In today’s data-driven era, organizations expect more than static dashboards or descriptive analytics. They demand forecasts, predictive insights, and intelligent decision-making support. Traditionally, delivering this requires piecing together multiple tools, data lakes for storage, notebooks for model training, separate platforms for deployment, and BI tools for visualization.
Microsoft Fabric reimagines this workflow. It brings every stage of the machine learning lifecycle, from data ingestion and preparation to model training, deployment, and visualization, into a single, governed environment. In this blog, we’ll explore how Microsoft Fabric empowers data scientists to streamline the end-to-end ML process and unlock predictive intelligence at scale.
Why Choose Microsoft Fabric for Modern Data Science Workflows?
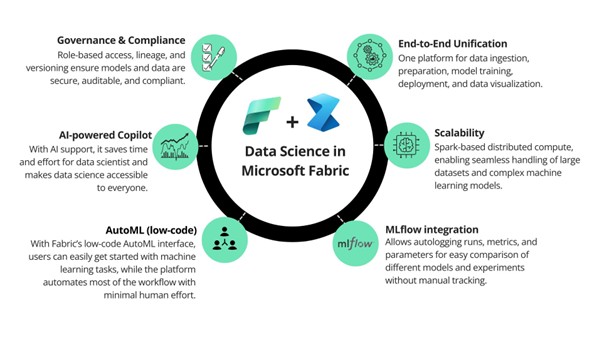
End-to-End Unification
One platform for data ingestion, preparation, model training, deployment, and data visualization. A wide range of activities are offered in Microsoft Fabric across the entire data science process, empowering users to build end-to-end data science workflows within a single platform.
Scalability
Spark-based distributed compute, enabling seamless handling of large datasets and complex machine learning models. With built-in support for Apache Spark in Microsoft Fabric, you can utilize the efficiency of Spark through Spark batch job definitions or with interactive Fabric notebooks.
MLflow integration
Allows autologging runs, metrics, and parameters for easy comparison of different models and experiments without requiring manual tracking.
AutoML (low-code)
With Fabric’s low-code AutoML interface, users can easily get started with machine learning tasks, while the platform automates most of the workflow with minimal manual effort.
AI-powered Copilot
With AI support in Microsoft Fabric, it saves time and effort for data scientist and makes data science accessible to everyone. It offers helpful suggestions, assists in writing and fixing code, and helps you analyse and visualize data.
Governance & Compliance
Features like role-based access, lineage tracking, and model versioning in Microsoft Fabric enable teams to reproduce models, trace issues efficiently, and maintain full transparency across the data science lifecycle.
Advanced Machine Learning Lifecycle in Microsoft Fabric
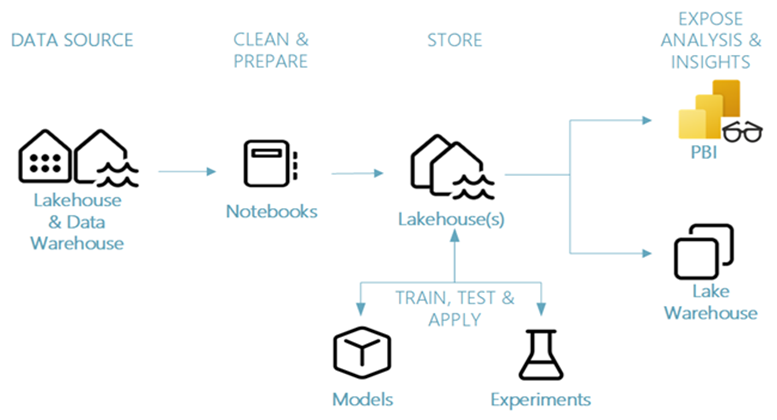
Microsoft Fabric offers capabilities to support every step of the machine learning lifecycle in one governed environment. Let’s explore how each step is supported by powerful features in Fabric:
source: learn.microsoft.com
1. Data Ingestion & Exploration
OneLake acts as the single source of truth, storing all data in Delta format with support for versioning, schema evolution, and ACID transactions. Fabric is standardized on Delta Lake which means all Fabric engines can interact with the same dataset stored in a Lakehouse. This eliminates the overhead of managing separate data lakes and warehouses.
