An LLM wiki is a structured, AI-maintained knowledge base that grows smarter every time you add a source — unlike RAG, which rediscovers knowledge from scratch on every query.
The pattern was introduced by Andrej Karpathy in a GitHub Gist in April 2026 and went viral among developers within days.
You can build your first LLM wiki in under 30 minutes using five free research papers, a folder on your computer, and Claude Code or Claude.ai
If you have ever uploaded a PDF to ChatGPT, asked a question, and then uploaded the same PDF again the next day to ask a follow-up.. you already understand the problem an LLM wiki solves.
Most AI knowledge tools today are stateless. Every session starts from zero. Nothing you learn in one conversation carries over to the next. The model retrieves, answers, and forgets. Ask the same question tomorrow and it rebuilds the answer from scratch.
Andrej Karpathy, co-founder of OpenAI and former Director of AI at Tesla, proposed a different approach in April 2026. He called it an LLM wiki: a persistent, structured knowledge base that an AI agent actively builds and maintains, so that knowledge compounds over time instead of evaporating between sessions.
This tutorial walks you through exactly how to build one, using five foundational AI research papers as your starting material.
LLM Wiki By Andrej Karpathy
What Is an LLM Wiki and Why Does It Matter?
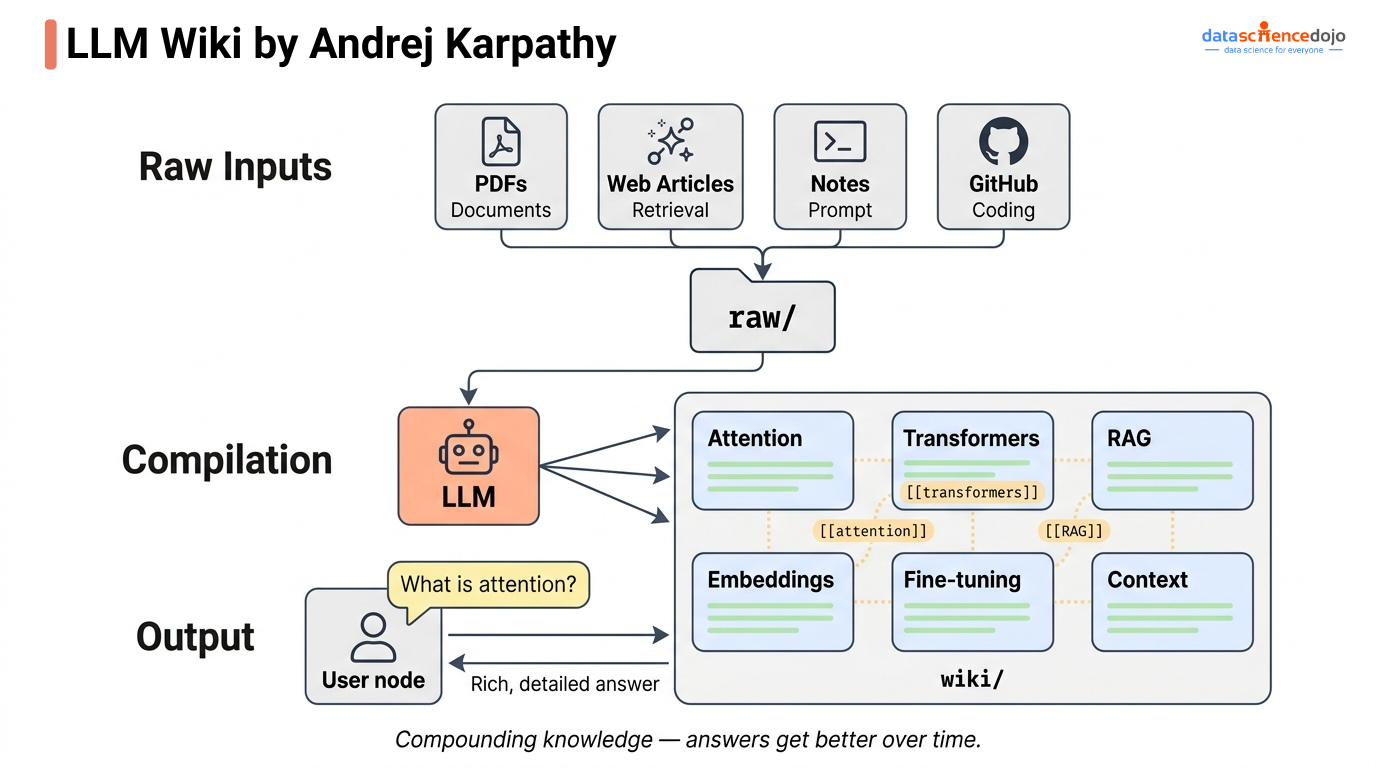
An LLM wiki is a folder of plain markdown files that an AI agent reads, writes, and maintains on your behalf. Each file is an entity page: a structured, Wikipedia-style entry for one concept, linked to related concepts using [[wiki-links]].
