

Generative AI research is rapidly transforming the landscape of artificial intelligence, driving innovation in large language models, AI agents, and multimodal systems. Staying current with the latest breakthroughs is essential for data scientists, AI engineers, and researchers who want to leverage the full potential of generative AI. In this comprehensive roundup, we highlight this week’s top 4 research papers in generative AI research, each representing a significant leap in technical sophistication, practical impact, and our understanding of what’s possible with modern AI systems.
The Pulse of Generative AI Research
Generative AI research is at the heart of the artificial intelligence revolution, fueling advances in large language models (LLMs), AI agents, multimodal AI, and domain-specific foundation models. This week’s top research papers in generative AI research exemplify the technical rigor, creativity, and ambition that define the field today. Whether you’re interested in machine learning automation, memory-augmented models, or medical AI, these papers offer deep insights and actionable takeaways for anyone invested in the future of generative AI.
For more on the latest in generative AI research, visit the Data Science Dojo blog.

AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Source: AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Overview
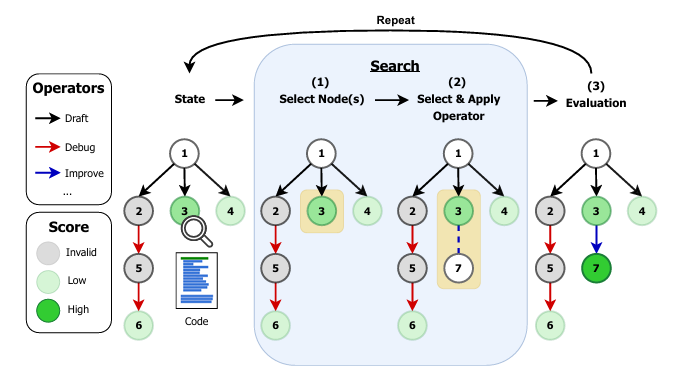
This paper introduces a systematic framework for designing, evaluating, and benchmarking AI research agents—autonomous systems that automate the design, implementation, and optimization of machine learning models. The focus is on the MLE-bench, a challenging benchmark where agents compete in Kaggle-style competitions to solve real-world ML problems. By formalizing research agents as search policies navigating a space of candidate solutions, the study disentangles the impact of search strategies (Greedy, MCTS, Evolutionary) and operator sets (DRAFT, DEBUG, IMPROVE, MEMORY, CROSSOVER) on agent performance.
Key Insights
-
Operator Design is Critical:
Study finds that the choice and design of operators (the actions agents can take to modify solutions) are more influential than the search policy itself. Operators such as DRAFT, DEBUG, IMPROVE, MEMORY, and CROSSOVER allow agents to iteratively refine solutions, debug code, and recombine successful strategies.
-
State-of-the-Art Results:
The best combination of search strategy and operator set achieves a Kaggle medal success rate of 47.7% on MLE-bench lite, up from 39.6%. This is a significant improvement in benchmark evaluation for machine learning automation.
-
Generalization Gap:
The paper highlights the risk of overfitting to validation metrics and the importance of robust evaluation protocols for scalable scientific discovery. The generalization gap between validation and test scores can mislead the search process, emphasizing the need for regularization and robust final-node selection strategies.
-
AIRA-dojo Framework:
Introduction of AIRA-dojo, a scalable environment for benchmarking and developing AI research agents, supporting reproducible experiments and custom operator design. The framework allows for controlled experiments at scale, enabling systematic exploration of agentic policies and operator sets.
Main Takeaways
- AI agents can automate and accelerate the scientific discovery process in machine learning, but their effectiveness hinges on the interplay between search strategies and operator design.
- The research underscores the need for rigorous evaluation and regularization to ensure robust, generalizable results in generative AI research.
- The AIRA-dojo framework is a valuable resource for the community, enabling systematic exploration of agentic policies and operator sets.
