“Agentic OS” is not a product you install — it’s an architectural pattern that adds a management layer on top of AI agents so they can coordinate, share memory, and improve over time.
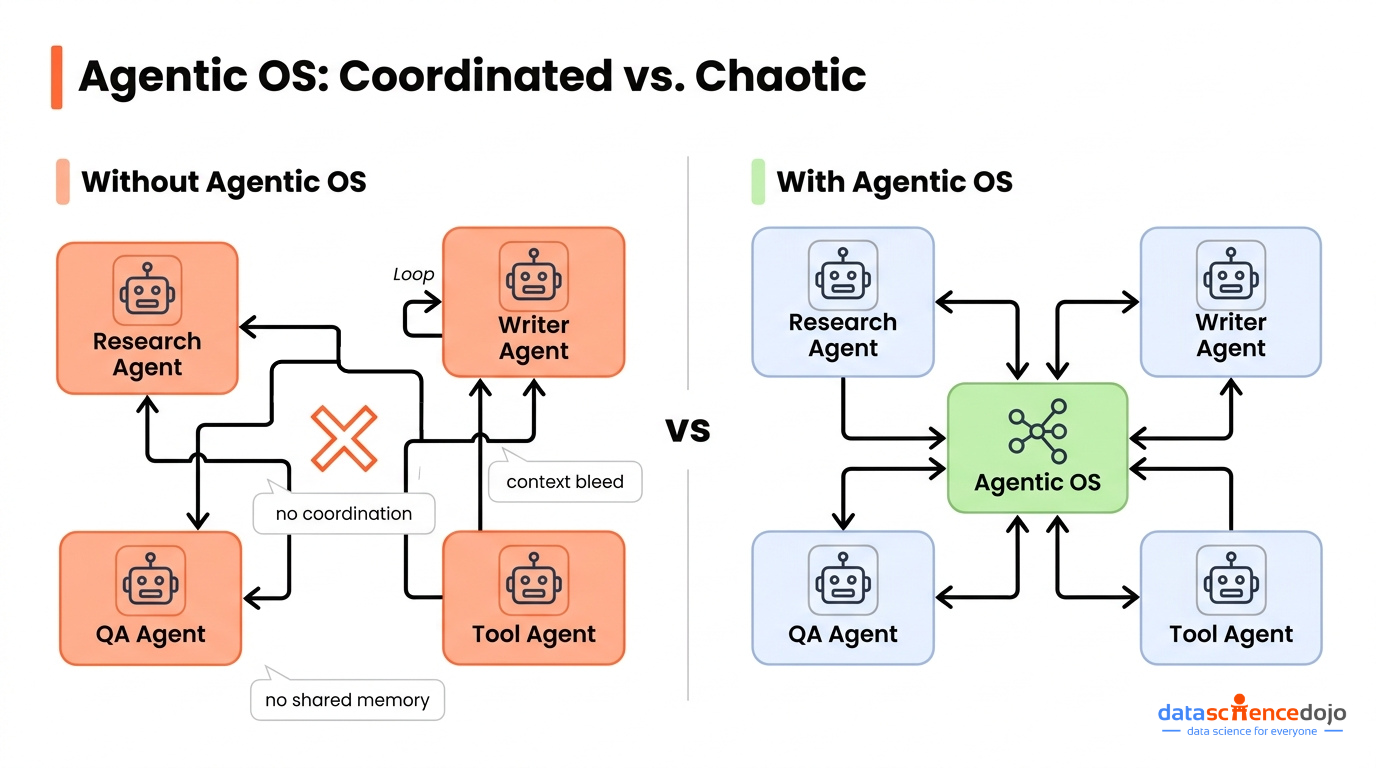
Without this layer, multi-agent systems break in predictable ways: agents contradict each other, forget context, and fail silently.
The pattern borrows directly from how operating systems manage processes — and that analogy turns out to be more useful than it sounds.
The Honest Answer Up Front
“Agentic OS” has become one of those terms that means everything and nothing at the same time.
Ask five engineers what it means and you’ll get five different answers. Ask a vendor and they’ll tell you their product is the Agentic OS. Ask Reddit and you’ll mostly get skepticism.
Here’s the fair take: the term is overused, but the underlying pattern is real and worth understanding.