The key difference from every other knowledge tool is what happens when you add a new source.
In a standard RAG system (NotebookLM, ChatGPT file uploads, most enterprise tools), adding a new document means it gets indexed and sits alongside your other documents. When you ask a question, the system retrieves relevant chunks and generates an answer. The documents themselves never change. Nothing is synthesized. Nothing is connected.
In an LLM wiki, adding a new document triggers a compilation step. The agent reads the new source and the existing wiki, then:
Updates existing pages with new information
Creates new entity pages for concepts that appear for the first time
Adds [[wiki-links]] connecting the new concept to related ones already in the wiki
Flags contradictions between the new source and what was previously written
Over time, the wiki becomes a connected knowledge graph, not just a pile of documents. At 10 pages it answers basic questions. At 50 pages it starts synthesizing across ideas you never explicitly connected. At 100+ pages, it can answer questions where the answer doesn’t exist in any single source, because the answer lives in the relationships between pages.
The tradeoff worth knowing: RAG is better when your data changes daily or when exact source traceability matters for every claim. LLM wiki is better when you are building expertise on a topic over weeks or months, and want the model to reason across your knowledge base rather than just retrieve from it.
What You Need Before You Start
Tools:
A computer with a folder you can access (Mac, Windows, or Linux)
Claude.ai account (free tier works for the tutorial) or Claude Code if you prefer the terminal
Obsidian: free markdown editor (optional but recommended for the graph view)
5 research papers downloaded as PDFs (links in the next section)
Knowledge assumed:
You know how to create a folder on your computer
You know how to download a file from a URL
No coding required for the Claude.ai version of this tutorial
Estimated time: 25–35 minutes for your first wiki
Step 1: Download Your Starting Papers
For this tutorial, we are using five foundational AI research papers. They are ideal because they build on each other sequentially — the LLM will naturally create rich connections between concepts like attention, fine-tuning, scaling, and alignment.
All five are free on arXiv. Download each as a PDF and save them somewhere easy to find.
Paper 2: BERT (2018) Bidirectional transformers for language understanding — builds directly on attention.
Paper 3: GPT-3 (2020) Large language models as few-shot learners — introduces emergent capabilities at scale.
Paper 4: Foundation Models (2021) A broad survey tying together transformers, scaling, and downstream applications.
Paper 5: RLHF (2022) How GPT models are aligned using human feedback — the bridge to modern assistants.
Research Papers added to /raw Folder
After this step you should have: Five PDF files saved to your computer.
Step 2: Create Your Folder Structure
Create a new folder anywhere on your computer — your Desktop, Documents, wherever makes sense. Name it my-wiki.
Inside it, create two folders:
my-wiki/
├── raw/
└── wiki/
raw/ is where you drop all your source files — PDFs, articles, notes. You never edit anything in here manually.
wiki/ is where the compiled entity pages live. The LLM writes here.
Now move your five downloaded PDFs into the raw/ folder.
LLM wiki folder structure with raw and wiki directories
After this step you should have: A folder structure with five PDFs sitting inside raw/.
Step 3: Run the Compilation Prompt
This is the core step, where the LLM wiki pattern actually kicks in.