Why It’s Revolutionary
This work advances generative AI research by providing a principled methodology for building and evaluating AI agents that can autonomously explore, implement, and optimize machine learning solutions. It sets a new standard for transparency and reproducibility in agent-based generative AI systems, and the introduction of AIRA-dojo as a benchmarking environment accelerates progress by enabling the community to systematically test and improve AI agents.
GenSI MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Source: GenSI MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Overview
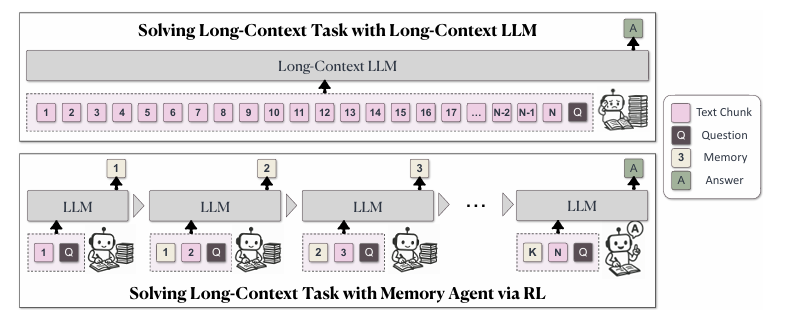
This paper addresses one of the most pressing challenges in generative AI research: enabling large language models (LLMs) to process and reason over extremely long contexts efficiently. The authors introduce MEMAGENT, a novel agent workflow that reads text in segments and updates a fixed-length memory using an overwrite strategy, trained end-to-end with reinforcement learning (RL).
Key Insights
-
Linear Complexity for Long Contexts:
MEMAGENT achieves nearly lossless performance extrapolation from 8K to 3.5M tokens, maintaining <5% performance loss and 95%+ accuracy on the 512K RULER test. This is a major breakthrough for long-context LLMs and memory-augmented models.
-
Human-Inspired Memory:
The agent mimics human note-taking by selectively retaining critical information and discarding irrelevant details, enabling efficient long-context reasoning. The memory is a sequence of ordinary tokens inside the context window, allowing the model to flexibly handle arbitrary text lengths while maintaining a linear time complexity during processing.
-
Multi-Conversation RL Training:
The paper extends the DAPO algorithm for multi-conversation RL, optimizing memory updates based on verifiable outcome rewards. This enables the model to learn what information to retain and what to discard dynamically.
-
Empirical Superiority:
MEMAGENT outperforms state-of-the-art long-context LLMs in both in-domain and out-of-domain tasks, including QA, variable tracking, and information extraction. The architecture is compatible with existing transformer-based LLMs, making it a practical solution for real-world applications.
Main Takeaways
- Memory-augmented models with RL-trained memory can scale to process arbitrarily long documents with linear computational cost, a major leap for generative AI research.
- The approach generalizes across diverse tasks, demonstrating robust zero-shot learning and strong out-of-distribution performance.
- MEMAGENT’s architecture is compatible with existing transformer-based LLMs, making it a practical solution for real-world applications.
W hy It’s Revolutionary
By solving the long-context bottleneck in generative AI, MEMAGENT paves the way for LLMs that can handle entire books, complex reasoning chains, and lifelong learning scenarios—key requirements for next-generation AI agents and foundation models. The integration of reinforcement learning for memory management is particularly innovative, enabling models to learn what information to retain and what to discard dynamically.
