An agentic loop is a trigger + a verifiable goal. The agent runs until the goal is met – no prompting required.
Loop engineering is said to be the practice of designing those loops: specifying goals, setting triggers, and building the guardrails that keep them from running forever.
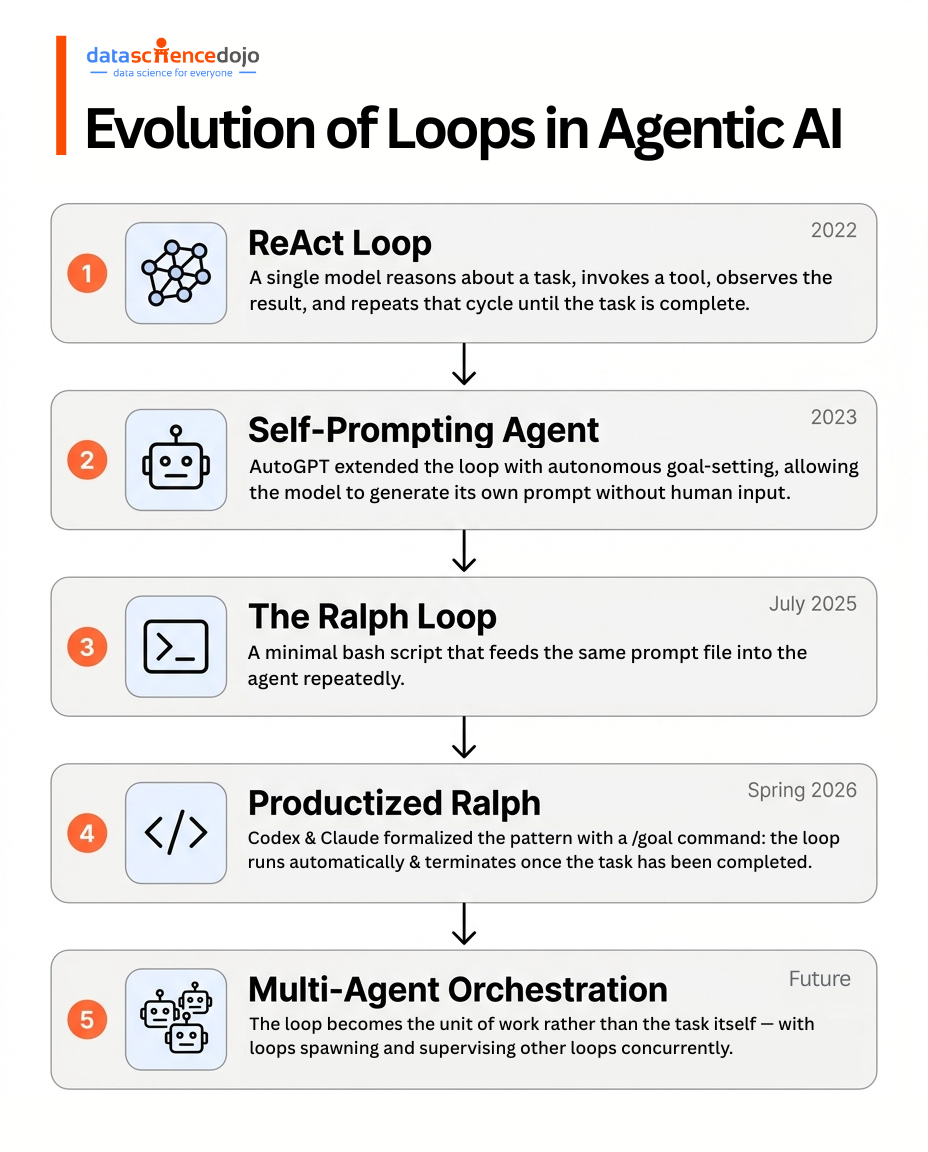
There are 10 distinct types of agentic loops, from ReAct (2022) to the Ralph Loop and OpenAI’s /goal command.
