Loop engineering is the practice of designing how an AI agent runs, checks its work, and iterates – not just writing better prompts.
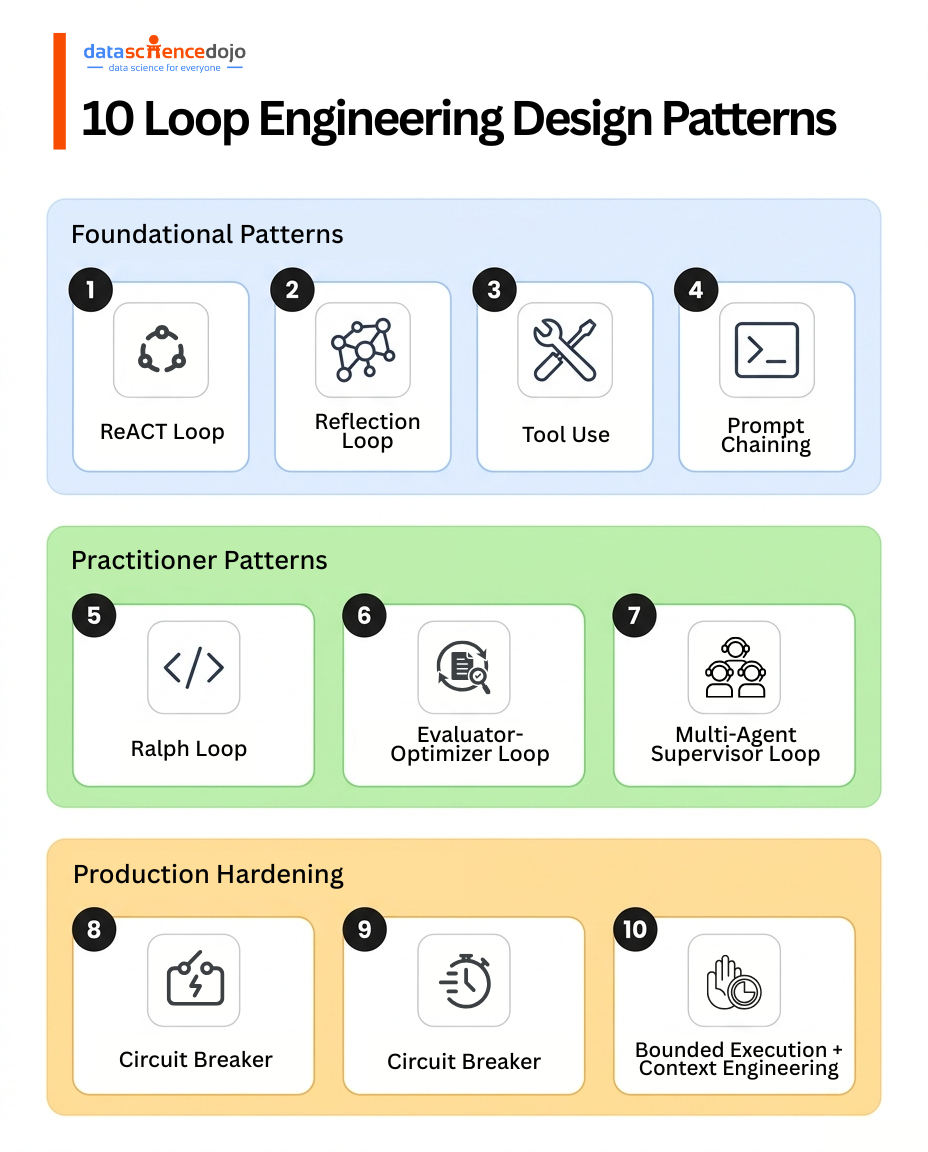
There are 10 core patterns, from the foundational ReAct loop to production controls like the Circuit Breaker and Bounded Execution.
Picking the wrong pattern is one of the most common reasons agentic systems fail in production – and most failures come from skipping the last three on this list.
What Is Loop Engineering?
Loop engineering is the practice of designing the execution environment around an AI agent. That includes the triggers, stopping conditions, feedback mechanisms, and failure controls that determine how the agent runs.
The shift from prompt engineering to loop engineering happened gradually, then fast. The ReAct paper (2022) gave researchers a framework for combining reasoning and action in a single cycle. By mid-2025, developers were running “ralph” bash scripts to automate agent iteration. By June 2026, a single post on the topic had crossed 6.5 million views in under 24 hours, and the phrase had become the center of gravity in agentic AI.