This guide explains what an Agentic OS actually is, why the pattern exists, what its core components look like in practice, and where current implementations still fall short.
What Problem Does Agentic OS Actually Solve?
Before getting into what it is, it helps to understand why it exists.
Most people building with LLMs start with a single agent. It works well for simple tasks. Then requirements grow — the agent needs to search the web, write code, query a database, summarize documents, and make decisions across all of it. So you add tools. Then memory. Then you realize one agent doing everything is fragile, slow, and hard to debug.
The natural next step is splitting the work across multiple specialized agents. But now you have a different problem: who coordinates them?
Without a coordination layer:
Agents don’t know what other agents have done, so they repeat work or contradict each other
There’s no shared memory, so every agent starts from scratch on every run
When one agent fails, nothing knows how to recover — the whole pipeline stalls
Context bleeds between agents in unintended ways, producing inconsistent outputs
This is exactly the problem an Agentic OS is designed to solve. It’s the layer that sits above your agents and manages how they work together.
An Agentic OS is a software layer that manages multiple AI agents — coordinating how they plan, act, share memory, and learn — without requiring a human to intervene at every step.
The OS analogy holds up better than most tech analogies. A traditional operating system doesn’t do your work. It manages the resources — memory, CPU, I/O — that make work possible. It decides which process runs when, what memory each process can access, and how they communicate with each other.
An Agentic OS does the same thing, but for agents:
It allocates context and decides what each agent knows before it runs, so agents get exactly the information they need and nothing they don’t
It routes tasks and determines which agent is responsible for which part of a goal, based on capability and availability
It manages memory and maintains a shared knowledge layer that agents can read from and write to across sessions
It handles failures and detects when an agent produces a bad output or gets stuck, and triggers replanning instead of halting
Without this layer, you have a collection of agents. With it, you have a system.
The agents doing the actual work inside this system are LLM-based — models that can reason, use tools, and act across multiple steps. For a detailed look at how those models work and what makes them genuinely agentic, Agentic LLMs in 2025: How AI Is Becoming Self-Directed, Tool-Using & Autonomous covers the landscape well.
What Makes This Different From a Regular Multi-Agent Pipeline
This is the question the definition doesn’t answer on its own — and it’s worth being direct about.
A standard multi-agent pipeline is static. You define the flow upfront: agent A runs first, passes output to agent B, agent B passes to agent C. The coordination logic is hardcoded into the pipeline itself. It works well when inputs are predictable and nothing breaks. But change the input shape, add a new requirement, or have one agent fail — and the whole thing needs to be manually updated or it stops.
An Agentic OS moves coordination out of the pipeline and into a runtime layer. Instead of following a fixed script, the orchestrator decides at runtime how to break down a goal, which agents to involve, and in what order — based on the actual task in front of it. If a sub-task fails, it doesn’t halt. It replans. If a different approach is needed for a specific input, it routes differently. The pipeline adapts to the work, rather than forcing the work to fit the pipeline.
The simplest way to put it: a multi-agent pipeline follows a script. An Agentic OS writes the script on the fly and rewrites it when something goes wrong.