Loops fail without guardrails. Infinite loops, goal drift, and token cost explosions are common production problems – not edge cases.
Earlier this year, two posts from people at the center of AI coding set off a conversation that has not stopped since.
Boris Cherny, creator of Claude Code at Anthropic: “I don’t prompt Claude anymore. I have loops that are running. They’re the ones that are prompting Claude and figuring out what to do. My job is to write loops.”
Peter Steinberger, founder of OpenClaw, put it to his millions of followers:
Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
Steinberger’s post hit five million views in under twenty-four hours. Suddenly, developers everywhere were asking: what is a loop, and why does it matter?
This guide answers both and breaks down every major type of agentic loop and what loop engineering actually involves in practice.
What Is an Agentic Loop?
An agentic loop is simpler than it sounds. It only needs two things:
A trigger: Something that starts the loop (a PR opening, a schedule, a human saying “go”)
A verifiable goal: A defined end state the agent works toward
The agent does not wait for your next message. It starts, runs, checks whether the goal has been reached, and if not, loops again until it has, or until a stopping condition fires.
You give the agent a goal, not a prompt. It figures out the steps, runs them, checks its work, and keeps going.
This is what makes it different from prompt engineering. In the old workflow, you would prompt your agent, wait for it to finish, prompt again. Loop engineering aims to reduce your involvement.
Deterministic goals are easy: all tests pass, CI is green, the function runs without errors. The hard part is when the goals are like “build this feature” — where defining what done actually looks like requires writing a full spec upfront. That is what makes loop engineering hard, and valuable.
To understand what makes a loop possible at the model level, it helps to first understand what agentic LLMs actually are and how they differ from standard language models.
Loops vs. Automations: What’s the Difference?
Worth clarifying, because the two are could easily be confused.
An automation executes a series of steps. It runs a script. It follows a recipe. It does not decide anything.
A loop has decision-making inside it. The agent is actively determining whether it has reached the goal or not. It is not just executing – it is evaluating, looping, and adjusting based on what it finds.
The Three Trigger Types
Every agentic loop starts with a trigger. There are only three kinds:
