

What is similar between a child learning to speak and an LLM learning the human language? They both learn from examples and available information to understand and communicate.
For instance, if a child hears the word ‘apple’ while holding one, they slowly associate the word with the object. Repetition and context will refine their understanding over time, enabling them to use the word correctly.
Learn how LLM Development Making Chatbots Smarter
Similarly, an LLM like GPT learns from massive datasets like books, conversations, web pages, and more. The robot learns the patterns in language, understanding grammar, meaning, and usage. Algorithms fine-tune the responses to increase the LLM’s understanding over time.
Hence, the process of human learning and an LLM look alike, but there is a key difference in both. While a child learns based on their limited brain capacity, LLMs rely on billions of parameters to process and predict words. But how many parameters are needed for these models?

This is where the question of overparameterization in LLMs comes in – a strategy that enables LLMs to become flexible learners of human language. But is it the answer? How does an excess of parameters help and what risks can it bring?
In this blog, let’s explore the concept of overparameterization in LLMs, understand its pros and cons. We will also dig deeper into the tradeoff associated with this strategy and how one can navigate through it.
Explore the game-changing potential of Generative AI and LLMs
What is Overparameterization in LLMs?
Large language models (LLMs) rely on variables within the training data to learn the human language. These variables are known as parameters that also determine how the model will process and generate text. Overparameterization in LLMs refers to an ‘excess’ of parameters in the training of the language model.
Explore LLM Finance
It is a concept where a neural network like that of an LLM has more parameters than necessary to fit the training data. There are two main types of parameters:
Weights: These are the coefficients that connect neurons between different layers in a neural network, determining the strength and direction of influence one neuron has on another. During training, the model adjusts these weights to minimize the prediction error.
Biases: These are additional parameters added to the weighted sum of inputs to a neuron. They allow the model to shift the activation function, enabling it to fit the data better. Biases help the model to learn patterns that do not pass through the origin.
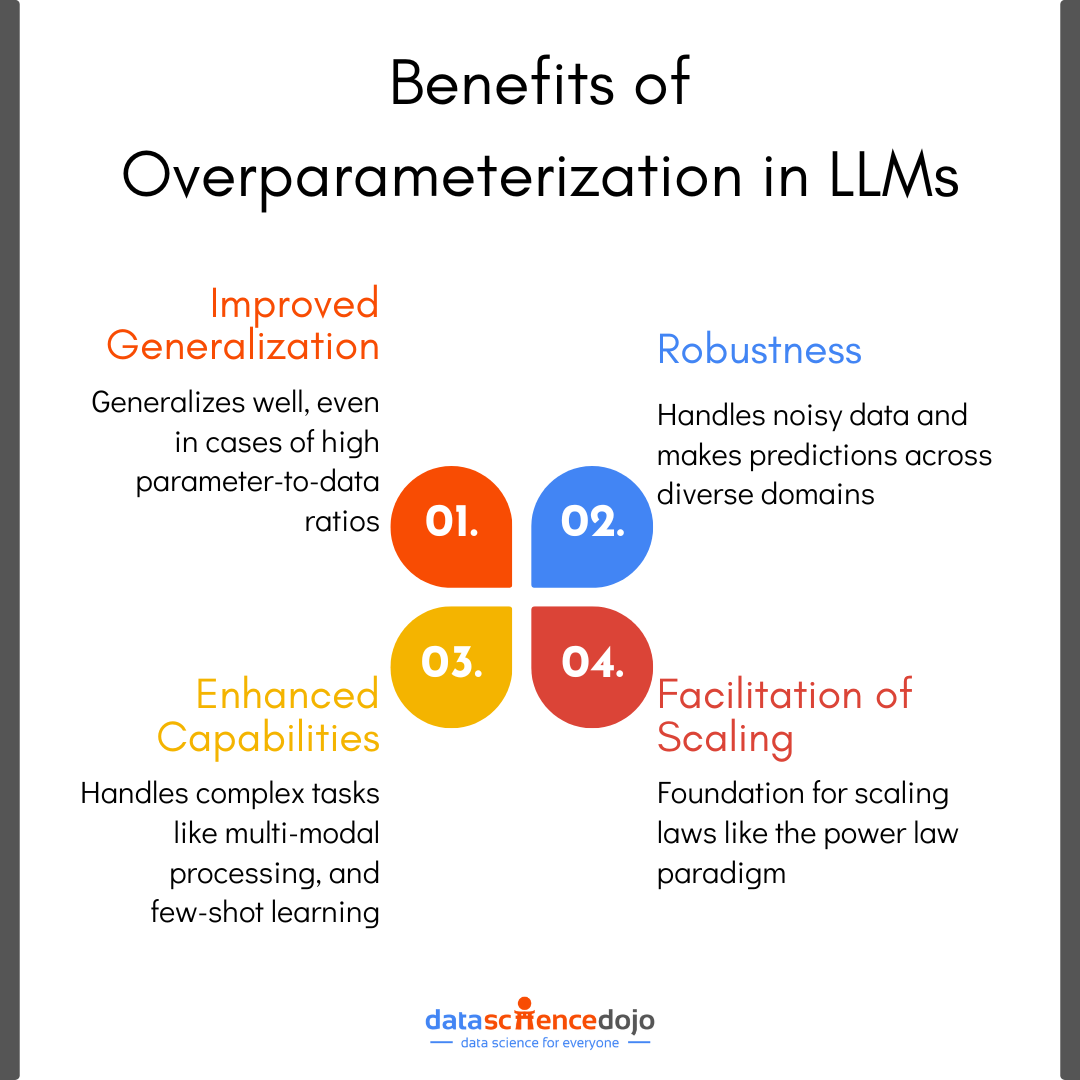
These parameters are adjusted during the training phase to train the language model to generate accurate predictions and meaningful outputs. With overparameterization in LLMs, the models have an excess of training variables, increasing the models’ capacity to learn and represent complex patterns within the data.
This approach has been considered counterintuitive in the past due to the risks of overfitting data points. Let’s take a closer look at the overparameterization-overfitting argument and debunk some myths associated with the idea.
Explore the myths and facts around prompt engineering
Debunking Myths About Overparameterization
The overparameterization-overfitting argument revolves around the relationship between the number of parameters in a model and its ability to generalize to new, unseen data. The traditional viewpoint believes that overparameterization can reduce the efficiency of the models.