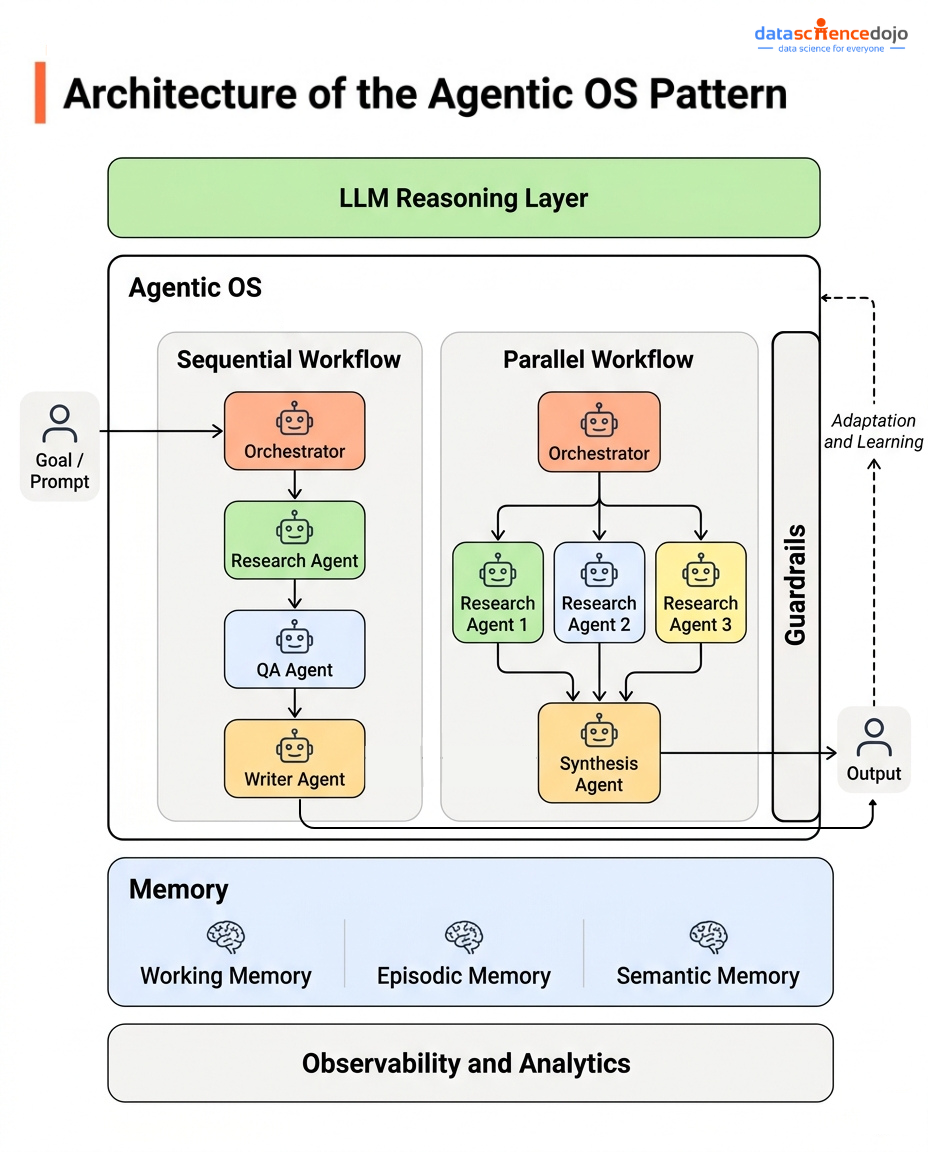
The Five Core Components
Every serious implementation of this pattern, whether you’re building it yourself or using a framework, needs these five components working together.
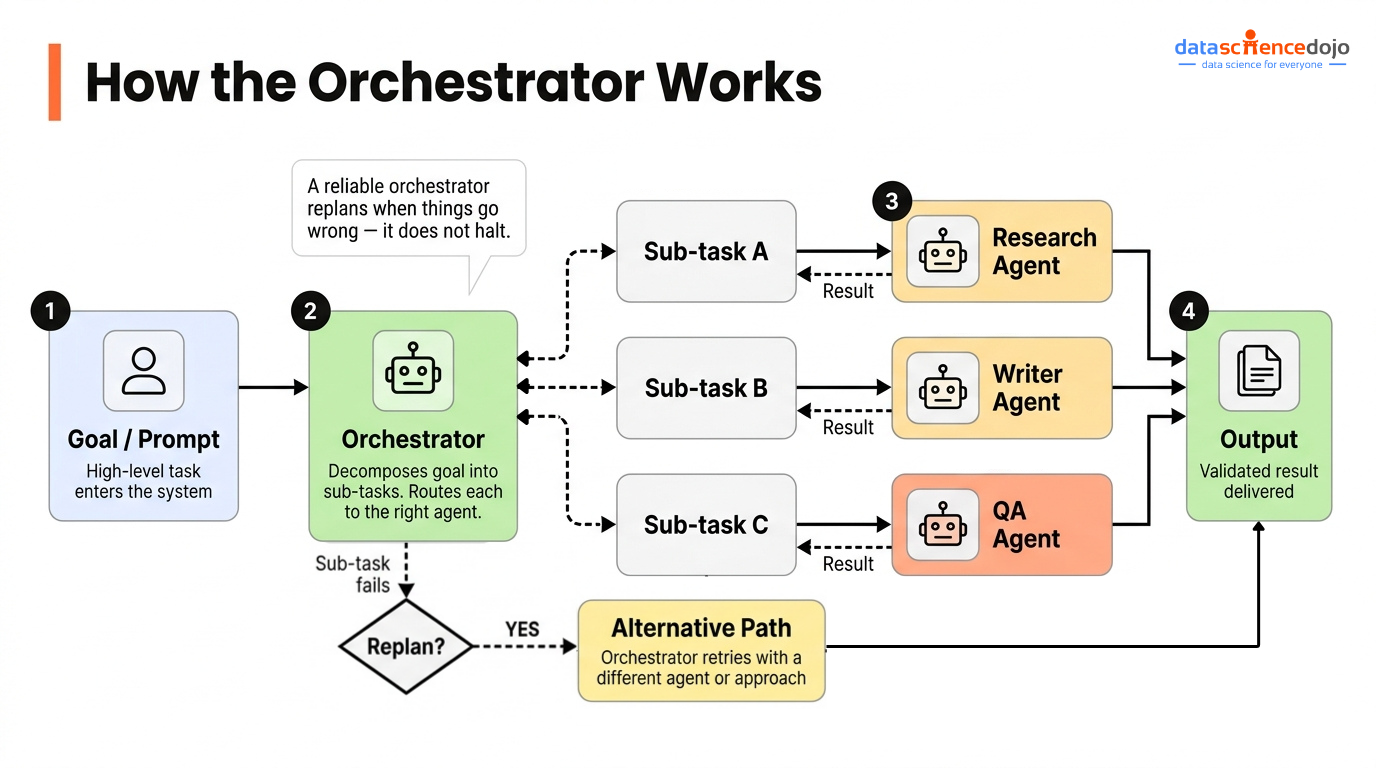
1. The Orchestrator
The orchestrator is the entry point for every goal that enters the system. It receives a high-level task, figures out what needs to happen, and coordinates the agents that execute it.
Think of it as the kernel of your Agentic OS — the component everything else reports to.
What a well-built orchestrator does:
Decomposes goals into sub-tasks that are specific enough for a specialist agent to execute without ambiguity
Routes each sub-task to the right agent based on what that agent is designed to do, not just what’s available
Tracks completion across all running agents and knows when to wait, when to proceed, and when to replan
Handles failures without halting — if a sub-task fails, the orchestrator tries an alternative path rather than crashing the whole pipeline
