if they are allowed to grow too deep, creating many splits that fit perfectly to the training data but fail to generalize.
-
Insufficient training data: When there is not enough data to capture the underlying patterns, the model is forced to memorize the available examples instead of learning general trends. In this case, the model will fail to perform well on new data because it has learned patterns that are specific only to the training set.
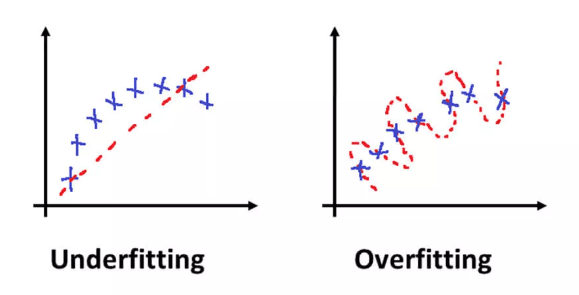
What is Underfitting?
In the world of machine learning, underfitting is the opposite of overfitting. While overfitting occurs when a model becomes too complex and fits the training data too closely, underfitting happens when a model is too simplistic to adequately capture the underlying patterns in the data. In essence, underfitting occurs when a model is not powerful enough to learn from the data, leading to poor performance both on the training set and unseen data.
Why Does Underfitting Happen?
Underfitting typically occurs in the following situations:
-
Model simplicity: When the model is too simple for the complexity of the data, it fails to capture important relationships. For instance, using a linear regression model to predict data that has a non-linear relationship is likely to result in underfitting. The model won’t be flexible enough to account for more intricate patterns.
-
Inadequate training time: If a model is not trained for a sufficient amount of time or on enough iterations, it might not have the opportunity to learn the key patterns from the data. Essentially, it doesn’t have enough “experience” to make accurate predictions.
-
Not enough features: Sometimes, underfitting happens because the model lacks enough input features or data to understand the full complexity of the problem. For example, when building a model for predicting house prices, excluding essential features like location or square footage might result in a poor-performing model.
-
Too much regularization: Regularization techniques like L1 and L2 are used to prevent overfitting, but if they are applied too aggressively, they can cause underfitting. Regularization reduces the model’s complexity by penalizing large coefficients, which can make the model too rigid and unable to capture the true data relationships.

How Does Regularization in Machine Learning Work?
Regularization is a technique used in machine learning to prevent overfitting by discouraging overly complex models that might fit too closely to the training data. When a model overfits, it becomes too specific to the training data, capturing noise and irrelevant patterns that don’t generalize well to unseen data. Regularization helps create a simpler model that balances accuracy and generalization.
The way regularization works is by adding a penalty term to the model’s loss function, which is the function the model tries to minimize during training. This penalty term penalizes large coefficients or weights in the model, which helps to avoid overfitting. Regularization forces the model to be less sensitive to fluctuations in the training data, thus encouraging it to focus on the most important patterns.
The Core Idea Behind Regularization
The core idea behind regularization is straightforward: reduce model complexity. The more complex a model becomes, the higher the risk that it will overfit the training data. Regularization, therefore, introduces a way to penalize complexity, making it harder for the model to overfit. By penalizing large model parameters, regularization keeps the model simpler and more likely to generalize well when applied to new, unseen data.
Impact of Regularization
-
Prevents Overfitting: Regularization keeps the model from fitting noise in the training data and helps it focus on the main underlying patterns, improving performance on test data.
-
Improves Model Generalization: By controlling complexity, regularization helps the model generalize better to new, unseen data, ensuring it performs well beyond the training set.
-
Balances Bias and Variance: In machine learning, models need to strike a balance between bias (error due to overly simple models) and variance (error due to overly complex models). Regularization helps achieve this balance by controlling how flexible the model can be.
Read more –> Machine learning model deployment 101: A comprehensive guide
Types of Regularization
There are several types of regularization techniques used in machine learning, including L1, L2, and dropout.