Event-based – something happens: a PR opens, a file changes, an API call completes
Scheduled – a cron job fires: every 30 minutes, every hour, every day
Human-initiated – you type a goal and say go
Claude Code’s /loop command is the human-initiated type in its simplest form: /loop every 5 minutes, compare what we have built with our full spec and continue building until we complete it.
How an Agentic Loop Works Internally
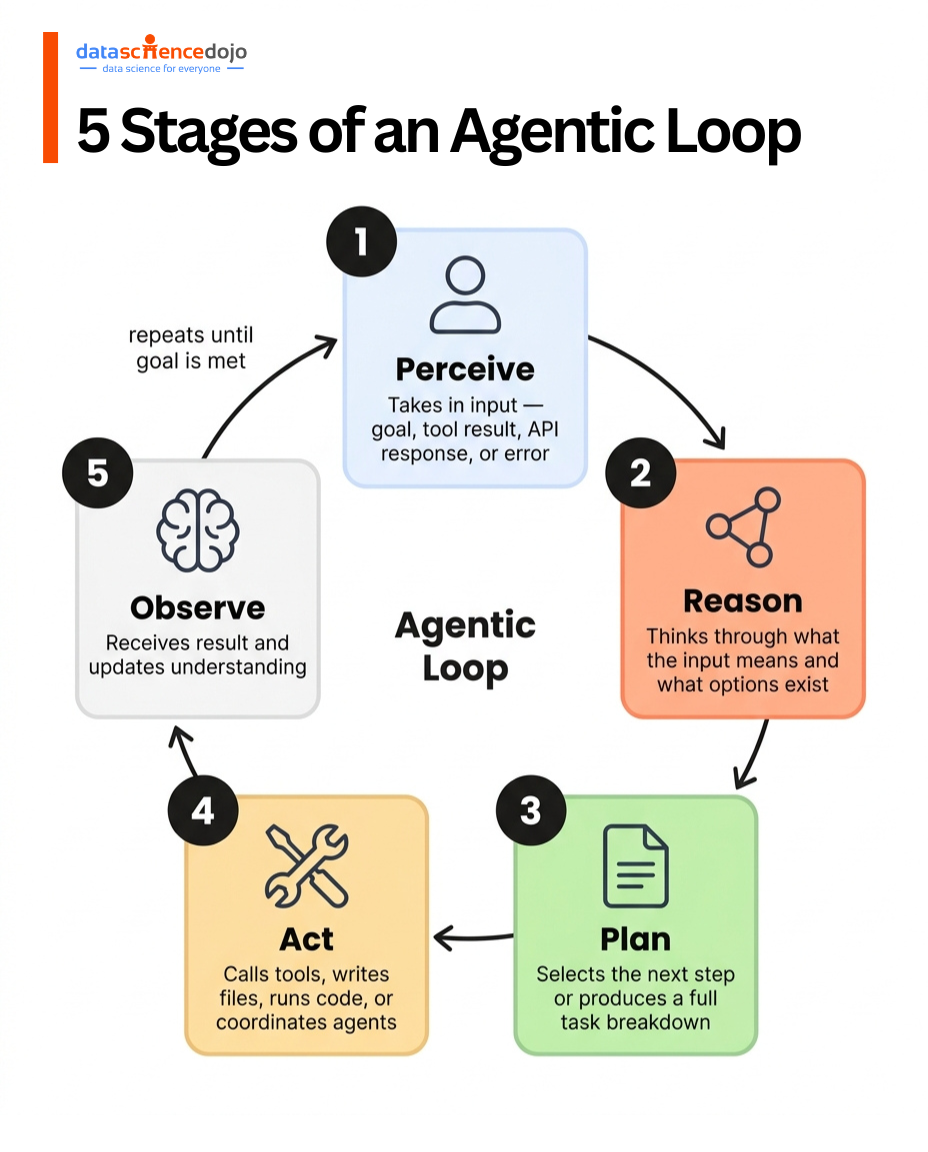
Every agentic loop runs through five stages, repeating until a stopping condition is met.
1. Perceive – Takes in input: the user goal, a tool result, an API response, or an error from the last action.
2. Reason – Thinks through what the input means, what it already knows, what it still needs, and what options it has.
3. Plan – Selects what to do next. Simple loops pick one step. Complex architectures produce a full task breakdown.
4. Act – Executes: calls tools, writes files, runs code, queries databases, or coordinates other agents.
5. Observe – Receives the result and updates its understanding. Success moves it forward. Failure triggers reasoning about why.
Then it loops back to step 1.
This structure has a direct parallel to reinforcement learning. A loop needs a verifiable reward signal — the equivalent of knowing when the goal has been reached. That reward can be deterministic (tests pass, no type errors) or non-deterministic (an LLM evaluates whether the output meets the goal).
When Does a Loop Stop?
LLMs have no built-in concept of “done.” Without explicit stopping conditions, a loop runs until the money runs out.
Every production agentic loop needs:
A hard iteration cap
A token and cost budget per run
No-progress detection (exit if nothing changes across iterations)
A goal-achievement check against verifiable criteria
Timeouts at both the task level and individual tool-call level
“Let the agent decide when it’s done” is a strategy that could exhaust your token limit sooner than you can think. Every loop type covered below was built, in part, to solve that problem.
Every Type of Agentic Loop Explained
Generation 1: Proof of Concept (2023)
AutoGPT
Released March 30, 2023. The first loop that put the concept in front of millions of developers.
How it works:
Give GPT-4 a high-level goal
It breaks the goal into sub-tasks
Executes using tools: web browsing, file management
Reflects on results and loops
AutoGPT hit 100,000 GitHub stars within months. It proved the demand was real.
However, AutoGPT wasn’t widely adopted by everyday users because it was expensive and unreliable. Users complained that it often got stuck in infinite loops and ran up massive API bills.