The key quality that separates a good orchestrator from a fragile one is replanning. Anyone can build an orchestrator that works when everything goes right. A reliable one keeps moving when things go wrong.
2. Memory Architecture
This is where most early multi-agent systems break. If agents have no persistent memory, every run starts from scratch. Your agentic sytem would just be a collection of stateless API calls dressed up as agents.
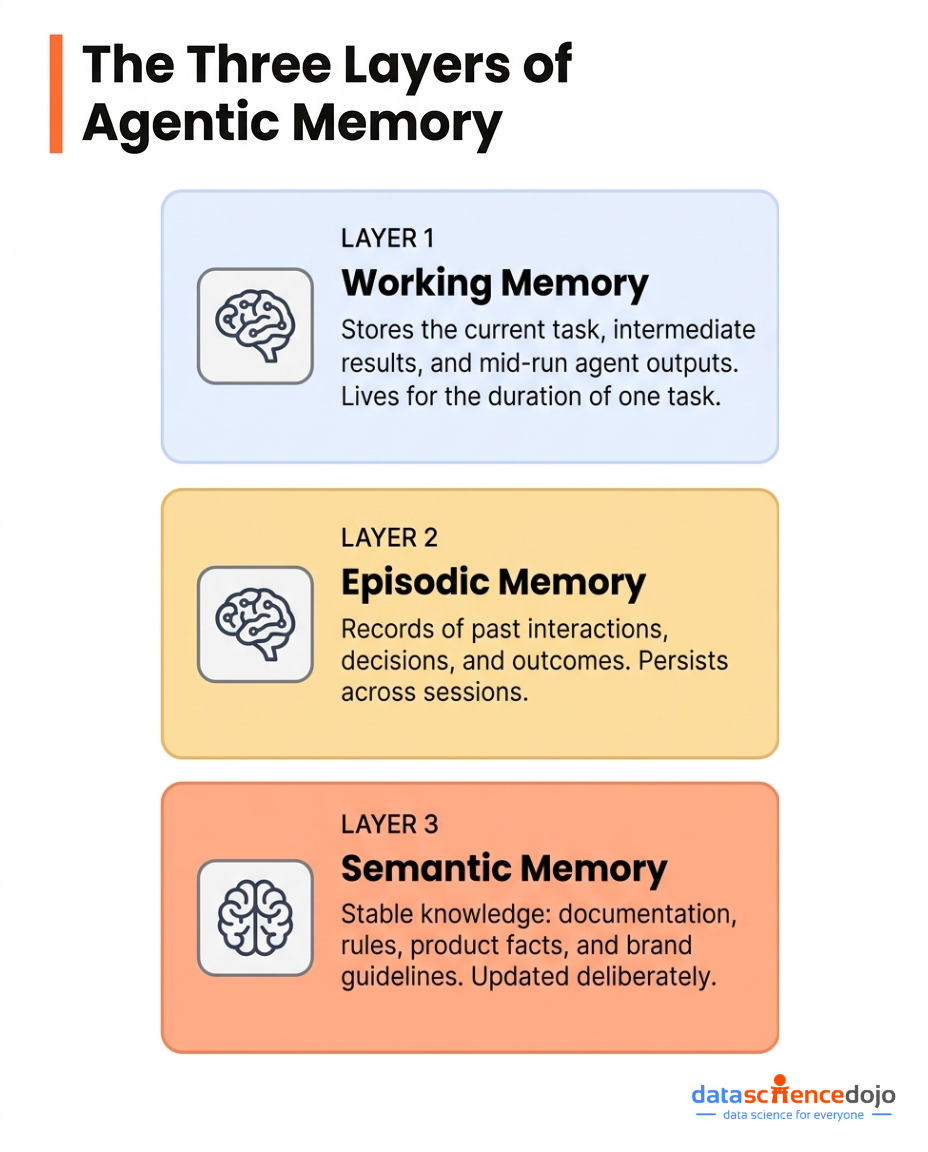
A proper Agentic OS maintains three distinct memory layers:
Memory Type
What It Stores
Lifespan
Working Memory
The current task, intermediate results, and agent outputs mid-run
Lives for the duration of one task
Episodic Memory
Records of past interactions, decisions, and outcomes
Before an agent runs, the system queries the relevant memory stores and injects only the entries that matter for that specific task into the agent’s context. The agent doesn’t get a dump of everything the system knows — it gets a targeted slice. This retrieval step is essentially RAG applied to agent memory, which is covered in depth in Agentic RAG: A Powerful Leap Forward in Context-Aware AI.