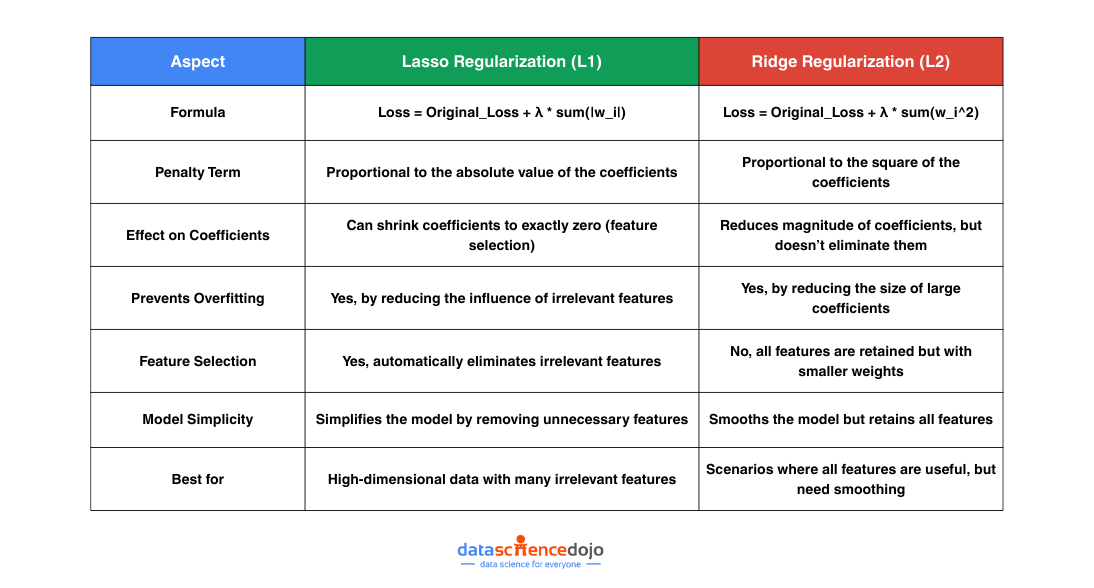
1. Lasso regularization (L1)
Lasso regularization in machine learning, or L1 regularization, is a widely used technique to prevent overfitting and improve the interpretability of the model. This regularization method works by adding a penalty term to the model’s cost function that is proportional to the absolute values of its coefficients (or weights). This penalty encourages the model to reduce the magnitude of the weights, and in some cases, it can even drive certain coefficients to zero, effectively eliminating features from the model.
How Lasso Regularization in Machine Learning Works
Lasso regularization in machine learning works by modifying the model’s loss function (which the model tries to minimize). The penalty term added to the loss function is proportional to the sum of the absolute values of the model’s coefficients. This penalty forces the model to limit the size of the weights. The formula for Lasso regularization looks like this:
Loss = Original_Loss + λ * sum(|w_i|)
Here:
-
Original Loss refers to the typical loss function (e.g., Mean Squared Error in regression tasks).
-
λ\lambda is the regularization parameter that controls the strength of the penalty.
-
wiw_i are the model’s coefficients.
The central concept of Lasso regularization in machine learning is to apply a penalty to larger weights, which prevents the model from overfitting by learning overly complex patterns from the training data. By shrinking the coefficients toward zero, the model is forced to focus on the most important features and ignore irrelevant ones.
Code snippet for L1 regularization using Python and scikit-learn:
Feature Selection with Lasso
One of the standout features of Lasso regularization in machine learning is its ability to perform feature selection. Unlike other regularization techniques, which simply shrink the coefficients, Lasso has the unique ability to reduce some coefficients to exactly zero. This means that Lasso can automatically eliminate features that don’t contribute significantly to the model’s predictions, leading to a simpler, more efficient model.
For example, if you’re working with a dataset containing hundreds of features, many of which may be irrelevant to the target variable, Lasso regularization in machine learning will drive the coefficients of those irrelevant features to zero. This feature selection property makes Lasso especially valuable when dealing with high-dimensional datasets, where manual feature selection would be challenging.