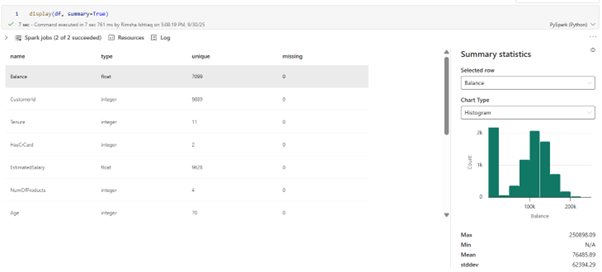
Fabric notebooks with Spark pools provide distributed compute for profiling, visualization, and correlations at scale.
Lakehouse: Fabric notebooks allow you to ingest data from various sources, such as Lakehouse, Data Warehouses or Semantic mode. You can simply store your data in Lakehouse that can be attached to the Notebook and then you can read or write to this Lakehouse using a local path in your Notebook.
Environments: You can create an environment and enable it for multiple notebooks. It ensures reproducibility by packaging runtimes, libraries, and dependencies.
Pandas on Spark lets data scientists apply familiar syntax while scaling workloads across Spark clusters to prepare data for training. You can perform data profiling and visualization efficiently on large amount of data.
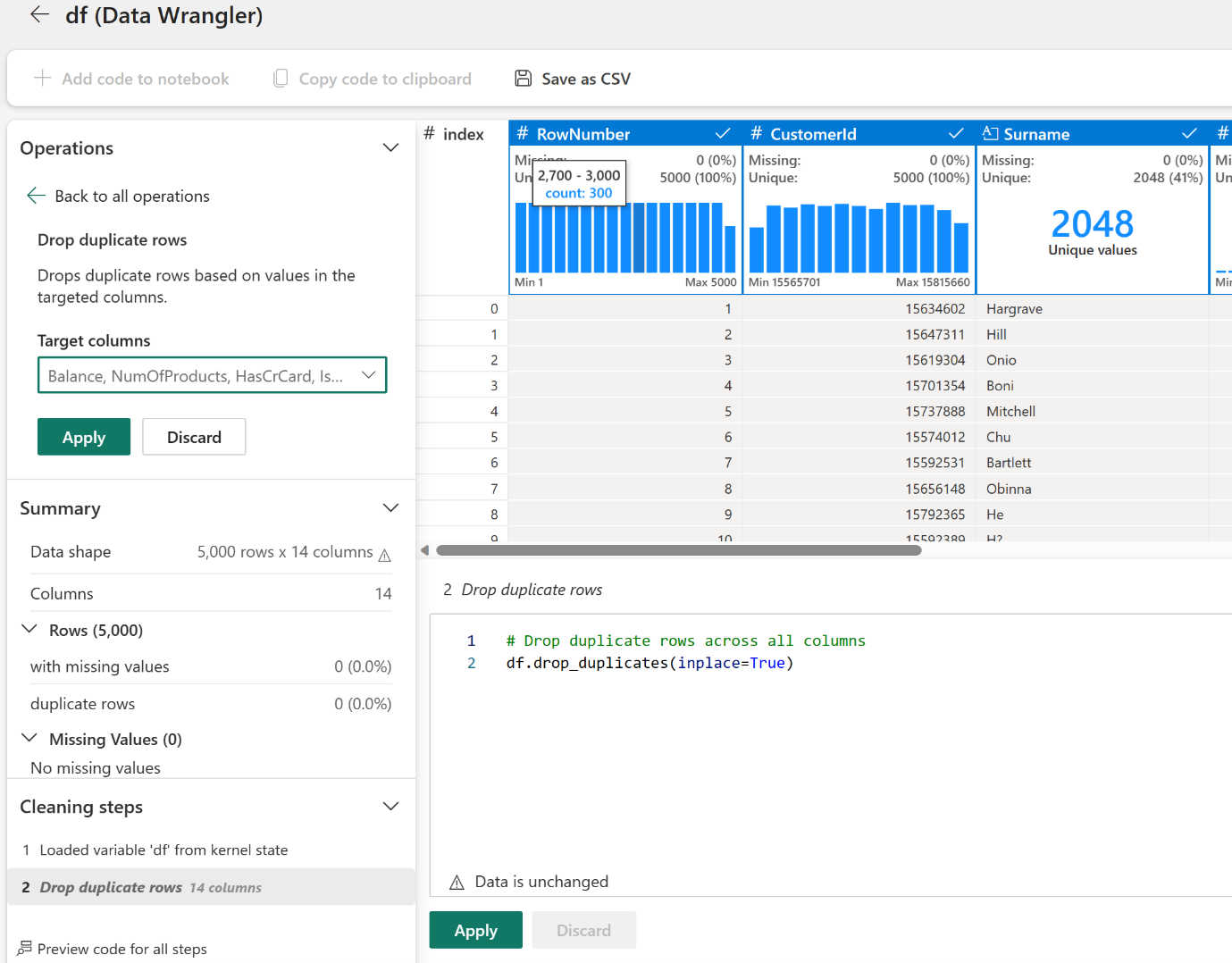
Data Wrangler offers an interactive interface to impute missing values, and with GenAI in Data Wrangler, reusable PySpark code is generated for auditability. It also gives you AI-powered suggestions to apply transformations.
