

To build one anywhere and run anywhere – Learn reproducible and shareable data science with Docker Containers.
Docker Container is stand-alone software that contains both application code and its dependencies, which can run on any platform smoothly. Docker uses Linux namespaces and Cgroups to isolate different containers. The motto of Docker is to build once anywhere and run anywhere.
You can use Docker to create an image, run it as a container, and ship it anywhere. You can use a container registry service like Dockerhub for storing application images, and it integrates with Bitbucket and Github, where you can host Dockerfile.
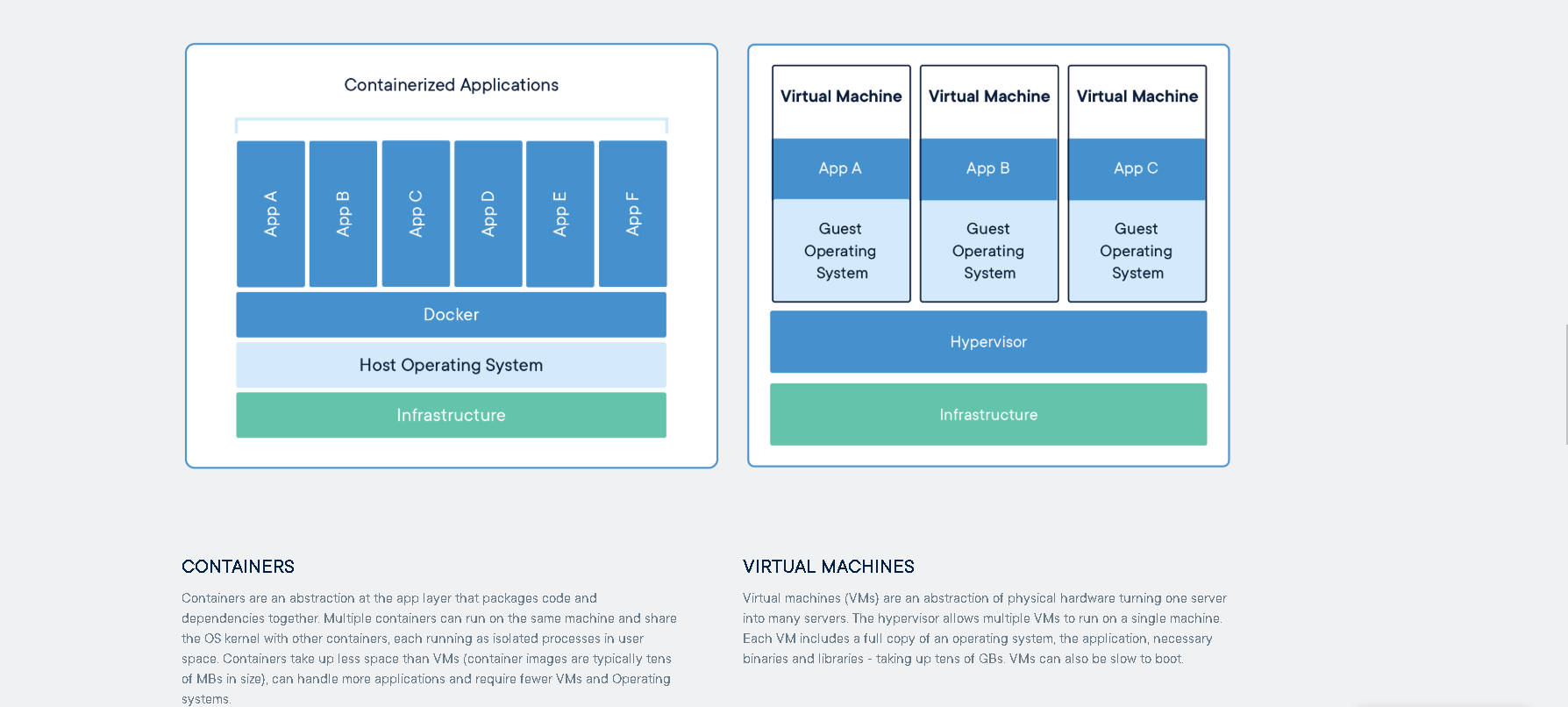
Docker containers are Linux containers, and all of them running in the same host share the same Linux kernel, but the ecosystem is vibrant enough to provide you with all the tools to run in any other popular operating system. Unlike virtual machines, you do not need to have multiple operating systems residing in the same computer for running several applications.
The only precondition for running docker containers is to have Docker Engine up and running. An application developer or a data professional might have to do a little extra work for packaging the application…but it’s worth the effort! You can share it with anyone easily since all the dependencies are packaged alongside the application code. Furthermore, it can be effortlessly transferred from a personal laptop to a data center, or from a data center to a public cloud with lesser time and low bandwidth cost.
Adopting Docker provides numerous benefits to any data science project:
- Easier setup: Docker makes computing environment setup seamless. The only thing you have to do is pull any public image from the container registry and run your local machine.