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
Source: Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
Overview
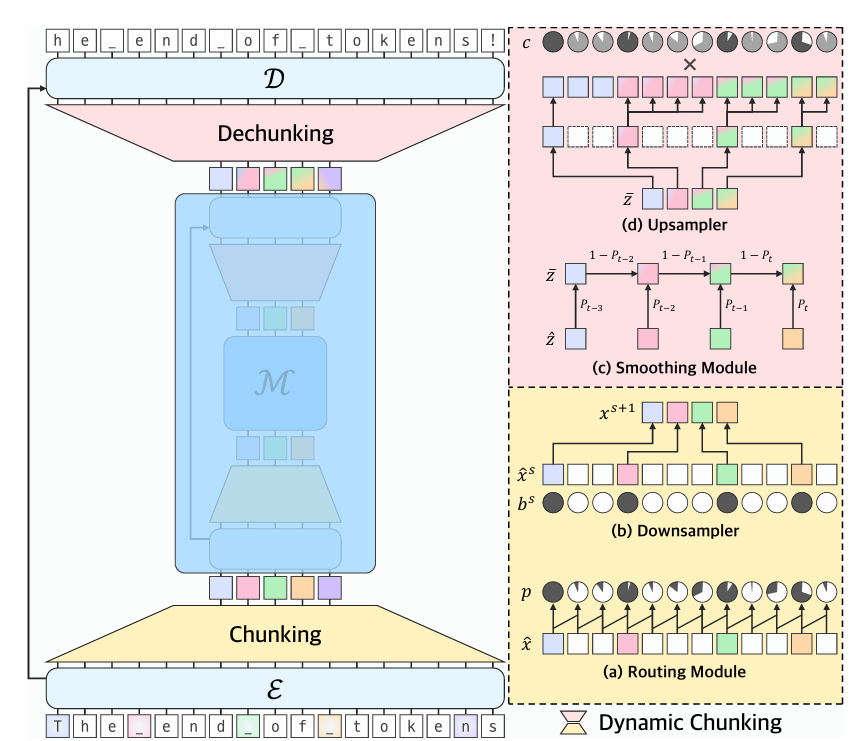
This paper addresses a fundamental limitation in current generative AI research: the reliance on tokenization as a preprocessing step for language models. The authors propose H-Net, a dynamic chunking mechanism that learns content- and context-dependent segmentation strategies end-to-end, replacing the traditional tokenization-LM-detokenization pipeline with a single hierarchical model.
Key Insights
-
Tokenization-Free Modeling:
H-Net learns to segment raw data into meaningful chunks, outperforming strong BPE-tokenized Transformers at equivalent compute budgets.
-
Hierarchical Abstraction:
Iterating the hierarchy to multiple stages enables the model to capture multiple levels of abstraction, improving scaling with data and matching the performance of much larger token-based models.
-
Robustness and Interpretability:
H-Nets show increased robustness to character-level noise and learn semantically coherent boundaries without explicit supervision.
-
Cross-Language and Modality Gains:
The benefits are even greater for languages and modalities with weak tokenization heuristics (e.g., Chinese, code, DNA), achieving up to 4x improvement in data efficiency.
Main Takeaways
- Dynamic chunking enables true end-to-end generative AI models that learn from unprocessed data, eliminating the biases and limitations of fixed-vocabulary tokenization.
- H-Net’s architecture is modular and scalable, supporting hybrid and multi-stage designs for diverse data types.
- The approach enhances both the efficiency and generalization of foundation models, making it a cornerstone for future generative AI research.
Why It’s Revolutionary
H-Net represents a paradigm shift in generative AI research, moving beyond handcrafted preprocessing to fully learnable, hierarchical sequence modeling. This unlocks new possibilities for multilingual, multimodal, and domain-agnostic AI systems.
