If you’ve been paying attention to where language models are heading, there’s a clear trend: context windows are getting bigger, not smaller. Agents talk to tools, tools talk back, agents talk to other agents, and suddenly a single task isn’t a neat 2k-token prompt anymore. It’s a long-running conversation with memory, state, code, and side effects. This is the world of agentic systems and deep agents, and it’s exactly where things start to break in subtle ways.
The promise sounds simple. If we just give models more context, they should perform better. More history, more instructions, more documents, more traces of what already happened. But in practice, something strange shows up as context grows. Performance doesn’t just plateau; it often degrades. Important details get ignored. Earlier decisions get contradicted. The model starts to feel fuzzy and inconsistent. This phenomenon is often called context rot, and it’s one of the most practical limitations we’re running into right now.
This blog is a deep dive into that problem and into a new idea that takes it seriously: recursive language models. The goal here is not hype. It’s to understand why long-context systems fail, why many existing fixes only partially work, and how recursion changes the mental model of what a language model even is.
Context is growing, but Reliability isn’t
Agentic workflows almost force longer contexts. A planning agent might reason for several steps, call a tool, inspect the result, revise the plan, call another tool, and so on. A coding agent might ingest an entire repository, write code, run tests, read error logs, and iterate. Each step adds tokens. Each iteration pushes earlier information further away in the sequence.
In theory, attention lets a transformer look anywhere it wants. In practice, that promise is conditional. Models are trained on distributions of sequence lengths, positional relationships, and attention patterns. When we stretch those assumptions far enough, we see degradation. The model still produces fluent text, but correctness, coherence, and goal alignment start to slip.
That slippage is what people loosely describe as context rot. It’s not a single bug. It’s a collection of interacting failures that only show up when you scale context aggressively.
Context rot is the gradual loss of effective information as a prompt grows longer. The tokens are still there. The model can technically attend to them. But their influence on the output weakens in ways that matter.
One way to think about it is signal-to-noise ratio. Early in a prompt, almost everything is signal. As the context grows, the model has to decide which parts still matter. That decision becomes harder when many tokens are only weakly relevant, or relevant only conditionally.
There are several root causes behind this effect, and they compound rather than act independently.
1. Attention dilution
Self-attention is powerful, but it’s not free. Each token competes with every other token for influence. When you have a few hundred tokens, that competition is manageable. When you have tens or hundreds of thousands, attention mass gets spread thin.
Important instructions don’t disappear, but they lose sharpness. The model’s internal representation becomes more averaged. This is especially problematic for agents, where a single constraint violated early can cascade into many wrong steps later.
2. Positional encoding degradation
Most transformer models rely on positional encodings that were trained on specific sequence length distributions. Even techniques designed for extrapolation, like RoPE or ALiBi, still face a form of distribution shift when pushed far beyond their training regime.
The model has seen far more examples of relationships between tokens at positions 1 and 500 than between positions 50,000 and 50,500. When you ask it to reason across those distances, you’re operating in a sparse part of the training distribution. The result is softer, less reliable attention.
3. Compounding reasoning errors
Long contexts often imply multi-step reasoning. Each step is probabilistic. A small mistake early on doesn’t just stay small; it conditions future steps. By the time you’re dozens of turns in, the model may be reasoning confidently from a flawed internal state.
This is a subtle but crucial point. Context rot isn’t just about forgetting. It’s also about believing the wrong things more strongly as time goes on.
4. Instruction interference
Another underappreciated factor is instruction collision. Long contexts often contain multiple goals, constraints, examples, and partial solutions. These can interfere with each other, especially when their relevance depends on latent state the model has to infer.
The longer the context, the harder it becomes for the model to maintain a clean hierarchy of what matters most right now.
The industry didn’t ignore this problem. Many clever workarounds emerged, especially from teams building real agentic systems under pressure. But most of these solutions treat the symptoms rather than the root cause.
