

Transformer models are a type of deep learning model that is used for natural language processing (NLP) tasks. They can learn long-range dependencies between words in a sentence, which makes them very powerful for tasks such as machine translation, text summarization, and question answering.
Transformer models work by first encoding the input sentence into a sequence of vectors. This encoding is done using a self-attention mechanism, which allows the model to learn the relationships between the words in the sentence.
Once the input sentence has been encoded, the model decodes it into a sequence of output tokens. This decoding is also done using a self-attention mechanism.
The attention mechanism is what allows transformer models to learn long-range dependencies between words in a sentence. The attention mechanism works by focusing on the most relevant words in the input sentence when decoding the output tokens.
Learn in detail about transformer models here:

Transformer models are very powerful, but they can be computationally expensive to train. However, they are constantly being improved, and they are becoming more efficient and powerful all the time.
History
The history of transformers in neural networks can be traced back to the early 1990s when Jürgen Schmidhuber proposed the first transformer model. This model was called the “fast weight controller” and it used a self-attention mechanism to learn the relationships between words in a sentence. However, the fast-weight controller was not very efficient, and it was not widely used.
In 2017, Vaswani et al. published the paper “Attention is All You Need”, which introduced a new transformer model that was much more efficient than the fast-weight controller. This new model, which is now simply called the “transformer”, quickly became state-of-the-art for a wide range of natural language efficient (NLP) tasks, including machine translation, text summarization, and question answering.
Learn more about NLP in this blog —-> Applications of Natural Language Processing
The transformer has been so successful because it can learn long-range dependencies between words in a sentence. This is essential for many NLP tasks, as it allows the model to understand the context of a word in a sentence. The transformer does this using a self-attention mechanism, which allows the model to focus on the most relevant words in a sentence when decoding the output tokens.
The transformer has had a major impact on the field of NLP. It is now the go-to approach for many NLP tasks, and it is constantly being improved. In the future, transformers are likely to be used to solve a wider range of NLP tasks, and they will become even more efficient and powerful.
Here are some of the key events in the history of transformers in neural networks:
- 1990: Jürgen Schmidhuber proposes the first transformer model, the “fast weight controller”.
- 2017: Vaswani et al. publish the paper “Attention is All You Need”, which introduces the transformer model.
- 2018: Transformer models achieve state-of-the-art results on a wide range of NLP tasks, including machine translation, text summarization, and question answering.
- 2019: Transformers are used to create large language models (LLMs) such as BERT and GPT-2.
- 2020: LLMs are used to create even more powerful models such as GPT-3.
The history of transformers in neural networks is still being written. It is an exciting time to be in the field of NLP, as transformers are making it possible to solve previously intractable problems.
NLP transformer architecture
The transformer model is made up of two main components: an encoder and a decoder. The encoder takes the input sentence as input and produces a sequence of vectors. The decoder then takes these vectors as input and produces the output sentence.
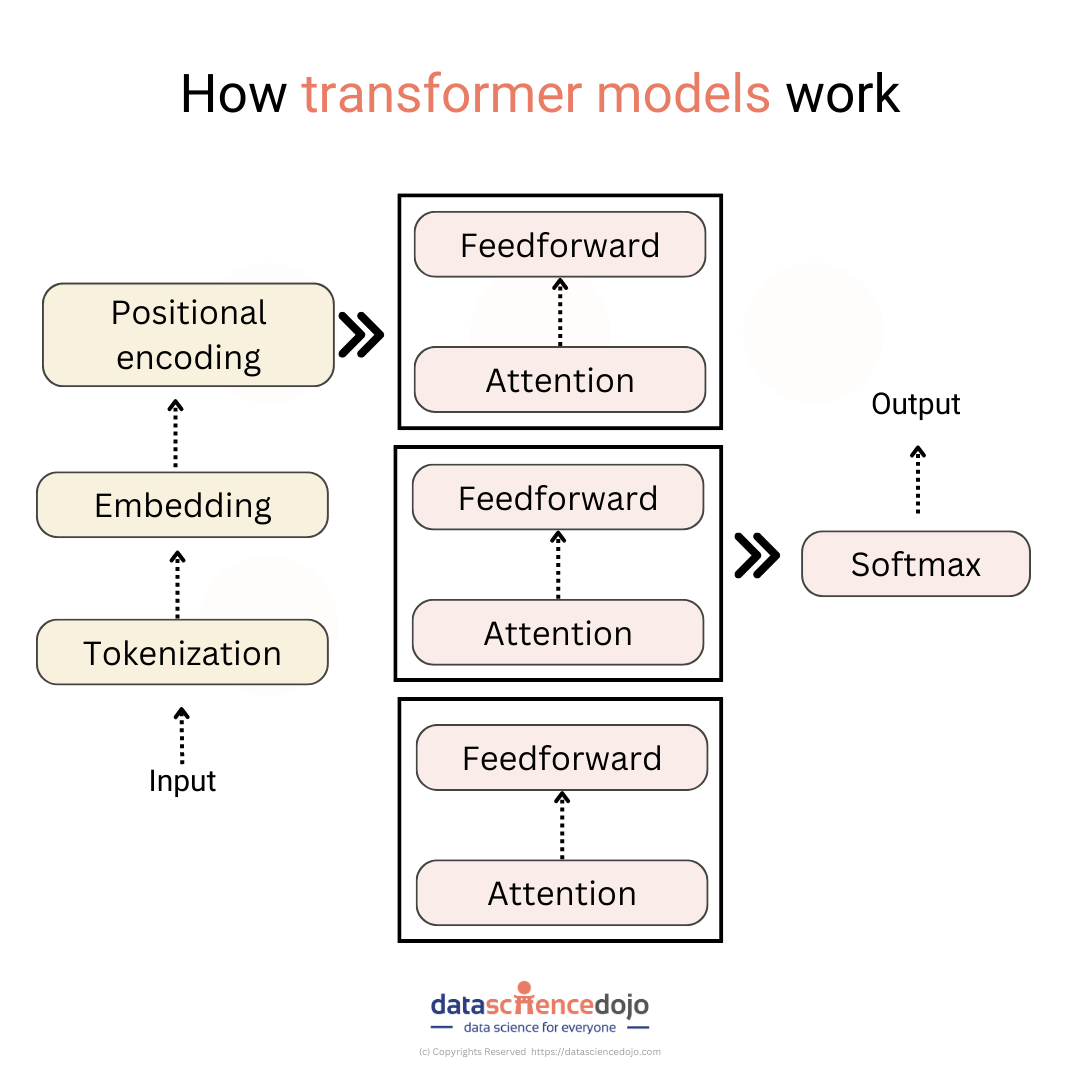