Option A: Using Claude.ai (no terminal needed)
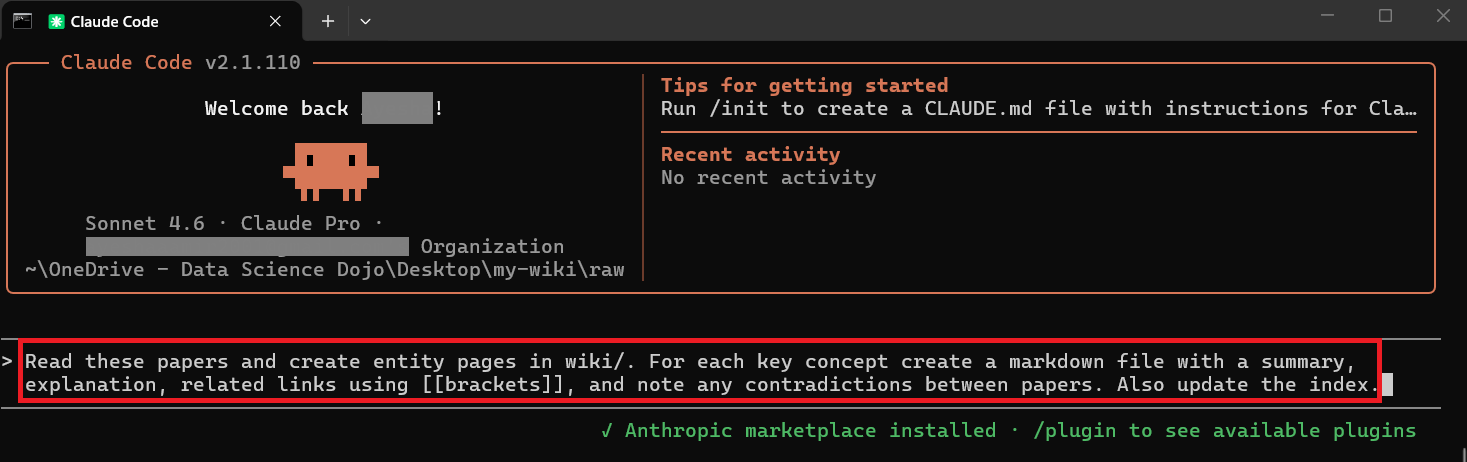
Open Claude.ai and upload all five PDFs at once using the attachment button. Then send this prompt:
That is genuinely all you need. Claude will generate one markdown entity page per key concept — each with a summary, an explanation, wiki-links to related concepts, and any contradictions it finds between the papers.
Copy each page into a .md file in your wiki/ folder.
Additionally: If you want more structure as your wiki grows, you can extend the prompt to also ask Claude to create an index.md listing every entity page with a one-line description, and a log.md tracking what was compiled and when. These become useful navigational tools once you have 30+ pages, but they are not needed to get started.