File-system-based memory
One approach popularized in systems like Claude is to move memory out of the prompt and into a file system. The agent writes notes, plans, or intermediate results to files and reads them back when needed.
This helps with token limits and makes state explicit. But it doesn’t actually solve context rot. The model still has to decide what to read, when to read it, and how to integrate it. Poor reads or partial reads reintroduce the same problems, just one level removed.
Periodic summarization
Another common technique is context compression. The agent periodically summarizes its own conversation, keeping only a condensed version of the past.
This reduces token count, but it introduces lossy compression. Summaries are interpretations, not ground truth. Once something is summarized incorrectly or omitted, it’s gone. Over many cycles, small distortions accumulate.
Context folding
Context folding tries to be more clever by hierarchically compressing context: recent details stay explicit, older details get abstracted.
This works better than naive summarization, but it still relies on the model’s ability to decide what is safe to abstract. That decision itself is subject to the same attention and reasoning limits.
Enter Recursive Language Models
In October 2025, Alex Zhang introduced a different way of thinking about the problem in a blog post that later became a full paper. The core idea behind recursive language models is deceptively simple: stop pretending that a single forward pass over an ever-growing context is the right abstraction.
Instead of one giant sequence, the recursive language model operates recursively over smaller, well-defined chunks of state. Each step produces not just text, but structured state that can be fed back into the model in a controlled way.
This reframes the recursive language model less as a static text predictor and more as a stateful program.
How Recursion Language Models Address Context Rot
The key insight of recursive language models is that context does not have to be flat. Information can be composed.
Rather than asking the model to attend across an entire history every time, the system maintains intermediate representations that summarize and formalize what has already happened. These representations are not free-form natural language. They are constrained, typed, and often executable.
By doing this, the model avoids attention dilution. It doesn’t need to rediscover what matters in a sea of tokens. The recursion boundary enforces relevance.
Step-by-step: How Recursive Language Models work
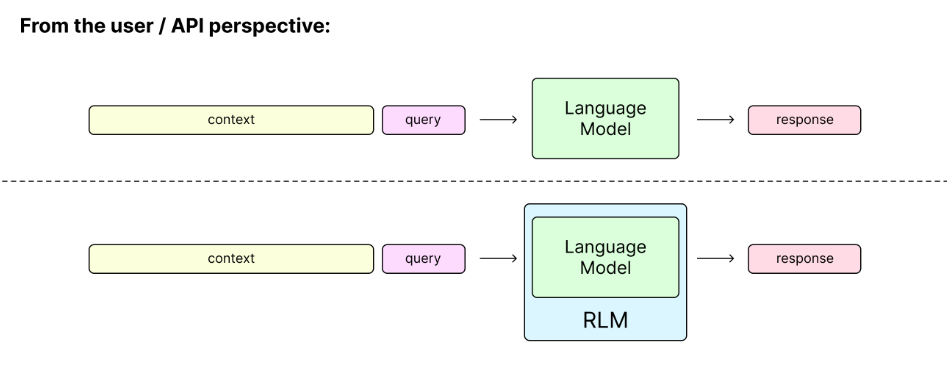
A recursive language model is not a new neural architecture. It is a thin wrapper around a standard language model that changes how context is accessed, while preserving the familiar abstraction of a single model call. From the user’s perspective, nothing looks different. You still call it as rlm.completion(messages), just as you would a normal language model API. The illusion is that the model can reason over near-infinite context.