But is that the case? Let’s look at some key myths associated with overparameterization and how they are debunked with new findings.
1. Overparameterization Always Leads to Overfitting
As per traditional views, it is believed that adding more parameters to a model leads to overfitting. As a result, the model becomes too flexible and captures noise as a data point as well. The LLM, thus, loses its ability to generalize its responses as it is unable to identify the underlying patterns in data due to the noise.
Dive deep into the top 7 Large Language Models (LLMs)
Debunked!
Empirical studies show that overparameterized models can indeed generalize well. The double descent also corroborates that increasing the model size enhances test performance. This is because modern optimization techniques, such as stochastic gradient descent (SGD) introduce implicit regularization.
Implicit regularization plays a crucial role in preventing overfitting in overparameterized models. SGD ensures that the model avoids fitting noise in the data. This challenges the traditional view and highlights the nuanced relationship between model size and performance.
2. More Parameters Always Harm Generalization
Aligning with the first myth we discussed of overfitting, it is also believed that increasing the parameters of LLMs can harm their generalization. It is believed that overparameterized LLMs become mere memorizing machines that lack the ability to learn generalizable patterns.
Debunked!
The evidence to debunk this myth lies in LLMs like GPT and Llama models that deliver state-of-the-art results across various tasks despite overparameterization. These models often generalize better than smaller models, capturing intricate patterns in the data.
In reality, overparameterized models create a richer representation space, making it easier for the model to capture complex patterns while avoiding overfitting to noise.
Understand the revolutionary AI technology of ChatGPT
3. Overparameterization is Inefficient and Unnecessary
Since a normal range of parameters enables language models to generate efficient outputs, a myth is associated with LLMs that overparameterization is unnecessary. Including an excess of parameters is considered inefficient.
Debunked!
The power law paradigm debunks this myth by showing that model performance improves predictably with increased model size, training data, and compute resources. It highlights that larger models can generalize well with enough data and compute power, avoiding overfitting.
Moreover, techniques like dropout, weight decay, and data augmentation further mitigate the risk of overfitting, even in overparameterized settings. These regularization strategies help maintain the model’s performance and prevent it from memorizing noise in the training data.

4. Overparameterized Models are Always Computationally Prohibitive
The myth suggests that models with a large number of parameters are too resource-intensive to be practical. It maintains that overparameterized models require substantial computing power for both training and inference.
Debunked!
The myth gets debunked by methods like pruning, quantization, and distillation which reduce the size and computational demands of overparameterized models without substantial loss in performance. Moreover, new model architectures are designed efficiently, requiring fewer parameters for achieving comparable performance.