As Boris Cherny, who leads the Claude Code team at Anthropic, noted: his role has shifted away from direct model prompting toward writing the external execution loops that coordinate model actions.
For a full history of how loop engineering developed – from ReAct through the Ralph Loop to /goal commands in Claude Code and Codex – see our deep dive on agentic loops.
Why Design Patterns Matter in the Agentic Loop
Agents operating in loops face failure modes that don’t exist in standard LLM usage:
Infinite reflection cycles that consume tokens without making progress
Hallucinated tool calls that trigger real consequences
Context windows that fill up and silently degrade output quality
Runaway token spend when no stopping condition is defined
Design patterns give these failure modes names and solutions. The ten patterns below are drawn from three sources: Andrew Ng’s four foundational patterns, Anthropic’s five workflow patterns, and a set of production-hardening patterns that have emerged from real engineering teams in 2025 and 2026.
The 10 Loop Engineering Design Patterns
These patterns are organized in three tiers. Foundational loops that every builder should understand first, practitioner patterns for real workflows, and production controls for systems running at scale.
Foundational Patterns (1-4)
These are the building blocks. If you’re new to loop engineering, start here before reaching for anything more complex.
Pattern 1: The ReAct Loop
source: AI in Plain Language
The base pattern for agentic systems. ReAct stands for Reason and Act. The agent cycles through five stages – Perceive, Reason, Plan, Act, Observe – each feeding into the next until the task is complete or a stopping condition fires.
Every major AI lab (OpenAI, Anthropic, Google, Microsoft) has converged on this same core loop architecture. It’s the starting point for everything else in this list.
Pattern 2: Reflection Loop
The agent generates an output, then critiques it for gaps or errors before delivering the final result. The cycle continues until the output passes its own evaluation criteria.
This is the simplest self-correction pattern in loop engineering. It’s useful for:
Reducing hallucinations in factual outputs
Catching inconsistencies in generated code
Improving quality when latency is not the top priority
The limitation: it relies on the agent’s own judgment as the validator. For tasks where you need external verification, Pattern 5 or Pattern 6 gives you more control.
Pattern 3: Tool Use Loop
The agent calls external APIs and tools within the loop to access information that isn’t in its training data – current prices, database records, code execution results, or proprietary systems.
Tool use is the most established pattern in production agentic systems and the building block for most of the more complex patterns below. For a practical walkthrough of how this connects to a working multi-agent system using LangChain and LangGraph, this tutorial is worth bookmarking.
Pattern 4: Prompt Chaining
The output of one LLM call becomes the input of the next in a fixed, deterministic sequence. The agent doesn’t decide the next step – the code does.
Use this loop engineering pattern when:
Tasks break into clearly defined subtasks with a known order
You need high reliability and auditability over flexibility
Every step in the workflow needs to be traceable in source code
Prompt chaining sits on the workflow end of the control spectrum – high predictability, low autonomy. The further down this list you go, the more runtime decision-making the agent gets.
Practitioner Patterns (5-7)
These patterns add real-world constraints: external validation, structured critique, and multi-agent coordination.