The encoder consists of a stack of self-attention layers. Each self-attention layer takes a sequence of vectors as input and produces a new sequence of vectors. The self-attention layer works by first computing a score for each pair of words in the input sequence. The score for a pair of words is a measure of how related the two words are. The self-attention layer then uses these scores to compute a weighted sum of the input vectors. The weighted sum is the output of the self-attention layer.
The decoder consists of a stack of self-attention layers and a recurrent neural network (RNN). The self-attention layers work the same way as in the encoder. The RNN takes the output of the self-attention layers as input and produces a sequence of output tokens. The output tokens are the words in the output sentence.
The attention mechanism is what allows the transformer model to learn long-range dependencies between words in a sentence. The attention mechanism works by focusing on the most relevant words in the input sentence when decoding the output tokens.
For example, let’s say we want to translate the sentence “I love you” from English to Spanish. The transformer model would first encode the sentence into a sequence of vectors. Then, the model would decode the vectors into a sequence of Spanish words. The attention mechanism would allow the model to focus on the words “I” and “you” in the English sentence when decoding the Spanish words “te amo”.
Transformer models are a powerful tool for NLP, and they are constantly being improved. They are now the go-to approach for many NLP tasks, and they are constantly being improved.

Encoding and Decoding
Encoding and decoding are two key concepts in natural language processing (NLP). Encoding is the process of converting a sequence of words into a sequence of vectors. Decoding is the process of converting a sequence of vectors back into a sequence of words.
Encoding
The encoder in a transformer model takes a sequence of words as input and produces a sequence of vectors. The encoder consists of a stack of self-attention layers. Each self-attention layer takes a sequence of vectors as input and produces a new sequence of vectors. The self-attention layer works by first computing a score for each pair of words in the input sequence. The score for a pair of words is a measure of how related the two words are. The self-attention layer then uses these scores to compute a weighted sum of the input vectors. The weighted sum is the output of the self-attention layer.
For example, let’s say we have the sentence “I like you”. The encoder would first compute a score for each pair of words in the sentence. The score for the word “I” and the word “like” would be high, because these words are related. The score for the word “like” and the word “you” would also be high, for the same reason. The encoder would then use these scores to compute a weighted sum of the input vectors. The weighted sum would be a vector that represents the meaning of the sentence “I like you”.
Decoding
The decoder in a transformer model takes a sequence of vectors as input and produces a sequence of words. The decoder also consists of a stack of self-attention layers. The self-attention layers work the same way as in the encoder. The decoder also has an RNN, which takes the output of the self-attention layers as input and produces a sequence of output tokens. The output tokens are the words in the output sentence.
For example, let’s say we want to translate the sentence “I love you” from English to Spanish. The decoder would first take the vector that represents the meaning of the sentence “I love you” as input. Then, the decoder would use the self-attention layers to compute a weighted sum of the input vectors. The weighted sum would be a vector that represents the meaning of the sentence “I love you” in Spanish. The decoder would then use the RNN to produce a sequence of Spanish words. The output of the RNN would be the Spanish sentence “Te amo”
Encoder only models
Encoder-only models are a type of transformer model that only has an encoder. Encoder-only models are typically used for tasks like text classification, where the model only needs to understand the meaning of the input text.