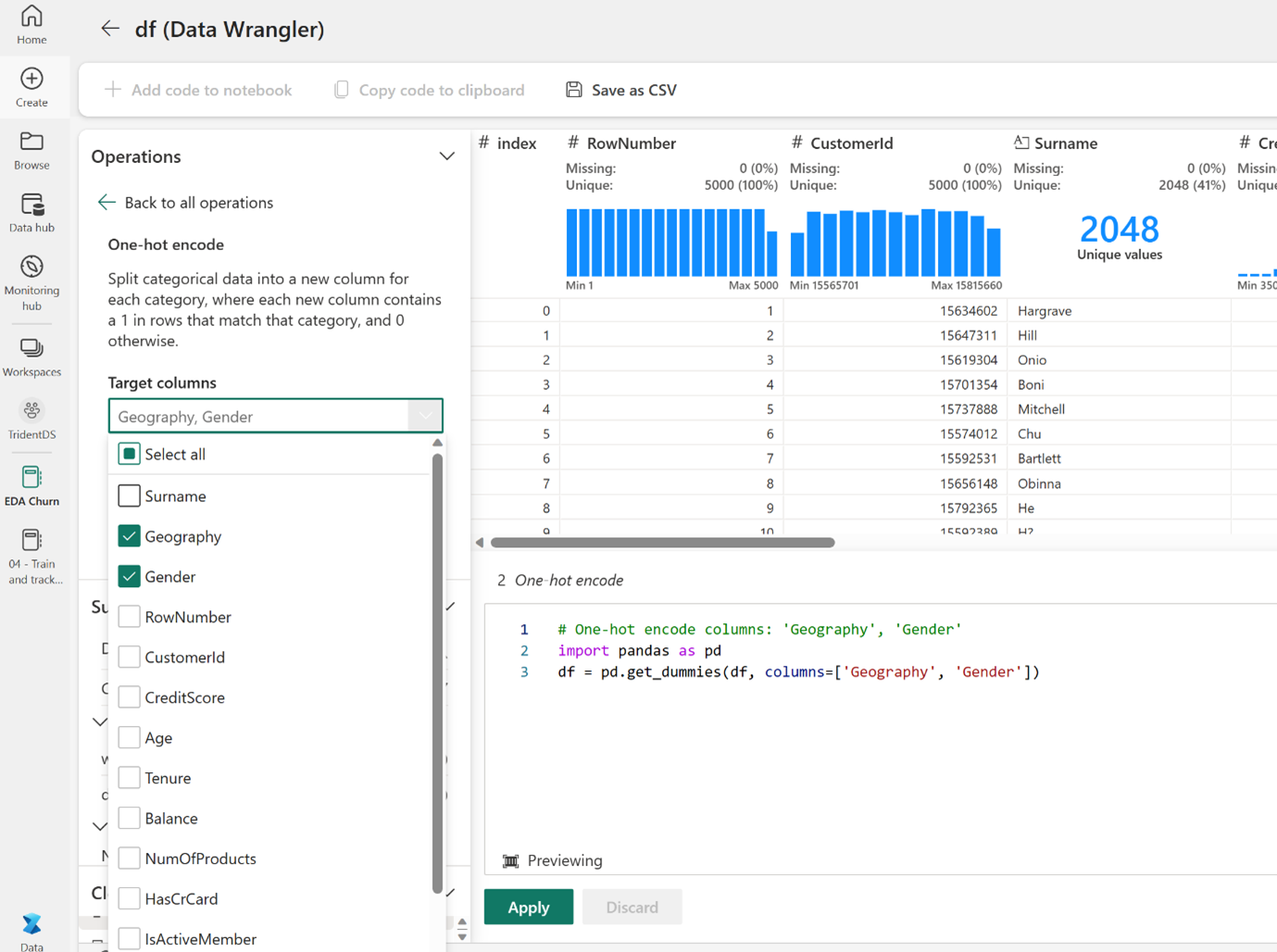
Feature Engineering can also be easily performed using Data Wrangler. It offers direct options to perform encoding and normalize features without requiring you to write any code.