Writing to memory is just as important as reading from it. Not every agent should have write access to long-term memory. Entries follow a defined schema, and in most production systems, new entries are reviewed before becoming permanent. This keeps the knowledge base from silently accumulating garbage that degrades agent behavior over time.
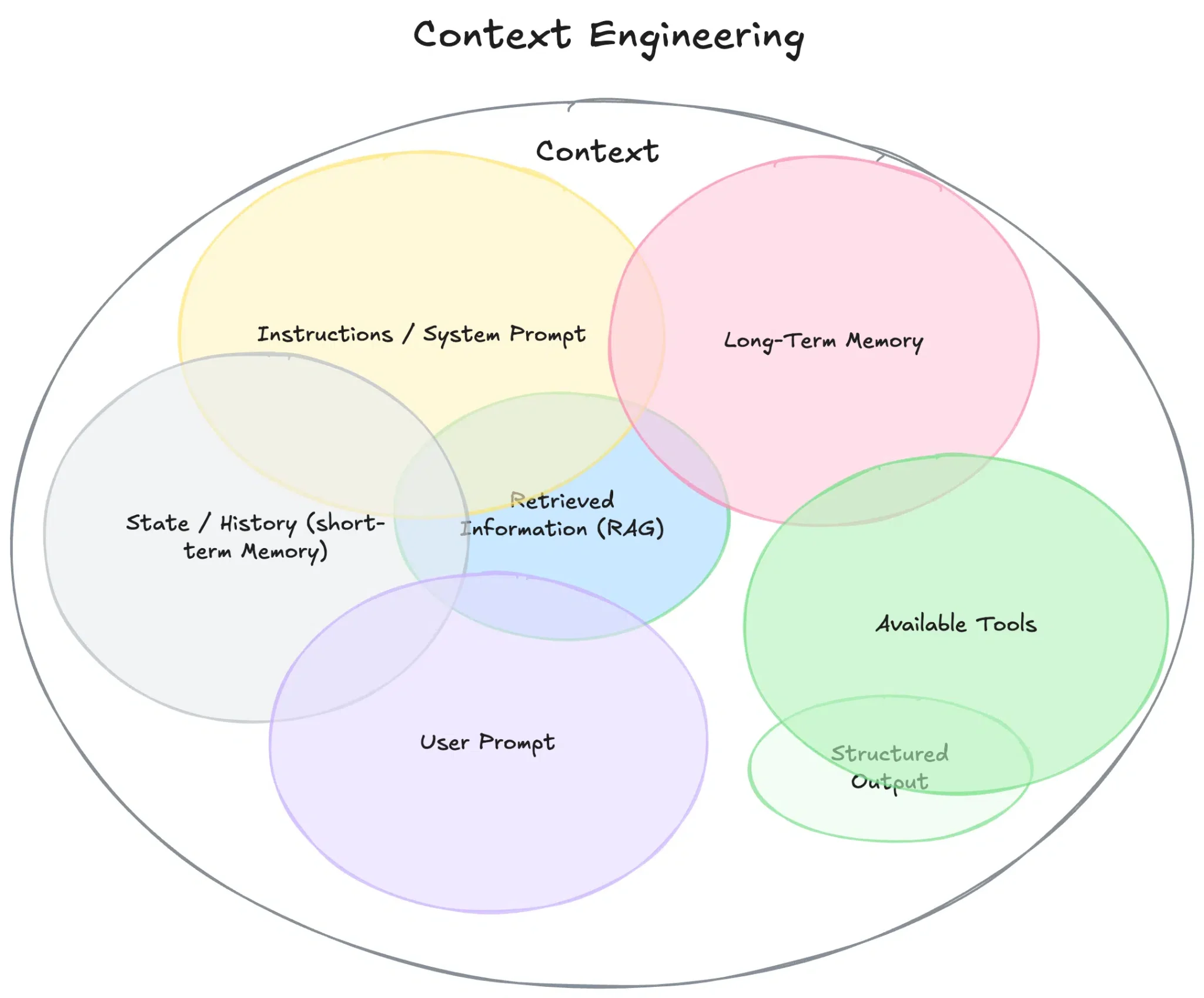
3. Context Management
source: Philschmid
Context windows have hard limits. What you put in them determines the quality of every output.
“Fresh context” means each agent gets a purpose-built context window assembled specifically for its task — not a copy-paste of everything the system has seen so far.
A well-assembled context includes:
A scoped system prompt that defines the agent’s role and constraints for this specific task — not a generic “you are a helpful assistant” prompt
Retrieved memory entries pulled from the relevant memory layers, filtered to the top results most relevant to the current task
Tool definitions for only the tools the agent actually needs to complete its job
Handoff data from the previous agent in the pipeline, structured and clean
What gets deliberately excluded:
Conversation history from other agents’ runs, which introduces noise and causes unexpected behavior
Memory entries from unrelated tasks or past sessions that don’t apply here
Tool definitions for tools the agent won’t use — these take up context space and can confuse the model into attempting actions it shouldn’t
Clean context boundaries make the system predictable and debuggable. When something goes wrong, you know exactly what the agent saw when it made a bad decision — because you controlled what went in.
Instead of one large agent trying to handle everything, an Agentic OS runs a network of agents where each one is purpose-built for a specific type of task.
This is the part that makes the system genuinely scalable. A specialist agent has a tightly scoped system prompt, access to only the tools it needs, and a well-defined output format. It’s easier to build, easier to test, and much easier to fix when it breaks.