For example, an encoder-only model could be used to classify a news article as either “positive” or “negative”. The encoder would first encode the article into a sequence of vectors. Then, the model would use a classifier to classify the article.
Encoder-only models are typically less powerful than full transformer models, but they are much faster and easier to train. This makes them a good choice for tasks where speed and efficiency are more important than accuracy.
Decoder only models
Decoder-only models are a type of transformer model that only has a decoder. Decoder-only models are typically used for tasks like machine translation, where the model needs to generate the output text.
For example, a decoder-only model could be used to translate a sentence from English to Spanish. The decoder would first take the English sentence as input. Then, the decoder would use the self-attention layers to compute a weighted sum of the input vectors. The weighted sum would be a vector that represents the meaning of the sentence in Spanish. The decoder would then use an RNN to produce a sequence of Spanish words. The output of the RNN would be the Spanish sentence.
Decoder-only models are typically less powerful than full transformer models, but they are much faster and easier to train. This makes them a good choice for tasks where speed and efficiency are more important than accuracy.
Here is a table that summarizes the differences between encoder-only models and decoder-only models:

What are transformer models built of
Transformer models are built of the following components:
- Embedding layer: The embedding layer converts the input text into a sequence of vectors. The vectors represent the meaning of the words in the text.
- Self-attention layers: The self-attention layers allow the model to learn long-range dependencies between words in a sentence. The self-attention layers work by computing a score for each pair of words in the sentence. The score for a pair of words is a measure of how related the two words are. The self-attention layers then use these scores to compute a weighted sum of the input vectors. The weighted sum is the output of the self-attention layer.
- Positional encoding: The positional encoding layer adds information about the position of each word in the sentence. This is important for learning long-range dependencies, as it allows the model to know which words are close to each other in the sentence.
- Decoder: The decoder takes the output of the self-attention layers as input and produces a sequence of output tokens. The output tokens are the words in the output sentence.
Transformer models are also typically trained with the following techniques:
- Masked language modeling: Masked language modeling is a technique used to train transformer models to predict the missing words in a sentence. This helps the model to learn to attend to the most relevant words in a sentence.
- Attention masking: Attention masking is a technique used to prevent the model from attending to future words in a sentence. This is important for preventing the model from learning circular dependencies.
- Gradient clipping: Gradient clipping is a technique used to prevent the gradients from becoming too large. This helps to stabilize the training process and prevent the model from overfitting.
Attention layers are a type of neural network layer that allows the model to learn long-range dependencies between words in a sentence. The attention layer works by computing a score for each pair of words in the sentence. The score for a pair of words is a measure of how related the two words are. The attention layer then uses these scores to compute a weighted sum of the input vectors. The weighted sum is the output of the attention layer.
The input to the attention layer is a sequence of vectors. The output of the attention layer is a weighted sum of the input vectors. The weights are computed using the scores for each pair of words in the sentence.
The attention layer can learn long-range dependencies because it allows the model to attend to any word in the sentence, regardless of its position. This is in contrast to recurrent neural networks (RNNs), which can only attend to words that are close to the current word.
Transformer architecture is a neural network architecture that is based on attention layers. Transformer models are typically made up of an encoder and a decoder. The encoder takes the input text as input and produces a sequence of vectors. The decoder takes the output of the encoder as input and produces a sequence of output tokens.
The encoder consists of a stack of self-attention layers. The decoder also consists of a stack of self-attention layers. The self-attention layers in the decoder can attend to both the input text and the output text. This allows the decoder to generate the output text in a way that is consistent with the input text.
Transformer models are typically trained with the masked language modeling technique. Masked language modeling is a technique used to train transformer models to predict the missing words in a sentence. This helps the model to learn to attend to the most relevant words in a sentence.
Tackle transformer model challenges
- Computational complexity: Transformer models are very computationally expensive to train and deploy. This is because they require a large number of parameters and a lot of data. To tackle this challenge, researchers are developing new techniques to make transformer models more efficient.
- Data requirements: Transformer models require a large amount of data to train. This is because they need to learn the relationships between words in a sentence. To tackle this challenge, researchers are developing new techniques to pre-train transformer models on large datasets.
- Interpretability: Transformer models are not as interpretable as other machine learning models, such as decision trees and logistic regression. This makes it difficult to understand why the model makes the predictions that it does. To tackle this challenge, researchers are developing new techniques to make transformer models more interpretable.
Here are some specific techniques that have been developed to tackle the challenges of transformer models:
- Knowledge distillation: Knowledge distillation is a technique that can be used to train a smaller, more efficient transformer model by distilling the knowledge from a larger, more complex transformer model.
- Data augmentation: Data augmentation is a technique that can be used to increase the size of a dataset by creating new data points from existing data points. This can help to improve the performance of transformer models on small datasets.
- Attention masking: Attention masking is a technique that can be used to prevent the transformer model from attending to future words in a sentence. This helps to prevent the model from learning circular dependencies.
- Gradient clipping: Gradient clipping is a technique that can be used to prevent the gradients from becoming too large. This helps to stabilize the training process and prevent the model from overfitting.