Copilot integration accelerates preprocessing with AI-powered suggestions and code generation.
Processed features can be written back into OneLake as Delta tables, sharable across projects and teams.
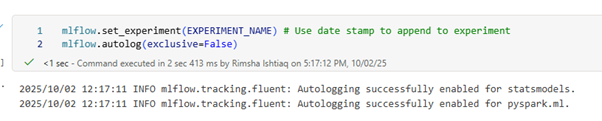
MLFlow Autologging can be enabled so that it automatically captures the values of input parameters and output metrics of a machine learning model as it is being trained. This information is then logged to your workspace, where it can be accessed and visualized using the MLflow APIs or the corresponding experiment in your workspace, reducing manual effort and ensuring consistency.
Frameworks: Choose Spark MLlib for distributed training, scikit-learn or XGBoost for tabular tasks, or PyTorch/TensorFlow for deep learning.
Hyperparameter tuning: The FLAML library supports lightweight, cost-efficient tuning strategies. SynapseML, a distributed machine learning library can also be used in Microsoft Fabric Notebooks to identify the best combination of hyperparameters
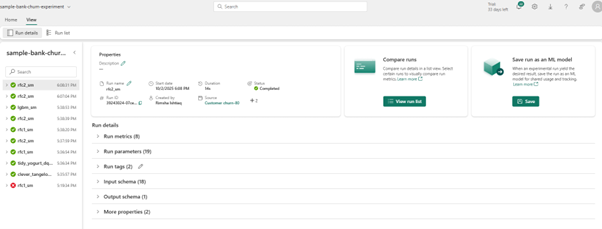
Experiments & Runs: Microsoft Fabric integrates MLflow for experiment tracking.
Within Experiment, there is a collection of runs for simplified tracking and comparison. Data scientists can compare those runs to select the model with best performing parameters. Runs can be visualized, searched, and compared, with full metadata available for export or further analysis.
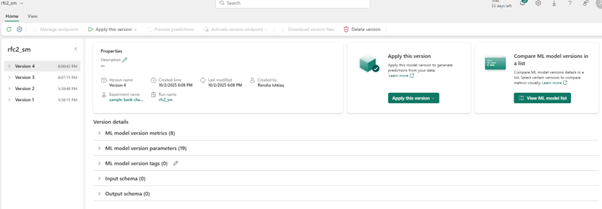
Model versioning; model run Iterations can be registered with tags and metadata, providing traceability and governance across versions.