Common specialist roles in production systems:
Research agent — queries the web or internal knowledge bases to gather raw information, then structures it into a clean format that downstream agents can actually use
Writer agent — takes a brief and structured inputs and produces a draft, operating within brand or tone guidelines stored in semantic memory
Code agent — writes, reviews, or executes code against a defined spec, and returns structured results including errors and test outputs
QA agent — evaluates another agent’s output against a rubric before it moves to the next step, acting as a quality gate in the pipeline
Tool agent — handles direct integrations like API calls, database queries, and file operations — the parts of the workflow that touch external systems
Memory agent — decides what gets written to long-term memory after a task completes, applying the schema and governance rules that keep the knowledge base clean
Agents communicate through structured interfaces — defined input/output schemas, not free-form conversation. The orchestrator calls a specialist with a structured payload, the specialist returns a structured result, and the orchestrator uses that result to decide what happens next.
For agents to communicate reliably at scale, they need standardized protocols. Agentic AI Communication Protocols: MCP, A2A, and ACP explains how these standards work and why MCP in particular has become the default way agents connect to external tools and services.
This is what makes the whole system composable. You can swap out one specialist, improve another, or add a new one without touching the rest of the pipeline.
5. Feedback Loops and Self-Learning
A static multi-agent pipeline executes the same way every time regardless of whether its outputs are good or bad. A self-learning one gets better.
This doesn’t require retraining the underlying model. Most useful self-improvement happens at the workflow level through feedback loops that are built into the system.
Two types of feedback worth capturing:
Explicit feedback — A human reviews an output and signals whether it was good or bad. This could be a rating, a correction, or an approval/rejection in a review step. Good signals reinforce the current approach. Bad signals trigger a review of the relevant memory entries or system prompts that fed into that output.
Implicit feedback — Behavioral signals the system can observe without anyone rating anything. If a user consistently rewrites the opening of every email the writer agent drafts, that pattern is feedback. If outputs from a particular agent keep getting flagged in the QA step, that’s feedback too. The system captures these signals and surfaces them for review.
The goal is to build feedback collection into the workflow as a first-class feature — not bolt it on later.
How the Components Work Together: A Real Example
Here’s a concrete walkthrough. Say you ask an Agentic OS: “Research our three main competitors and draft a summary report.”
Step 1 — Orchestrator receives the goal and decomposes it: research competitor A, research competitor B, research competitor C, then synthesize everything into a report. It identifies the agents needed and sequences the work.
Step 2 — Context Manager builds a fresh context for each research task. It queries semantic memory for any prior research on these competitors, scopes the system prompt to research-only, and passes only the web search tool to each agent.
Step 3 — Research Agents run in parallel, one per competitor. Each searches, retrieves, and structures its findings into a clean output format that the next stage can consume.
Step 4 — QA Agent reviews each research output against a completeness rubric before anything moves forward. If one output is thin or off-target, it flags it and the orchestrator either retries or routes around it.
Step 5 — Writer Agent receives the validated research from all three agents and drafts the report. It pulls tone and formatting guidelines from semantic memory and structures the output to spec.
Step 6 — Memory Agent stores the final report and key findings in episodic memory so future runs can reference them without starting from scratch.
Step 7 — Feedback Loop kicks in when you read the report. If you edit sections, those changes are logged as implicit feedback on the writer agent’s prompt. If you approve it without changes, that’s a positive signal.
No human stepped in during steps 2–6. The system handled decomposition, coordination, quality checking, and memory management on its own. That’s the pattern in action.
Where Current Implementations Still Break
The Agentic OS pattern is sound. Most real-world implementations are still far from fully realizing it. Here’s where they actually fall apart:
Reliability Agents hallucinate actions, not just text. An agent told to call an API might call the wrong endpoint or construct a malformed request — and do it confidently. According to Gartner, over 40% of ambitious agentic AI pilots are projected to be cancelled by 2027, with reliability failures as the primary cause.
Memory drift Without strict governance on what gets written to shared memory, the knowledge base silently accumulates bad entries. Agents start behaving inconsistently in ways that are hard to trace because the root cause is buried in stale or incorrect memory.
Context bleed When agents share context carelessly — or when the context manager isn’t properly isolating each agent’s input — outputs from one task contaminate another. A support agent that carries over context from a code review run produces outputs that are confused and off-brand in ways that are hard to reproduce and harder to fix.
Infinite loops Agents without well-defined exit conditions can get stuck. The orchestrator keeps replanning, the agent keeps retrying the same failing tool call, and the system burns tokens and time without making progress.