- Shareable environment: You can share the computing environment with others on the container registry – anyone with Docker installed can effortlessly have an identical coding environment as yours.
- Isolated environment: Since you can set up a separate computing environment for each project, you will never have to deal with version conflicts of different packages with docker.
- Portable applications: Docker makes applications portable so that you can effortlessly run the same application without modification in a local machine, on-premise, or cloud.
- Lower resource consumption: Since all containers share the same OS kernel, they consume less compute and storage resources than virtual machines.
- Inexpensive option: Docker is less expensive than the cloud as you do not have to deploy it on the cloud and share the URL for experimentation purposes or feedback. This reduces unnecessary costs and cloud billing.
- Productive data science: With Docker, data professionals do not have to spend too much time setting up the configuration. This makes data scientists more productive and efficient.
- Additional docker tooling: Newer services dealing with the orchestration of containers in single and multiple nodes are becoming increasingly popular. Kubernetes and Docker Swarm were developed for orchestrating containers for taking advantage of the
data center and cloud. You can use Docker Compose to run multiple containers in the same node. - Micro–service architecture: Docker is well-suited for micro-service architecture which is a kind of design where you run several applications and each of them performs one task. The great thing about this is that each service can scale independently
based on its demand. - Continuous testing: Docker helps with the automatic testing of data science code. Since you can easily simulate the computing environment in the CI server, no manual intervention is required, and you can merge the pull request if all tests are passed.
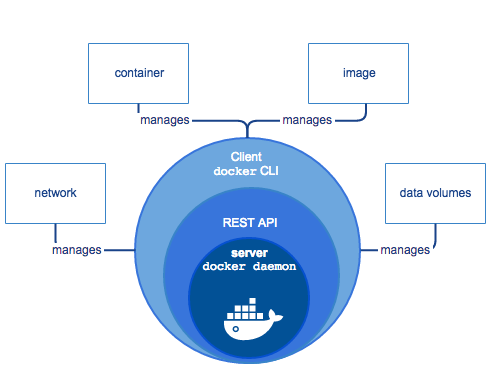
Docker tool contains several components:
- Docker Daemon: It is a long-running process, which works in the background and responds to any request through the REST API.
- Docker Engine API: It provides an interface for the other HTTP clients to interact with the Docker daemon. There are several ways of using the Docker API: CLI, Python SDK, and HTTP API.
- Docker CLI: It is a command-line interface for users to interact with the docker daemon, and each command starts with the word “docker’’.
If you want your data science project to be worth considering, you have to make it reproducible and shareable. Anyone can accomplish these goals by sharing data science code, datasets, and computing environments. The code and datasets can be easily shared on GitHub, Bitbucket, or Gitlab. However, it can be tricky to share the computing environment as it has to work on any platform.
How can you make sure your project works smoothly on any platform? We cannot ask others to have a separate virtual machine with all the packages installed. It consumes excessive memory when running and still occupies storage at the stop state – it becomes impractical to run many of them on the same computer. Furthermore, it takes a lot of network bandwidth and time to transfer, and most cloud providers do not allow you to download the image to your local computer.
Our next option is to request people to install all the packages needed into their operating system, but this installation might break their other projects. You can create a virtual environment in python, but what about non-python packages? What is the solution? Docker might be the answer you are looking for, setting up shareable and reproducible data science projects.
Creating docker containers
We are going to create a container from the Jupyter Notebook image, and several steps need to be followed to run it on our local computer.
- Install Docker:
- Docker for Ubuntu: https://docs.docker.com/install/linux/docker-ce/ubuntu/
- Docker for Windows: https://docs.docker.com/docker-for-windows/install/
- Docker for Mac: https://docs.docker.com/docker-for-mac/install/
2. Make sure your Docker is running.
docker info
3. Download the sample Docker file.
4. Build the Docker image locally:
docker image build Dockerfile # Provide path and build locally
5. Pull an image from Docker Hub: If you do not have an image on your local computer, you can download any public image from the Docker registry.
docker pull jupyter/datascience-notebook # Pulling public image from Dockerhub
6. Run the container: After you have a notebook image in your local machine, run the command posted below.
docker images -all #this lists all the imagesdocker run -p 8888:8888 <image-name>
#use the notebook image
7. Access the notebook: Now you can access the notebook on your local machine by using the URL provided by the output of the previous command.
8. Shut down the docker container: You can stop the docker container so that it does not consume more memory. If you are confident about not using the image anymore, you can also delete the resource.
Stopping a Docker container:
docker stop <Container-name>
Remove a Docker container:
docker rm <Container-name>
Removing the image:
docker images -all # this lists all the images
docker rmi <image-container-id> # this removes the image
Summary
Data enthusiasts can leverage a tool like Docker to share their computing environment with other people easily. Technology like this can help anyone working on data science projects to be highly productive and focus more on core data analytic tasks to gain meaningful insights.
If you are a data enthusiast, visit https://datasciencedojo.com/