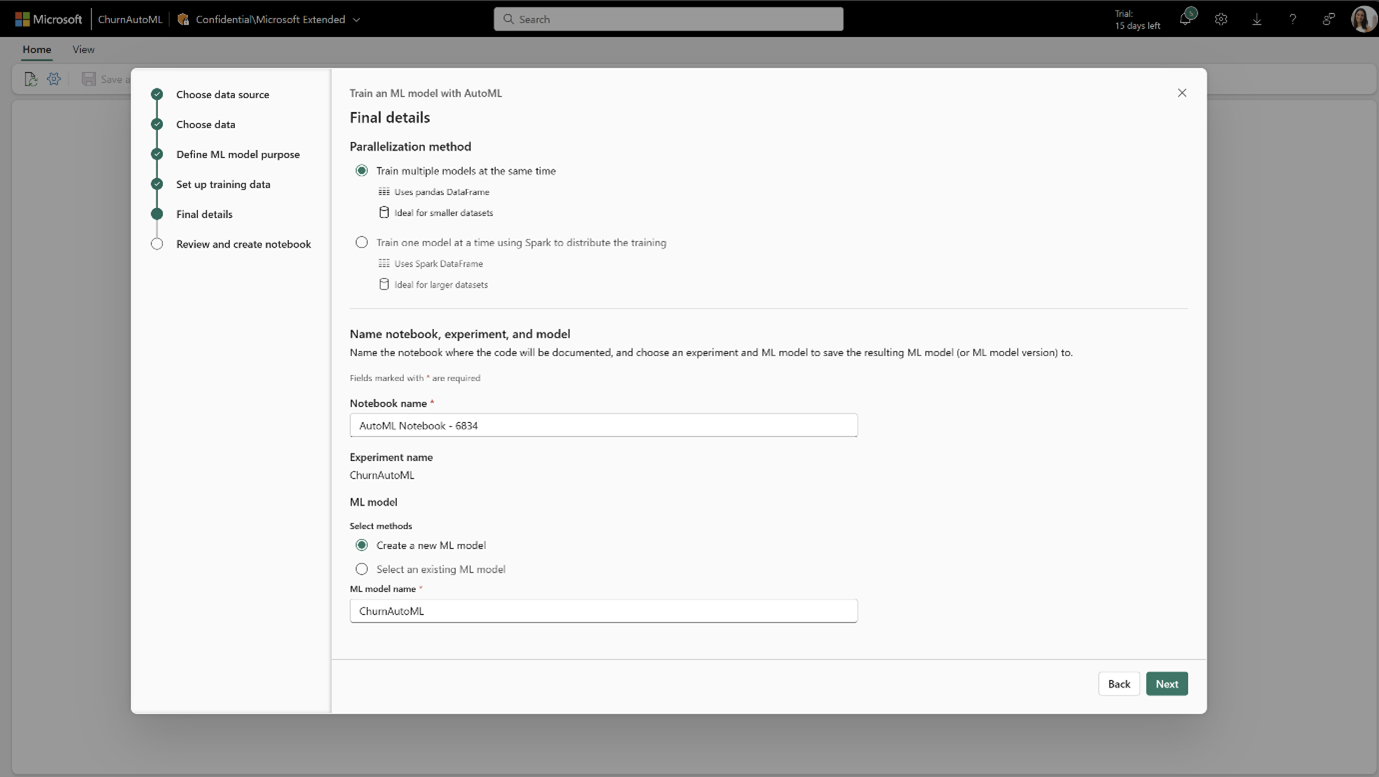
AutoML; a low-code interface generates preconfigured notebooks for tasks like classification, regression, or forecasting. It performs all the Machine Learning steps automatically from data transformation, model definition to training. These notebooks also leverage MLflow logging to capture parameters and metrics automatically. Therefore, completely automating the Machine Learning lifecycle.
4. Model Evaluation & Selection
Notebook visualizations such as ROC curves, confusion matrix, and regression error plots provide immediate insights.
Experiment dashboards make it simple to compare models’ side-by-side, highlighting the best-performing candidate.