While the open-source concept paved the way for modern loops, it functioned more as a fascinating technical experiment than a reliable productivity tool
Generation 2: Academic Frameworks (2022-2023)
ReAct
Published October 6, 2022 – five months before AutoGPT. From Princeton and Google Research.
ReAct stands for Reasoning + Acting. At each step the agent produces two things:
A reasoning trace: “I need to check the API rate limit before calling this endpoint”
A concrete action: the actual tool call or search
The observation from each action feeds into the next reasoning step. When something unexpected comes back, the agent can reason about why rather than retrying blindly.
Results: 34% improvement on ALFWorld, 10% on WebShop versus action-only approaches.
ReAct is the pattern inside LangChain’s AgentExecutor and most production coding agents. The default starting point for any loop engineering work.
Reflexion
NeurIPS 2023. ReAct with a self-evaluation layer.
After completing or failing a task, the agent generates a critique of what went wrong. That critique gets stored in memory and injected into the next attempt’s context.
More expensive than ReAct (extra LLM calls for reflection)
Better on trial-and-error tasks: debugging, unfamiliar codebases, creative problem-solving
Usually not worth the overhead for straightforward retrieval
ReAct is the foundation. Reflexion builds a learning layer on top.
Plan-and-Execute
Separates thinking from doing.
A planner generates a full task breakdown upfront
An executor works through each step
A re-planner adjusts when execution diverges from the plan
LangChain’s LLMCompiler reported a 3.6x speedup over sequential ReAct by running independent steps in parallel (Kim et al., ICML 2024).
Tradeoff: less adaptive when early steps produce unexpected results. Plan-and-Execute commits to a plan. ReAct recalibrates at every step.
Generation 3: Architectural Patterns (2024)
OODA Loop
From US Air Force Colonel John Boyd: Observe, Orient, Decide, Act.
The distinctive contribution is the Orient step. Most loops jump from observation to decision. OODA inserts a contextualising step first – the agent processes raw observations against its goals, constraints, and prior knowledge before deciding.
For agents in complex, fast-changing environments, that extra step measurably improves decision quality.
Inner/Outer Dual Loop
Microsoft’s Magentic-One architecture.
Outer loop: strategic planning, monitors progress against the original goal
Inner loop: step-by-step execution within the current strategy
When the inner loop stalls, the outer loop resets the entire strategy – not just retries the current step. Prevents the “insistent failure” pattern where an agent repeats a broken approach because it has no mechanism to step back.
Multi-Agent Orchestration
A supervisor assigns work to specialised sub-agents: planners, executors, researchers, verifiers. The supervisor coordinates rather than executes.
The numbers:
Anthropic’s multi-agent research system outperformed single-agent by 90.2% on internal evaluations
Single agents consume ~4x more tokens than standard chat
Multi-agent systems consume ~15x more
The OpenAI Agents SDK is one of the most accessible frameworks for building this orchestration layer today.
Multi-agent is right for tasks requiring parallel exploration or genuine complexity beyond one context window. Overkill for most tasks, and the cost has to be justified.