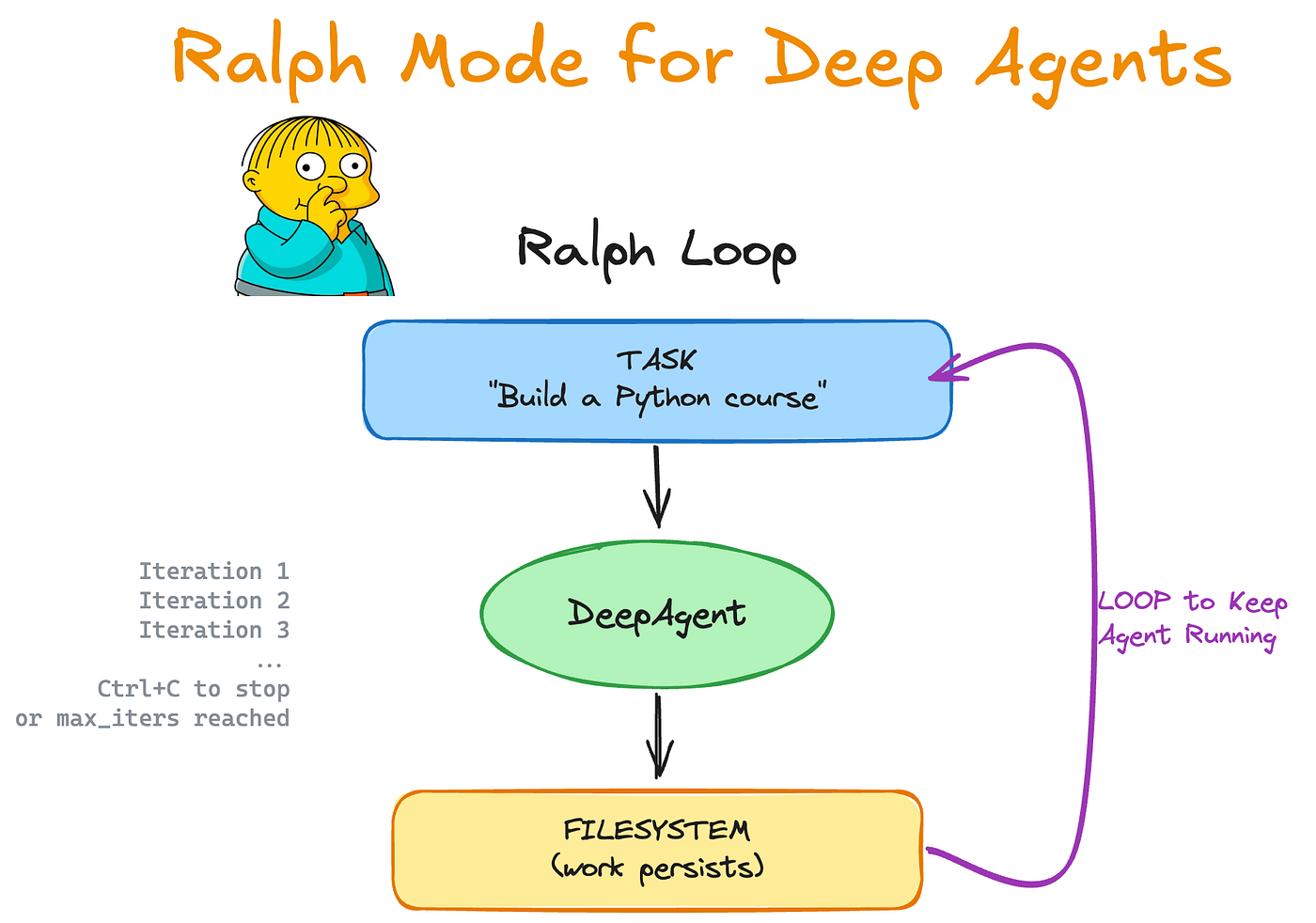
Pattern 5: The Ralph Loop
source: Dhanush Kumar
The Ralph Loop runs an agent in a continuous cycle until an external validator confirms success. The agent attempts the task, gets feedback from a compiler, linter, or test suite, and loops again until all checks pass.
The name comes from a bash one-liner created by Geoffrey Huntley in July 2025, named after the Simpsons character who walks into doorframes while announcing “I’m helping.” The humor is deliberate: the pattern is simple, even naive-looking, but it works reliably in practice.
Two things make it different from the Reflection Loop:
The exit condition comes from deterministic software checks (tests green, type errors zero), not the agent’s self-assessment
Each iteration resets context, which prevents context window degradation on long runs
Claude Code’s /goal command is a productized version of this loop engineering pattern. The most documented experiment ran for 25 hours uninterrupted and produced 30,000 lines of code.
Pattern 6: Evaluator-Optimizer Loop
In this pattern, a second agent – the evaluator – reviews the primary agent’s output and returns structured feedback. The primary agent revises its work based on that feedback, and the cycle continues until the evaluator approves.
The key difference from the Reflection Loop: the critic is separate from the generator. A dedicated evaluator makes it harder for the primary agent to pass low-quality work by agreeing with itself.
This loop engineering pattern works well for tasks with clear quality standards – code review, document drafting, structured data extraction.
Pattern 7: Multi-Agent Supervisor Loop
A supervisor agent coordinates multiple specialized workers. Each worker executes its own internal loop on a subtask, then returns a structured result to the supervisor. The supervisor routes the next task based on those results.
A Supervisor might coordinate a Researcher, a Coder, and a QA agent – each with its own tools, prompt, and loop. The Supervisor manages the flow; it doesn’t do the work itself.