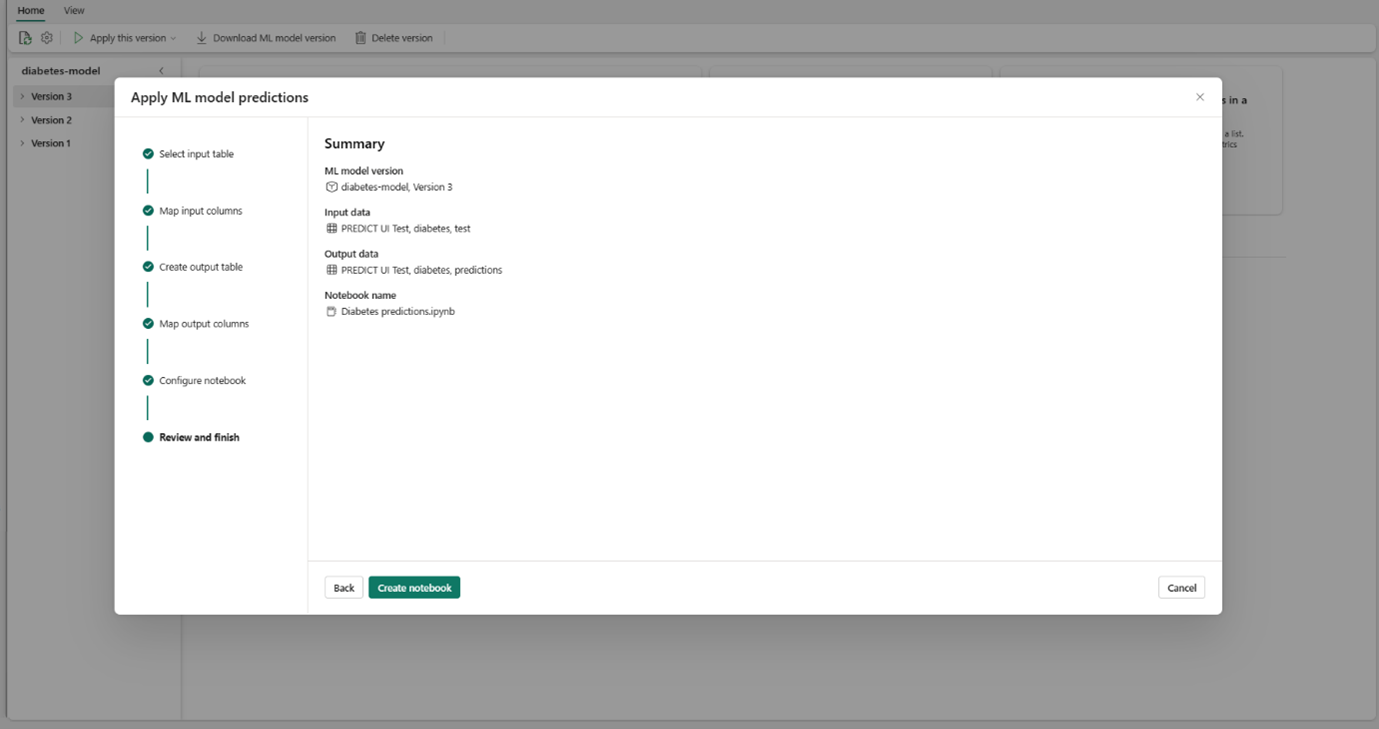
PREDICT function can be used during evaluation to generate test predictions at scale. You can use this function to generate batch predictions directly from a Microsoft Fabric notebook or from the item page of a given ML model.
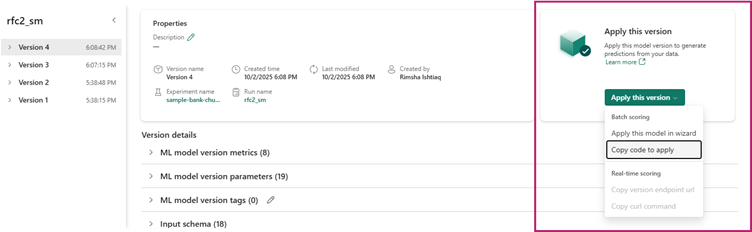
You can simply select the specific model version you need to score and copy generated code template into a notebook and customize the parameters yourself.
Another way is to use the GUI experience to generate PREDICTcode by selecting ‘apply this model to wizard’.