Cost at scale Running multiple specialist agents per task, each making its own LLM call with a carefully assembled context, adds up fast. One way teams address this is by replacing large models with smaller, task-specific ones for routine agent roles — a shift covered in detail in From LLMs to SLMs: Redefining Intelligence in Agentic AI Systems. Production systems also need aggressive context pruning and result caching to stay economically viable at scale.
The Buzzword Test: Is What You’re Looking At Actually an Agentic OS?
The term is being applied to things that don’t deserve it. Before you buy into a platform’s claim or evaluate your own system, ask three questions:
1. Does it have persistent, structured memory across sessions? If the system starts from scratch every time a new session begins, it’s not an Agentic OS. It’s a stateless pipeline with an LLM at the front.
2. Do specialized agents delegate work to each other through defined interfaces? If there’s one model handling every type of task with a single long prompt, that’s not an OS architecture — that’s just a capable model. The multi-agent structure with defined roles and clean handoffs is what makes the pattern work.
3. Does it replan when something fails? If the system halts, throws an error, or requires a human to restart whenever an agent produces a bad output, it’s a workflow tool. An Agentic OS handles failures as a normal operating condition, not an exception.
Build vs. Buy
If you’re deciding whether to build this pattern from scratch or use an existing framework, the tradeoff is straightforward.
Build from scratch if:
Your workflows are specific enough that no framework covers them without significant workarounds
Your security or data requirements mean you can’t route data through external APIs
You have the engineering capacity to maintain a custom orchestration layer long-term
You need to move quickly and don’t want to build memory management and agent routing from scratch
Your use case fits within what existing frameworks support — which covers most common patterns
You want built-in observability and debugging tools without building your own
What no platform decides for you:
How your memory layers are structured and who has write access
What your agent roles are and how they hand off to each other
How feedback signals get captured and acted on
What your failure and replanning logic looks like
The framework handles the plumbing. The architecture — the decisions that actually determine whether your system works — is still yours to design.
FAQ
What’s the difference between an AI agent and an Agentic OS? An agent is a single unit: it receives input, reasons, and produces an output or takes an action. An Agentic OS is the layer above that — it manages multiple agents, decides what each one knows, routes tasks between them, and handles what happens when things go wrong. The agent is the process; the Agentic OS is what runs and coordinates the processes.
Is Agentic OS the same as AGI? No. An Agentic OS is an architectural pattern for organizing AI agents. The agents inside it are still LLM calls with defined roles and scoped context — not general intelligence. The architecture makes them more capable as a system, but each individual agent is still narrow.
What is MCP and why does it matter here? Model Context Protocol (MCP) is an open standard that gives agents a consistent way to connect to external tools and services. Before MCP, every tool integration was custom-built — a different connector for every API. MCP acts like a universal adapter, so agents can call tools without the orchestration layer needing to know the implementation details of each one. For the full picture on MCP and other agent communication standards, see Agentic AI Communication Protocols: MCP, A2A, and ACP.
Can a small team realistically build this? Yes. Frameworks like LangGrap handle most of the infrastructure so you’re not building orchestration from scratch. A small team can get a functional multi-agent system running in weeks. The harder work is designing the memory governance, the agent interfaces, and the failure handling — those require deliberate thought, not just code.
What are the biggest risks when deploying this in production? Three things cause the most problems: agents taking unintended actions with real-world consequences (sending emails, modifying records, making API calls that can’t be undone), memory drift degrading system behavior in ways that are slow and hard to diagnose, and runaway costs from uncontrolled LLM calls across many agents. All three are manageable — but only if you design for them upfront, not after you’re already in production.
The Bottom Line
Agentic OS is a real architectural pattern — not a product, not a marketing term, and not just AI hype.
The core idea is simple: multi-agent systems need a management layer the same way computers need an operating system. Without it, agents are powerful but ungovernable. With it, they become a system you can actually build on, debug, and improve over time.
Most of what’s being sold as “Agentic OS” today doesn’t fully deliver on the pattern yet. The implementations are catching up to the architecture. But the pattern itself — orchestration, structured memory, clean context, specialist agents, feedback loops — is the right foundation for any multi-agent system that needs to work reliably at scale.
If your current agent setup keeps hitting walls, this is the architecture that fixes it.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.