5. Overparameterization Reduces Model Interpretability
It refers to the idea that as models become more complex with an increasing number of parameters, it becomes harder to understand how they make decisions. The sheer number of parameters and their interactions can obscure the model’s inner workings, making it challenging to interpret why certain predictions are made.
Debunked!
While true to some extent, techniques like attention visualization and probing tasks allow researchers to understand the inner workings of even massive models. Structured pruning techniques also help reduce the complexity of overparameterized models by removing irrelevant parameters, making them easier to interpret.
Another fact to answer this myth is the emergence of hybrid architectures that offer robust performance without the issues of complexity. These models aim to capture the best of both worlds, promising efficiency and interpretability.
While these myths are linked to the problems and challenges associated with overparameterization, there is also a myth from the other end of the spectrum where it is believed to be the ultimate solution.
6. Overparameterized Models are Universally Superior
The myth states that models with a large number of parameters are better in all situations. It suggests that larger models are better at everything compared to smaller models.
Debunked!
However, the truth is that smaller, specialized models can outperform large, generic ones in domain-specific tasks, especially when computational resources are limited. The optimal model size depends on the task, the data, and the operational constraints. Hence, larger models are not a solution every time.

Now that we have reviewed these myths associated with overparameterization in LLMs, let’s explore the science behind this concept.
The Science Behind Overparameterization
Overparameterization in LLMs is a fascinating area of study that is more than just using an ‘excess’ of parameters. It is an approach that changes the way these models learn, generalize, and generate outputs. Let’s take a closer look at the science behind it.
We will begin with some key connections within the concept of overparameterization. These include:
The Double-Descent Curve
It is a generalization paradox that shows that after a certain point, the addition of new parameters improves a model’s ability to generalize. Hence, it creates a U-shaped curve for an LLM’s performance which indicates that increasing the model size can actually enhance its performance.
The U-shaped double descent curve is broken down into three main parts as follows:
- Initial Descent
As model complexity increases, the model’s ability to fit the training data improves, leading to a decrease in generalization error. This is the traditional bias-variance tradeoff region.
- Peak (Interpolation Threshold)
At a certain point, known as the interpolation threshold, the model becomes complex enough to perfectly fit the training data, including noise. This leads to an increase in generalization error, as the model starts to overfit.
- Second Descent
Surprisingly, as the model complexity continues to increase beyond this threshold, the generalization error starts to decrease again. This is because the model, now overparameterized, can find solutions that generalize well despite having more parameters than necessary.
Hence, the curve demonstrates that LLMs can leverage a vast parameter space to find robust solutions. It highlights the counterintuitive nature of overparameterization in LLMs, emphasizing that more parameters can lead to improved LLMs with the right training techniques.
Implicit Regularization
This is a concept that refers to a gradient descent which plays a crucial role as an organizer in overparameterized models. It guides models towards solutions that generalize well even without explicit regularization techniques, and learning patterns to balance complexity and simplicity.
Implicit regularization occurs when the training process itself influences the model to prefer simpler or more generalizable solutions. This happens without adding explicit penalties or constraints to the loss function. It helps in:
- Navigating Vast Parameter Spaces
Overparameterized models have more parameters than necessary to fit the training data. Implicit regularization helps these models navigate their vast parameter spaces to find solutions that generalize well, rather than overfitting to the training data.
- Avoiding Overfitting
Despite having the capacity to memorize the training data, overparameterized LLMs often generalize well to new data. This is partly due to implicit regularization, which guides the model towards solutions that capture the underlying patterns in the data rather than noise.
- Enhancing Generalization
In LLMs, implicit regularization helps achieve the second descent in the double descent curve. It allows these models to generalize effectively even when they have more parameters than data points, defying traditional expectations of overfitting.
Hence, it is a key factor for overparameterized LLMs to perform well despite their complexity to generate robust responses.
Powered by these connections, the overparameterization in LLMs enhances the optimization and representation learning of the language models. The optimization occurs in two ways:
- Smoother loss landscapes: it allows gradient descent to converge more efficiently
- Better convergence: escapes local minima to find a global minima for higher accuracy
As for the aspect of representation learning, it results in:
- Capturing complex patterns: detects subtleties like tone and context to learn relationships in data
- Flexible learning: enables LLMs to handle unseen scenarios through richer representations of language
While the science behind overparameterization in LLMs explains the impact of this concept, we still need to understand the guiding principle behind it. Let’s look deeper into the role of scaling laws and how they define overparameterization in LLMs.