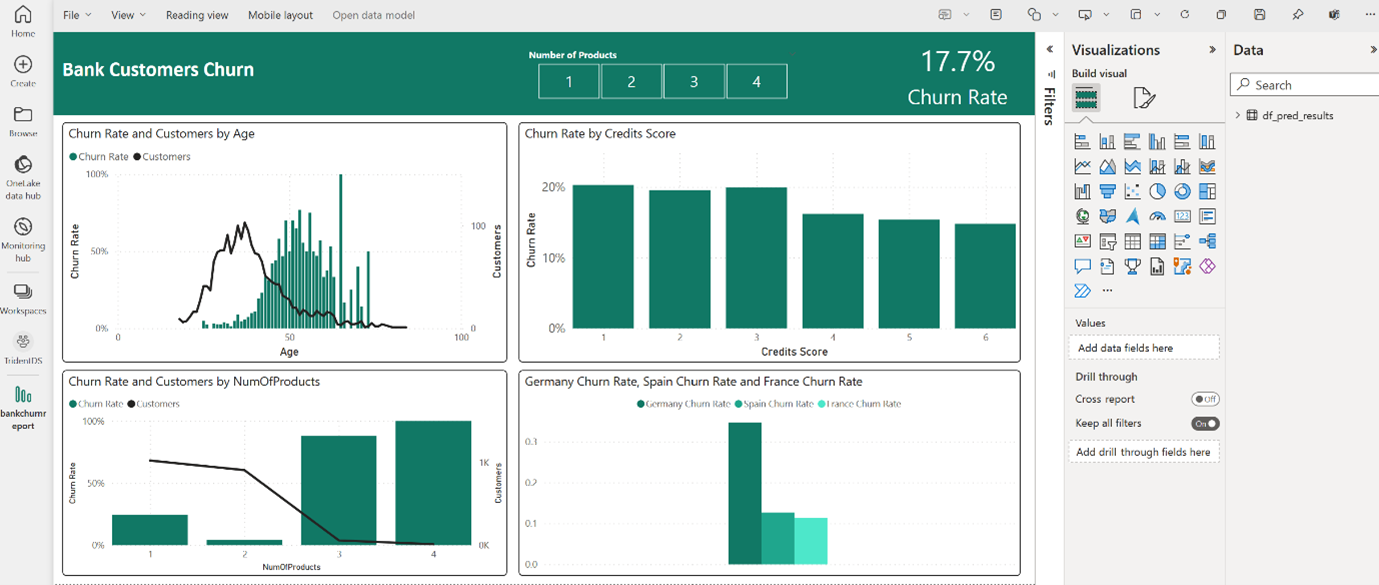
Power BI integration makes predictions stored in OneLake available to analysts with no extra data movement.
Direct Lake mode ensures low latency querying of large Delta tables, keeping dashboards fast and responsive even at enterprise scale.
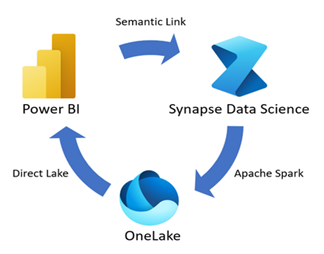
Semantic Link is a feature that allows you to establish a connection between semantic models and Synapse Data Science in Microsoft Fabric. Through the Semantic link (preview), data scientists can use PowerBI sematic models in Notebooks using the SemPy Python library or Spark (in Python, R, SQL, and Scala) to perform tasks such as in-depth statistical analysis and predictive modelling with machine learning. The output data can then be stored in the OneLake which can be used by PowerBI.
source: learn.microsoft.com
6. Monitoring & Control
Models are assets that require governance and continuous maintenance.
Automated retraining pipelines can be triggered on a schedule or in response to specific metric drop.
Versioning and lineage tracking make it clear which combination of data, code, and parameters produced any given model and the dependency of each ML item.
Machine learning experiments and models are integrated with the lifecycle management capabilities in Microsoft Fabric.
Microsoft Fabric deployment pipeline can track ML artifacts across development, test, and production workspaces while preserving experiment runs and model versions. Metadata, Lineage between notebooks, experiments, and models is maintained.
In Microsoft Fabric, ML experiments and models are also synced via Git Integration, but experiment runs, and model versions remain in workspace storage and aren’t versioned in Git. Git tracks only artifact metadata, not data. which includes display name, version, and dependencies. Lineage between notebooks, experiments, and models is preserved across Git-connected workspaces, ensuring traceability.
Access controls in Fabric provide fine-grained permissions for models, experiments, and workspaces, ensuring responsible collaboration. You can grant controlled access to teams to access the items and data that is useful only for their department context.