MedGemma: Medical Vision-Language Foundation Models
Source: MedGemma Technical Report
Overview
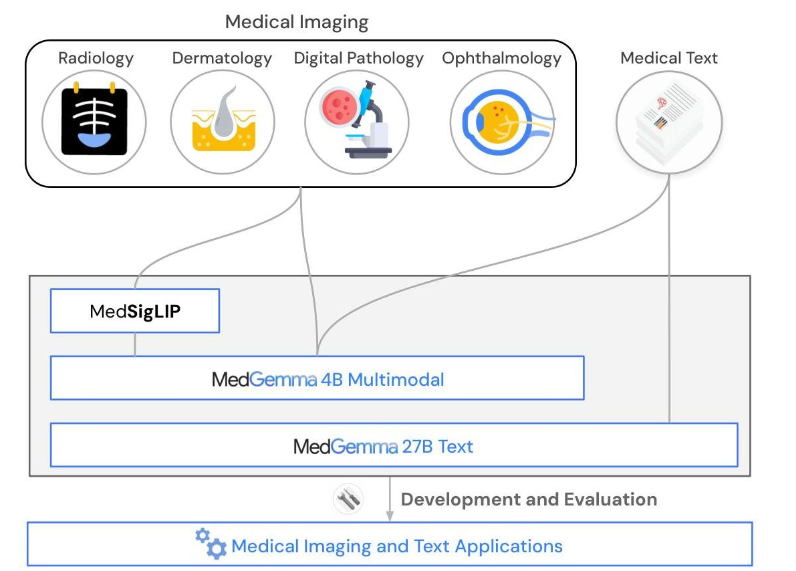
MedGemma introduces a suite of medical vision-language foundation models based on the Gemma 3 architecture, optimized for advanced medical understanding and reasoning across images and text. The collection includes multimodal and text-only variants, as well as MedSigLIP, a specialized vision encoder.
Key Insights
-
Domain-Specific Foundation Models:
MedGemma models outperform similar-sized generative models and approach the performance of task-specific models on medical benchmarks. The 4B variant accepts both text and images, excelling at vision question answering, chest X-ray classification, and histopathology analysis.
-
Fine-Tuning and Adaptability:
MedGemma can be fine-tuned for subdomains, achieving state-of-the-art results in electronic health record retrieval, pneumothorax classification, and histopathology patch classification.
-
Zero-Shot and Data-Efficient Learning:
MedSigLIP enables strong zero-shot and linear probe performance across multiple medical imaging domains.
-
Benchmark Evaluation:
MedGemma demonstrates superior performance on medical multimodal question answering, chest X-ray finding classification, and agentic evaluations compared to the base models.
Main Takeaways
- MedGemma demonstrates that specialized foundation models can deliver robust, efficient, and generalizable performance in medical AI, a critical area for real-world impact.
- The models are openly released, supporting transparency, reproducibility, and community-driven innovation in generative AI research.
- MedGemma’s architecture and training methodology set a new benchmark for multimodal AI in healthcare.
Why It’s Revolutionary
By bridging the gap between general-purpose and domain-specific generative AI, MedGemma accelerates the development of trustworthy, high-performance medical AI systems—showcasing the power of foundation models in specialized domains. The model’s ability to integrate multimodal data, support zero-shot and fine-tuned applications, and deliver state-of-the-art performance in specialized tasks demonstrates the versatility and impact of generative AI research.
Conclusion: The Road Ahead for Generative AI Research
Generative AI research is evolving at an extraordinary pace, with breakthroughs in large language models, multimodal AI, and foundation models redefining the boundaries of artificial intelligence. The four papers highlighted this week exemplify the field’s rapid progress toward more autonomous, scalable, and domain-adaptable AI systems.
From agentic search and memory-augmented models to medical foundation models, these advances are not just academic—they are shaping the future of AI in industry, healthcare, science, and beyond. As researchers continue to innovate, we can expect even more breakthroughs in generative AI research, driving the next wave of intelligent, adaptable, and impactful AI solutions.
For more insights and technical deep dives, explore the Data Science Dojo blog.
Frequently Asked Questions
Q1: What is the significance of memory-augmented models in generative AI research?
Memory-augmented models like MEMAGENT enable LLMs to process arbitrarily long contexts with linear computational cost, supporting complex reasoning and lifelong learning scenarios.
Q2: How do AI agents accelerate machine learning automation?
AI agents automate the design, implementation, and optimization of machine learning models, accelerating scientific discovery and enabling scalable, reproducible research.
Q3: Why are domain-specific foundation models important?
Domain-specific foundation models like MedGemma deliver superior performance in specialized tasks (e.g., medical AI) while retaining general capabilities, supporting both zero-shot and fine-tuned applications.
Q4: Where can I read more about generative AI research?
Visit the Data Science Dojo blog for the latest in generative AI research, technical deep dives, and expert analysis.