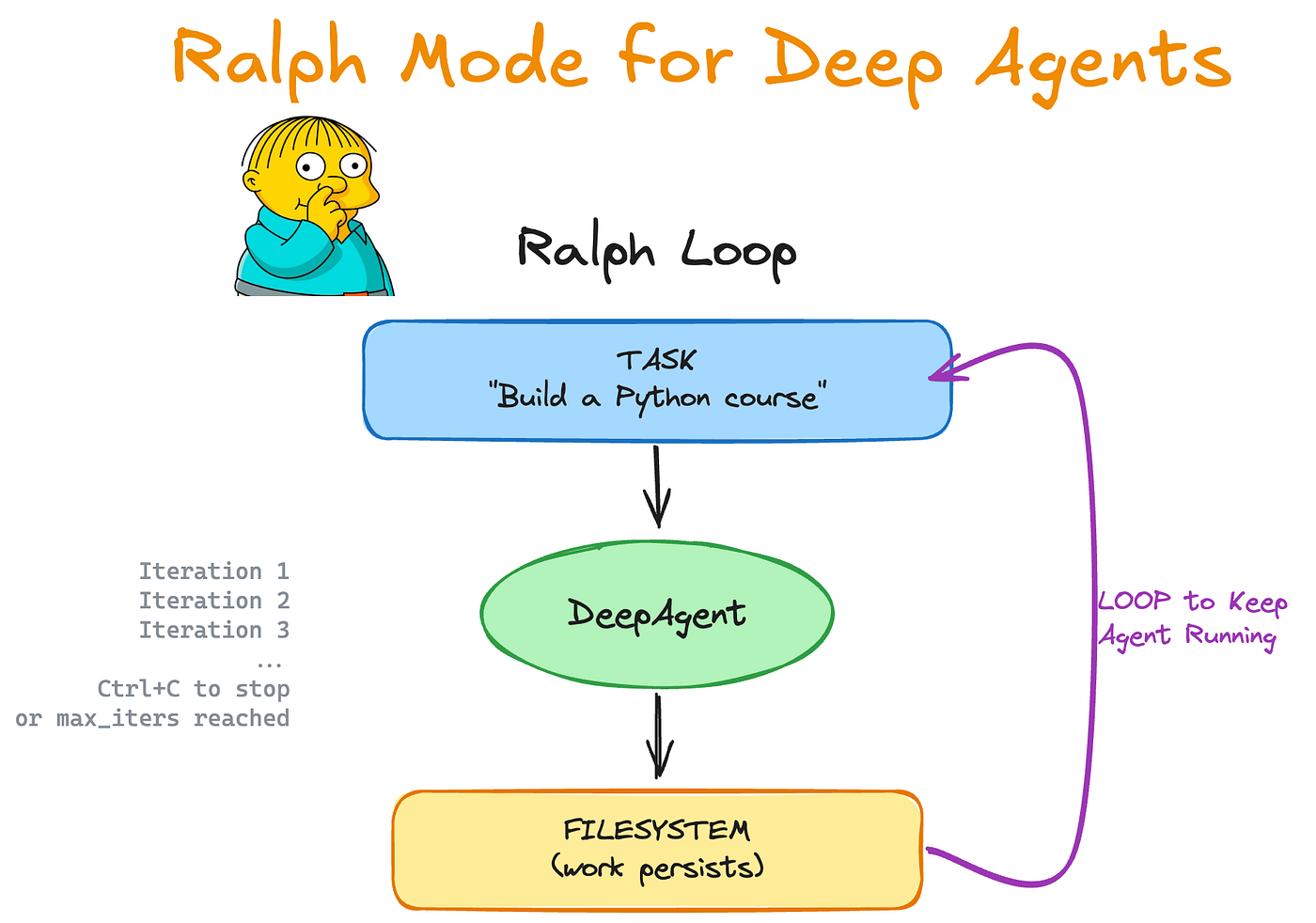
Invented by Geoffrey Huntley in July 2025. Named after the Simpsons character who announces “I’m helping!” while walking into doorframes. Deliberately simple, surprisingly effective.
How it works:
A coding agent runs inside an infinite shell loop
Each iteration reads the same prompt file from disk
The agent modifies the codebase and exits
The loop restarts with a fresh context window
State lives in the file system – codebase, TODO file, git history
Two problems it solves:
Context overflow – long sessions degrade as the context window fills. The Ralph Loop resets context each iteration; the new session reads current state from disk.
Premature exit – LLMs stop when they subjectively decide the task is complete. A Stop Hook intercepts exit attempts, checks whether completion criteria are actually met (tests green, coverage above threshold, type checks clean), and reinjects the task prompt if they are not.
It was released at a hackathon but quickly became a standard pattern in under six months.
The /goal Command (OpenAI Codex CLI) and /loop (Claude Code)
Two native implementations of persistent loop engineering built directly into AI coding tools.