Challenges and Trade-Offs of Overparameterization
The benefits of improved generalization and capturing complex patterns are not without challenges that need careful consideration. Below is a detailed look at these aspects:
Computational Costs
One of the primary challenges of overparameterization is the substantial computational resources required for both training and inference. The training complexity necessitates powerful hardware, leading to increased energy consumption and longer training times.
It not only makes the process costly and less environmentally friendly but also makes these models resource-intensive for inference. This is particularly challenging for applications requiring real-time responses, as the computational overhead can lead to latency issues.
Data Requirements
To leverage the benefits of overparameterization without falling into the trap of overfitting, large and high-quality datasets are essential. Insufficient data can lead to overfitting, where the model memorizes the training data rather than learning to generalize from it.
The quality of the data is equally important. Noisy or biased datasets can mislead the model, resulting in poor performance on unseen data. Hence, ensuring data diversity and representativeness is crucial to mitigate these risks.
Overfitting Concerns
While overparameterization can enhance a model’s ability to generalize, it also increases the risk of overfitting if not managed properly. This requires the maintenance of a delicate balance between model complexity and data availability.
If the model scales faster than the data, it may overfit, capturing noise instead of meaningful patterns. This can lead to poor performance on new, unseen data. To combat overfitting, various regularization techniques, both explicit and implicit, are used. However, finding the right balance and combination of these techniques requires extensive experimentation.
Deployment Challenges
The large size and computational demands of overparameterized models make them difficult to deploy on devices with limited resources, such as smartphones or IoT devices. This limits their applicability in scenarios where lightweight models are preferred.
Moreover, inference speed is critical in real-time applications. Overparameterized models can introduce latency, making them unsuitable for time-sensitive tasks. Optimizing these models for faster inference without sacrificing accuracy is a complex challenge.

Addressing these challenges requires careful consideration of computational resources, data management, overfitting prevention, and deployment strategies to fully harness the potential of the advanced models.
Applications Leveraging Overparameterization
Multi-Modal Language Models
With the advancing technological development and its increased use, data has taken different variations. Overparameterization empowers LLMs to interact with all the different types of data like textual and visual information.
Llama 3.2 and GPT-V are leading examples of these multi-model LLMs that interpret and create both images and texts. Moreover, these models are equipped for cross-modal retrieval where users can search for images using textual queries and vice versa. Hence, enhancing the search and retrieval capabilities of language models.
Learn the difference between PaLM 2 vs. Llama 2
Long-Context Applications
The increased parameterization enables LLMs to handle complex information and understand patterns within large amounts of data. It has enabled language models to be useful in long-context applications where the input is large in size.
This has made LLMs useful tools for document summarization. For instance, these models can summarize lengthy legal or financial reports to extract key insights, or research papers to provide a quick overview of its content.
Another long-context application for overparameterized LLMs is the model’s ability for extended reasoning. Hence, in fields like mathematics, LLMs can assist in complex problem-solving and can analyze extensive datasets to provide strategic insights for action.
Read about the top 10 industries that can benefit from LLMs
Few-Shot and Zero-Shot Learning Capabilities
Overparameterized LLMs also excel in few-shot and zero-shot learning, enabling them to perform tasks with minimal training data. In language translation, they can effectively handle low-resource languages, enhancing linguistic diversity and accessibility.
This capability also becomes useful for businesses adapting to AI solutions. For instance, they can deploy customizable chatbots that efficiently respond to niche queries, improving customer service.
Moreover, LLMs can be adapted to industry-specific applications, such as healthcare and finance, without the need for extensive retraining. The creative domains can also utilize these overparameterized LLMs to generate art and music with ease without explicit training, driving innovation and creativity.
These examples highlight how over-parametrized LLMs are transforming various sectors by leveraging their advanced capabilities.
Future Directions and Open Questions
As the field of LLMs evolves, understanding the theoretical limits of over-parametrization remains a key research focus. It is important to understand how much overparameterization is necessary for optimal performance. It will ensure the development of efficient and sustainable models.
This can result in theoretical insights into overparameterization, which could lead to breakthroughs in how we design and deploy LLMs, ensuring they are both effective and resource-conscious.
Moreover, innovations aimed at balancing overparameterization with efficiency are crucial as we look toward the future of LLMs, particularly in the context of next-generation models and advancements like multimodal AI. As we continue to push the boundaries of what LLMs can achieve, addressing these open questions will be vital in shaping the future landscape of AI.
Are you interested in learning more about large language models and how to develop high-performing applications using the models? Join our LLM boot camp today for a hands-on learning experience!