Beyond ML: Other Data Science Capabilities in Microsoft Fabric
Besides ML workflows, Fabric also empowers organizations to build AI-driven solutions:
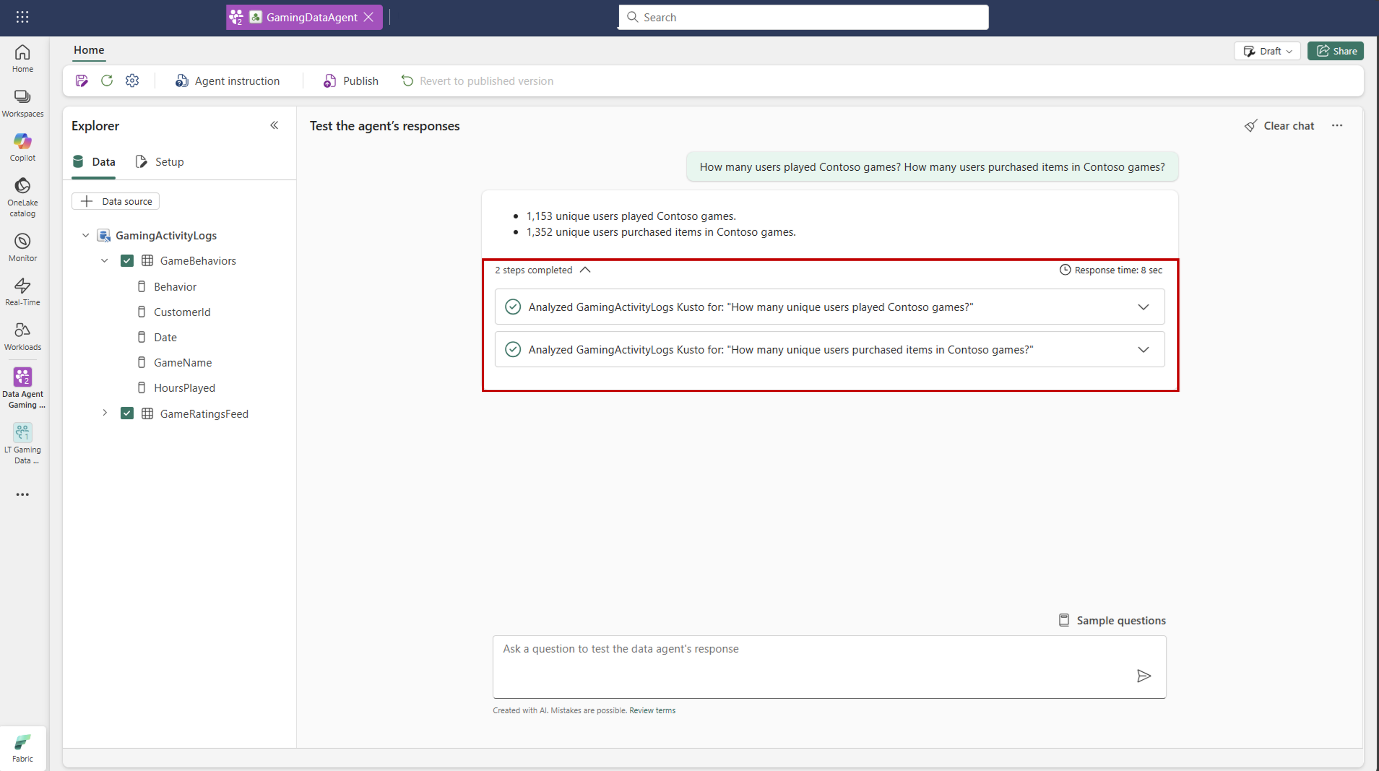
Data Agents: A newly introduced feature, Data Agents let you create conversational Q&A systems tailored to your organization’s data in OneLake. They are powered by Azure OpenAI Assistant APIs, and can access multiple sources such as Lakehouse, Warehouse, Power BI datasets, and KQL databases. You can customize them with specific instructions, and examples, so they align with organizational needs. The process is iterative: as you refine performance, you can publish the agent, generating a read-only version to share across teams.
source: learn.microsoft.com
LLM-powered Applications: Fabric integrates seamlessly with Azure OpenAIService and SynapseML, making it possible to run large-scale natural language workflows directly on Spark. Instead of handling prompts one by one, Fabric enables distributed processing of millions of prompts in parallel. This makes it practical to deploy LLMs for enterprise-scale use cases such as summarization, classification, and question answering.
Conclusion: Unlocking Predictive Intelligence with Fabric
Microsoft Fabric isn’t just another data platform, it’s a game-changer for data science teams. By eliminating silos between storage, experimentation, deployment, and visualization, Fabric empowers organizations to move faster from raw data to business impact. Whether you’re a data scientist building custom models or an analyst looking to leverage interactive, Fabric provides the tools to scale predictive insights across your enterprise.
The future of data science is unified, governed, and intelligent, and Microsoft Fabric is paving the way.