Claude Code /goal shipped in version 2.1.139 on May 12, 2026. You set a completion condition, and Claude works autonomously across multiple turns until that condition is met — tracking elapsed time, turns, and tokens as it goes. Available in interactive mode, the -p flag, and Remote Control. Early adopters called it “the most underrated AI feature of 2026” because it eliminates the manual iteration cycle on multi-step tasks entirely. The key mechanic: a separate evaluator model checks whether the goal condition is met at the end of each turn, and only stops the loop when it passes.
Codex CLI /goal (v0.128.0): the same concept, Codex-side. Sets a durable objective that survives session breaks. Off by default — requires a TOML config edit to enable. In one documented experiment: 25 hours uninterrupted, 13 million tokens, 30,000 lines of code.
Both require explicit goal specification upfront. The more abstract the goal, the more expensive and unpredictable the loop.
Boris Cherny’s Parallel Loop Workflow
The workflow that made loop engineering visible to a mainstream developer audience.
The setup:
5 Claude Code instances in terminal, numbered by tab
5-10 Claude sessions in the browser simultaneously
System notifications to check in only when an agent needs input
A “teleport” command to hand context between local and cloud
CLAUDE.md as a persistent instruction layer every new session reads on startup
The CLAUDE.md practice is the key insight. Every mistake an agent makes, the correction goes into CLAUDE.md. Future sessions do not repeat it. The file becomes a cumulative record of project knowledge that survives context resets.
Memory in Agentic Loops
Memory is what separates a loop that learns from one that just repeats. Without it, every iteration starts blind.
The four types used in production:
Episodic memory – records of prior actions and outcomes. The agent recalls that a specific approach failed and avoids repeating it.
Vector memory – similarity-based retrieval. Finds relevant context even when the original was stored differently from how it is being requested.
File-based memory – the Ralph Loop approach. State lives in the file system. Simpler and more reliable for coding tasks than a vector store.
CLAUDE.md is human-curated semantic memory. More reliable than auto-generated memory because a human decides what goes in.
For a deeper look at memory architecture in agentic systems, Large Action Models Explained covers how memory enables long-horizon tasks.
Agentic loops also connect directly to RAG. When a loop retrieves external knowledge mid-execution, it is running an agentic RAG pattern – dynamically deciding when and what to retrieve rather than doing it once upfront.
Failure Modes
These show up in production. Every one of them.
Infinite loops – no objective goal verification. The agent keeps refining because it can always find something to improve. AutoGPT’s 2023 incident is the canonical example.
Goal drift – the agent pursues a related but different goal. Caused by an ambiguous spec or a tool result that pulls it sideways.
Context overflow – long sessions fill the context window and reasoning degrades. The Ralph Loop exists to address this.
Silent failures – the agent produces confident output while making no real progress. Tool calls are happening. Nothing is actually changing. The hardest to catch.
Token cost explosion – single agents at ~4x standard chat, multi-agent at ~15x. Steinberger acknowledged $1.3 million in monthly token usage at one point. One documented loop incident: an agent called a broken tool 400 times in five minutes.
Error propagation – one bad decision early in the loop compounds through every subsequent step. Validate at each stage, not only at the end.
Loop Engineering: Guardrails
The difference between loop engineering and just running loops is that loop engineering includes the guardrails. These are not optional.
Hard iteration cap – maximum cycles before the agent stops and reports current state
Token and cost budget – hard spending limit per run, built in from day one
No-progress detection – exit if output state has not changed across iterations
Circuit breakers – retry limits on tool calls, clear failure reporting after a set number of attempts
Termination criteria – define what “done” means before the loop starts, using verifiable automated checks not agent self-assessment
Human-in-the-loop checkpoints – mandatory review before irreversible actions: database writes, deployments, external API calls
The goal is not to eliminate autonomy. It is to bound it.
The Agentic OS Architecture post goes deeper on how production systems handle failure detection and replanning at the infrastructure level.
Choosing the Right Loop
Start with the simplest loop that could work. Add complexity only when you can measure the improvement.