Why Use Lasso Regularization in Machine Learning?
-
Prevents Overfitting:
Lasso regularization in machine learning helps prevent overfitting by penalizing large model coefficients. This forces the model to focus on the most essential features, ensuring it does not memorize the training data, which could hurt performance on unseen data. -
Simplifies the Model:
Lasso regularization simplifies the model by eliminating irrelevant features and reducing the complexity of the model. This results in a model that is easier to interpret, more computationally efficient, and less likely to overfit. -
Automatic Feature Selection:
The ability to drive some coefficients to zero automatically eliminates unnecessary features, which is particularly useful in situations where there are many features and only a few are relevant. Lasso regularization in machine learning helps build a more efficient model by keeping only the important features. -
Enhances Interpretability:
When Lasso regularization in machine learning is applied, the resulting model is often much simpler and easier to interpret. For example, in finance, Lasso could be used to identify the most significant factors affecting loan defaults, such as credit score and income, while discarding less important features.
2. Ridge regularization (L2)
Ridge regularization in machine learning, or L2 regularization, is an essential technique that helps improve the performance of machine learning models by preventing overfitting. This regularization method works by adding a penalty term to the model’s cost function that is proportional to the square of the model’s weights. The penalty discourages excessively large weights, which helps reduce model complexity and improves the model’s ability to generalize to new, unseen data.
How Ridge Regularization in Machine Learning Works
Ridge regularization operates by modifying the model’s loss function, adding a term proportional to the sum of the squares of the model’s coefficients. This penalty term is designed to reduce the size of the weights, encouraging the model to find simpler relationships between the input features and the output target. The formula for the Ridge regularization loss function is:
Where:
-
Original Loss is the loss function that measures the model’s prediction error (e.g., Mean Squared Error in regression tasks).
-
λ\lambda is the regularization parameter that controls the strength of the penalty.
-
wiw_i are the model’s weights or coefficients.
In this case, the penalty term is proportional to the square of the weights, unlike Lasso regularization (L1), which uses the absolute value of the weights. The square of the weights means that larger coefficients incur a heavier penalty, forcing the model to minimize these large values, thus avoiding overfitting.
Code snippet for L2 regularization using Python and scikit-learn:
Key Characteristics of Ridge Regularization
-
Prevents Overfitting:
Ridge regularization helps prevent overfitting by penalizing large weights. In cases where a model fits the training data too closely, Ridge regularization reduces the influence of less important features, making the model more robust and improving its ability to generalize to new, unseen data. -
Smoothens the Model:
The squaring of the weights ensures that Ridge regularization smooths out the model’s predictions, making it more stable and less likely to be sensitive to noise or fluctuations in the data. This smoothing effect is particularly beneficial when dealing with high-dimensional datasets where noise or irrelevant features might lead to overfitting. -
Does Not Eliminate Features:
Unlike Lasso regularization (L1), which can shrink coefficients to zero and effectively eliminate features from the model, Ridge regularization in machine learning tends to reduce the magnitude of all coefficients but does not force any of them to exactly zero. This means that Ridge regularization generally results in a model that uses all available features, albeit with smaller weights. -
Improves Generalization:
By reducing the impact of large coefficients, Ridge regularization ensures that the model does not become overly complex. This helps the model generalize better to new data, making it less likely to fit to noise in the training set and more likely to perform well on unseen examples.
Conclusion
In a nutshell, regularization in machine learning plays a crucial role in machine learning as it helps address overfitting issues and enhances model accuracy, simplicity, and interpretability. It achieves this by introducing a penalty term to the loss function during training, promoting the selection of simpler solutions that can generalize well to unseen data.
Among the various regularization techniques, L2 regularization is widely employed in practice. In summary, regularization is an invaluable asset for machine learning practitioners and is expected to gain further prominence as the field advances.
Written by Muhammad Rizwan