Internally, everything hinges on a clear separation between the model and the context.
source: Alex Zhang
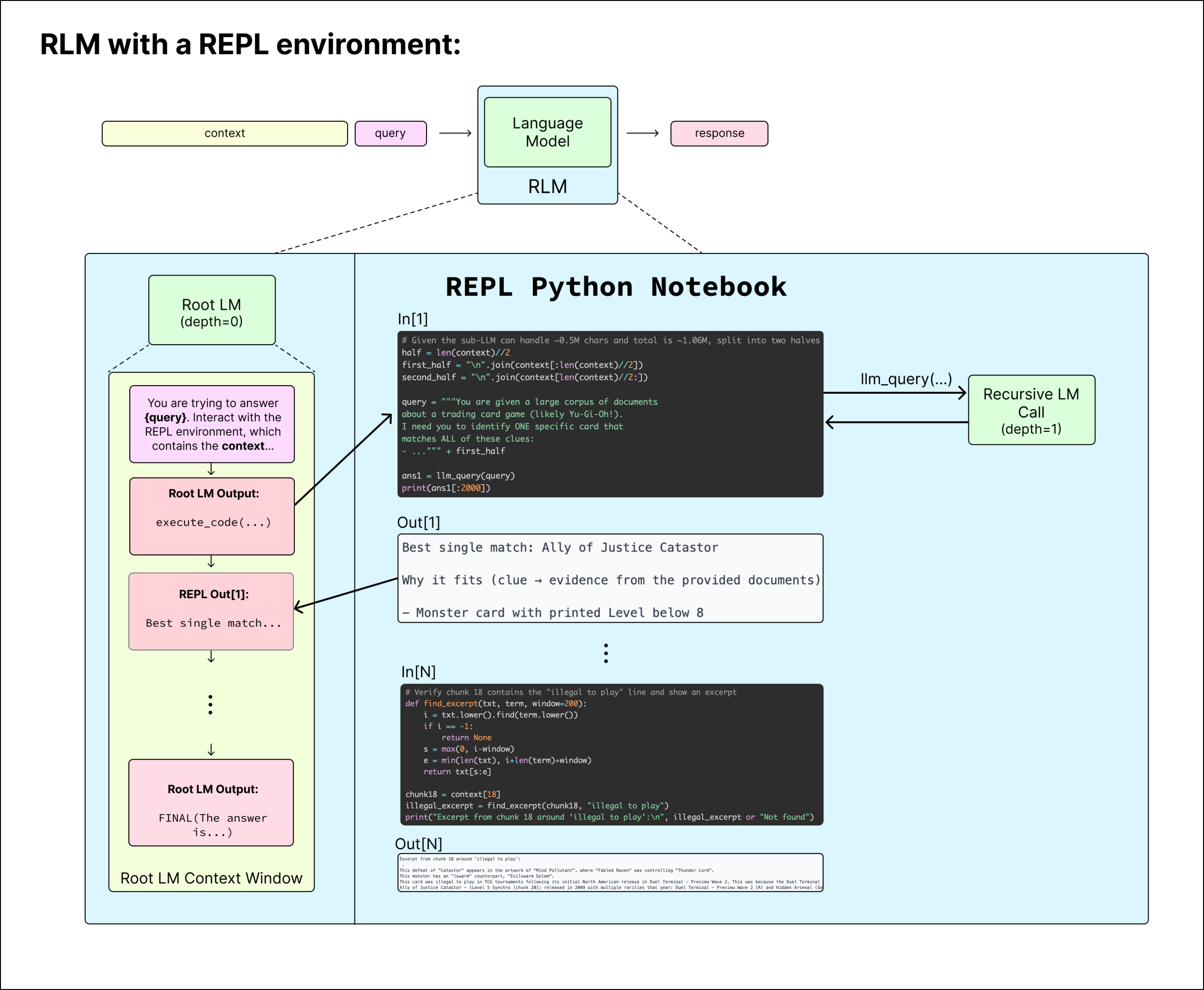
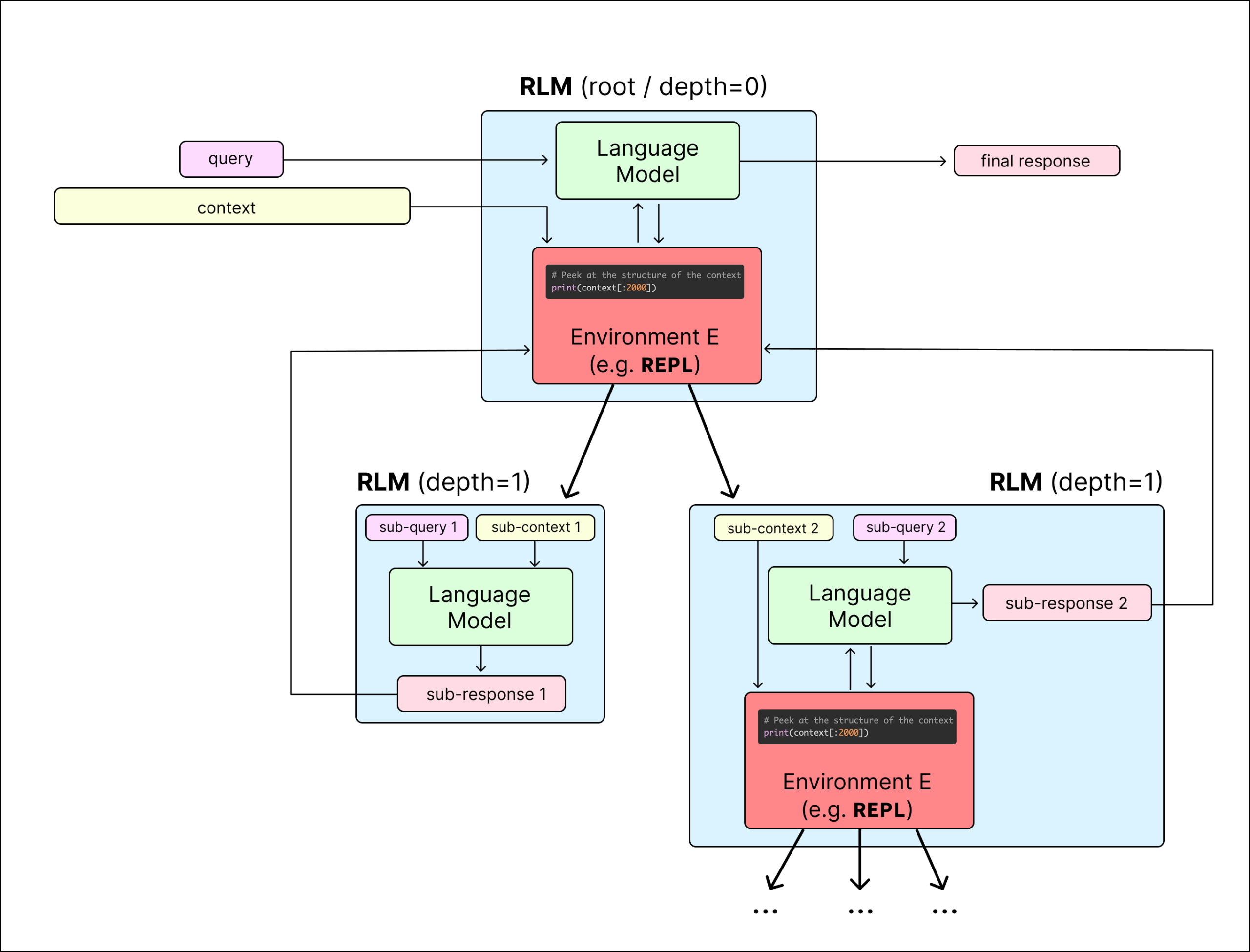
Each call to a recursive language model begins with what Alex Zhang calls the root language model, or the language model at depth zero. The root LM is only given the user’s query. The large body of associated context—documents, logs, codebases, transcripts—is not placed into the prompt at all. Instead, it is stored externally in an environment.
That environment is implemented as a persistent Python REPL loop, similar to a Jupyter Notebook. The full context is preloaded into memory as Python variables. For example:
Crucially, the root LM never sees context as tokens. It cannot attend over it. The context exists purely as data inside the environment.