Task
Recommended loop
Single-step tool use with retries
ReAct
Multi-step task needing self-correction
ReAct + Reflexion
Long codebase refactor or build
Ralph Loop or /goal
Parallel independent research threads
Multi-Agent Orchestration
Complex planning with known dependencies
Plan-and-Execute
Rapidly-changing environment
OODA
Strategy may need a full reset
Inner/Outer Dual Loop
A single ReAct agent with four tools handles the majority of real-world tasks. Multi-agent systems cost ~15x more per session. That cost needs to be justified by the output.
Is Loop Engineering for Everyone Right Now?
Honest answer: no.
Loop engineering is genuinely powerful, but the token costs are real. Single agents consume ~4x more tokens than standard chat. Multi-agent systems consume ~15x more. Running parallel loops across multiple sessions, as Cherny and Steinberger do, requires the kind of token budget that only a handful of companies currently provide to their engineers without limit.
Both Cherny and Steinberger work at companies — Anthropic and OpenAI respectively — where that budget effectively does not exist as a constraint. That is the environment in which these workflows were developed and refined.
The cost is real. The technique is real. The gap between those two facts is where most developers currently sit.
That gap will close. It always has with compute. What costs a fortune today becomes routine infrastructure in a few years. Loop engineering is worth understanding now, even if the economics do not yet make sense at your current scale.
What Comes Next
Agent harnesses are becoming the primary developer tool – orchestration logic, memory management, cost controls, and observability that makes loop engineering reliable at scale
Auditability is becoming non-negotiable as loops take consequential actions over longer time horizons
Self-optimising loops that track their own token usage and adjust approach are moving from experimental to production
The human’s role is shifting from writing code → writing prompts → designing loops → building the factory that runs the loops
Whether humans will eventually be removed from the loop entirely is an open question. Right now, they are still required. But the direction is clear.
The developers getting ahead now are not writing better prompts. They are learning loop engineering.
Frequently Asked Questions
What is an agentic loop? An agentic loop is an AI agent running cycle that has a trigger and a verifiable goal. The agent starts, works toward the goal, checks whether it has been met, and loops until it has – without waiting for a new prompt at each step.
What is loop engineering? Loop engineering is the practice of designing, specifying, and maintaining agentic loops. It involves defining verifiable goals, choosing the right trigger type, selecting the right loop architecture, and building the guardrails that prevent runaway costs and infinite cycles.
What is the difference between an agentic loop and an automation? An automation executes a series of steps. A loop has decision-making inside it – the agent actively evaluates whether the goal has been reached and loops based on that evaluation. The key difference is the goal-verification step.
Which loop type should I start with? ReAct. It is the most broadly applicable, best documented, and the foundation most production frameworks build on. Add complexity only when ReAct hits a clear limit.
Why do agentic loops fail in production? Most failures trace to four causes: no hard stopping conditions, underspecified goals, context overflow in long sessions, and missing cost controls.
Is loop engineering expensive? Yes, significantly. Single agents consume ~4x more tokens than standard chat, multi-agent systems ~15x more. Running parallel loops at scale — as the engineers who pioneered these workflows do — can reach seven-figure monthly token bills. The costs are expected to fall as the technology matures, but are real today.
How does agentic RAG relate to agentic loops? Agentic RAG is a loop pattern where retrieval is embedded inside the reasoning cycle – the agent decides dynamically when and what to retrieve based on what it discovers mid-loop, rather than retrieving once upfront.
Conclusion
The shift is already underway. The prompt was the unit of AI interaction for the first few years of this era. Loop engineering is replacing it.
Start with ReAct. Add Reflexion when you need self-correction. Use the Ralph Loop or /goal when long-running tasks hit context limits. Define your goal clearly before you start. Build guardrails before you build complexity.
The developers getting the most out of agentic AI right now are not writing clever prompts. They are building well-bounded loops that finish tasks reliably – and learning loop engineering before it becomes mainstream.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.