Building on top of this pattern with retrieval? Agentic RAG covers how the supervisor-worker model combines with multi-source retrieval in LangGraph. For how agents communicate across frameworks using MCP, A2A, and ACP, the agentic AI communication protocols guide goes deep on the interoperability layer.
Production Hardening Patterns (8-10)
These patterns don’t define what the agent does. They define the conditions under which it’s allowed to keep running. Most production loop engineering failures happen because these were skipped.
Pattern 8: Circuit Breaker
A circuit breaker monitors the agent’s progress across iterations. If the agent is stuck – alternating between the same file states, repeating identical errors, failing to make measurable progress over three consecutive cycles – the breaker trips, terminates the loop, and alerts a human.
Without a circuit breaker, a stuck agent burns tokens indefinitely. This pattern directly addresses one of the most expensive failure modes in loop engineering.
Implementation steps:
Track a progress signal across each iteration (files changed, tests passing, new vs. repeated errors)
Define a stagnation condition (no new progress in N cycles)
On trip: log the full state, terminate the loop, send an alert
Restart only after a human has reviewed the failure
Pattern 9: Heartbeat Loop
The agent doesn’t run continuously. It wakes on a schedule or event, checks a defined condition, acts if needed, and sleeps until the next trigger.
This loop engineering pattern is more cost-efficient than a persistent agent because execution is bounded by the heartbeat frequency. A PR monitor, a daily report generator, or an alert classifier all fit this model naturally.
The key failure mode: overlapping heartbeats. If the previous cycle is still running when the next heartbeat fires, two agents work on the same state simultaneously. Every heartbeat implementation needs a “cycle in progress” lock.
Pattern 10: Bounded Execution and Context Engineering
Two patterns that almost always need to be implemented together.
Bounded Execution caps the loop at a defined limit: maximum iterations, maximum token spend, maximum wall time. Without it, a loop with no hard ceiling will eventually hit one you didn’t plan for – a cost spike, a rate limit, or a timeout.
Context Engineering controls what information the agent carries into each iteration. Context windows fill up as loops run longer, and output quality degrades before you notice. Context engineering is the practice of selecting, compressing, and isolating what goes into the window at each step.
Multi-agent systems cost up to 15x more per session than single-agent interactions. These two patterns, applied together, are the primary mechanism for keeping that cost manageable. The harness engineering guide covers how production teams bake these constraints into their infrastructure, not just their prompts.
How to Choose the Right Pattern
Loop engineering patterns are not mutually exclusive. Most production systems combine several.
A common starting stack:
Tool Use Loop as the base execution pattern
Bounded Execution as the hard ceiling
Circuit Breaker for stagnation detection
Multi-Agent Supervisor if the task exceeds a single context window
The general rule: start with the simplest loop that could work, then add complexity only when you can measure the improvement. A single ReAct agent with four tools handles the majority of real-world tasks. A full supervisor loop with circuit breakers and heartbeats is the right tool for long-running, high-stakes autonomous systems – not the default starting point.
FAQ
What is loop engineering? Loop engineering is the practice of designing the execution environment around an AI agent: the triggers, stopping conditions, feedback mechanisms, and failure controls that govern how it runs. It’s the layer above prompt engineering that determines how an agent behaves across multiple steps, not just a single response.
What is the difference between a ReAct loop and the Ralph Loop? The ReAct loop is the general pattern for agents that reason and act in cycles. The Ralph Loop is a specific implementation where the exit condition comes from external validation (tests passing, type errors zero) rather than the agent’s own judgment. The Ralph Loop is more reliable for coding tasks because the agent cannot pass its own work by agreeing with itself.
Which loop engineering pattern should I start with? Start with the ReAct loop and Tool Use as the base. Add Bounded Execution early – it’s the lowest-effort production safeguard. Layer in a Circuit Breaker once you have a working loop you want to run autonomously. Only add multi-agent patterns when a single-agent loop genuinely can’t handle the task.
How does loop engineering relate to harness engineering? Loop engineering focuses on the design of individual loops. Harness engineering is the broader discipline of building the infrastructure – constraints, tooling, feedback systems – that makes those loops reliable and repeatable across sessions. Loop engineering is one layer inside the harness.
Do I need all 10 loop engineering patterns? No. Patterns 1 through 4 are foundational and most developers will use all of them in some form. Patterns 8 through 10 are non-negotiable once a loop runs autonomously in production. Patterns 5 through 7 depend on the complexity of the task and whether a single agent is sufficient.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.