The root LM interacts with this environment by emitting Python code. Each time the model outputs a code block, that code is executed in the REPL, and the result of the execution is fed back into the model’s context for the next step. Only the output is returned—typically truncated—so the root LM’s prompt stays small.
Suppose the user query is to find a specific fact buried somewhere in a massive document. The root LM might start by deciding how to look, not by trying to read everything. It expresses that decision as code:
The environment executes this code. Maybe the output is:
128
That output—just the number 128—is what the root LM sees next. The model has learned something important: there are many relevant lines, so it should narrow further.
It might then refine the query:
Again, the environment executes the code and returns a small slice of the result, such as a handful of example lines. At no point has the model attended over the full document. It has only seen evidence produced by deliberate queries.
source: Alex Zhang
This loop continues: the root LM writes code, the environment executes it, and the model observes the outputs. Through this process, the model can inspect subsets of the context, perform transformations, run regex searches, and store intermediate results as variables, all without bloating its context window.
At some point, the root LM may decide that a subset of the context is still too large or too semantically rich to handle procedurally. This is where recursion enters. From inside the REPL, the root LM can launch a recursive language model call, treating it like a function:
Here, filtered_chunk is a specific string or subset of the context stored in a variable. A new language model call is launched at depth one. That recursive LM sees only this small chunk, reasons over it, and returns a compact result—perhaps a summary, an extracted fact, or an answer to a sub-question.
The root LM receives the result, not the chunk itself. If needed, it can repeat this process, launching additional recursive calls over other subsets. Each call operates in a well-bounded regime, avoiding the attention degradation that comes with long contexts.
Throughout all of this, the root LM’s own context remains small and stable. It contains the user query, recent code it has written, and short execution outputs. The bulk of the context lives in Python memory, not in tokens.
Once the root LM decides it has enough information to answer the original query, it terminates the loop. It can either return an answer directly:
Or, if the answer was constructed inside the environment using variables and intermediate results, it can return:
From the outside, the user sees a single model call and a single response. Internally, the system has performed a structured exploration of arbitrarily large context using code, recursion, and explicit control flow.
This is why recursive language models avoid context rot at a fundamental level. The model does not try to read long context with attention. Instead, it queries it. Long context becomes data to be manipulated, not text to be attended over—and that shift in abstraction makes all the difference.
At first glance, recursive language models might seem like an implementation detail. After all, the user still makes a single model call and gets a single answer. But the shift they introduce is much deeper than an API trick. They change what we expect a language model to do when faced with long-horizon reasoning and massive context.
For the past few years, progress has largely come from scaling context windows. More tokens felt like the obvious solution to harder problems. If a model struggles to reason over a codebase, give it the whole repo. If it forgets earlier steps in an agent loop, just keep everything in the prompt. But context rot is a signal that this approach has diminishing returns. Attention is not a free lunch, and long contexts quietly push models into regimes they were never trained to handle reliably.
Recursive language models address this at the right level of abstraction. Instead of asking a model to absorb all context at once, they let the model interact with context. The difference is subtle but profound. Context becomes something the model can query, filter, and decompose, rather than something it must constantly attend to.
Conclusion
Context rot is not a minor inconvenience. It’s a fundamental symptom of pushing language models beyond the limits of flat, attention-based reasoning. As we ask models to operate over longer horizons and richer environments, the cracks become impossible to ignore.
Recursive language models offer a compelling alternative and what’s striking about this approach is how modest it is. There’s no new architecture, no exotic training scheme. Just a careful rethinking of how a language model should interact with information that doesn’t fit neatly into a single forward pass. In that sense, recursive language models feel less like a breakthrough and more like a course correction.
As agentic systems become more common and more ambitious, ideas like this will matter more. The future likely won’t belong to models that can attend to everything all the time, but to systems that know how to look, where to look, and when to delegate. Recursive language models are an early, concrete step in that direction—and a strong signal that the next gains in reliability will come from better structure, not just more tokens.
Ready to build robust and scalable LLM Applications? Explore Data Science Dojo’s LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI systems.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.