Option B: Using Claude Code (terminal)
If you have Claude Code installed, open a terminal, navigate to your wiki folder, and launch it:
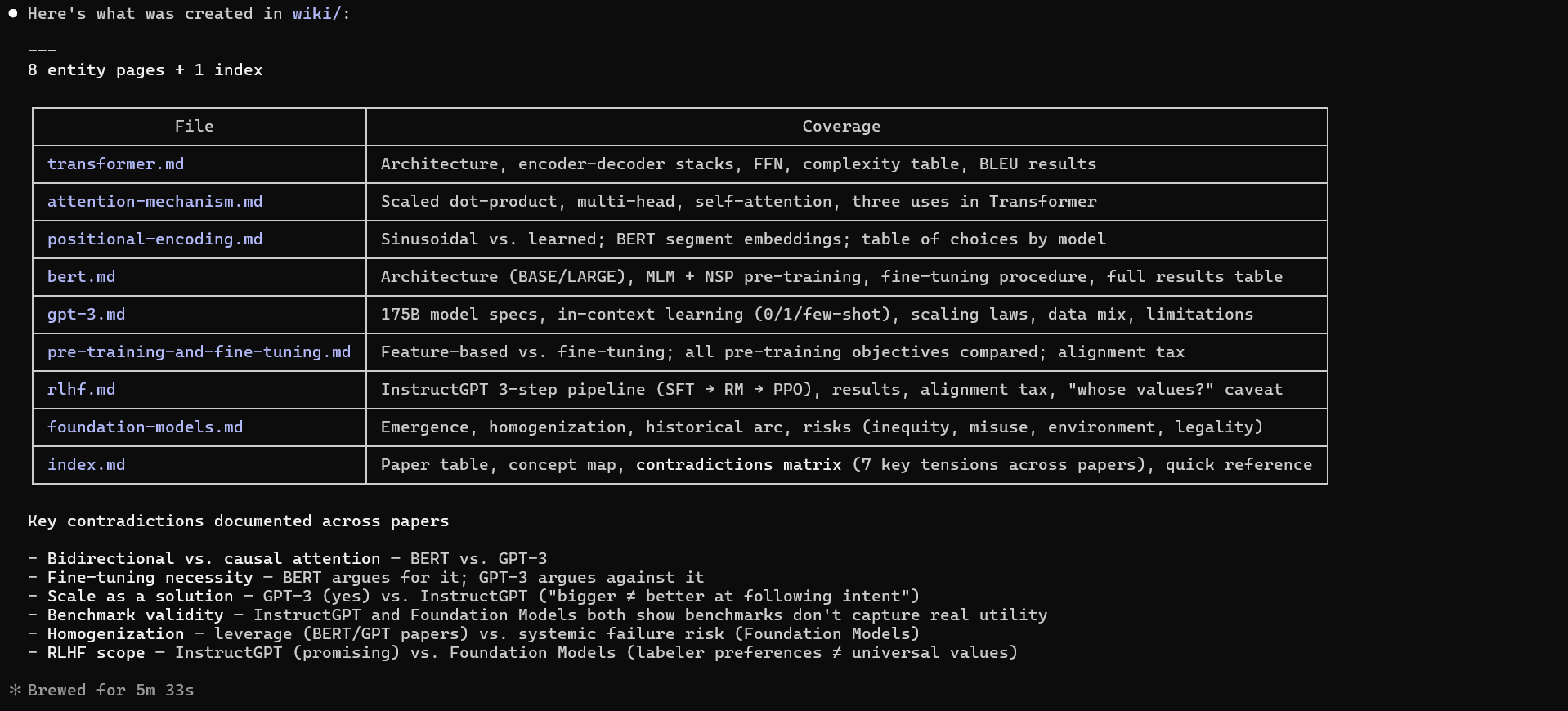
Then paste the same prompt above. Claude Code will read the files directly and write the pages into wiki/ for you — no copy-pasting needed.
Claude Code prompt for creating LLM wikiEntity pages created for LLM Wiki by Claude Code
After this step you should have: 10–20 markdown entity pages in your wiki/ folder.
Step 4: Open Your Wiki in Obsidian
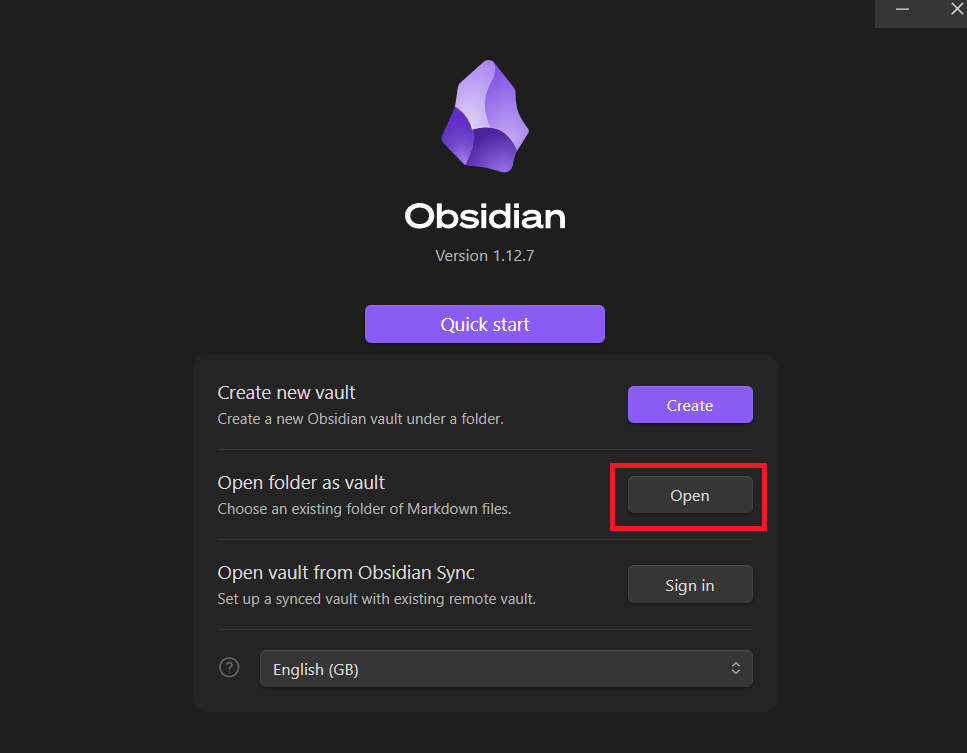
Install Obsidian (free, no account needed). When it launches, click Open folder as vault and select your wiki/ folder.
Using Obsidian to create graphs for LLM Wiki
Two things to look at immediately:
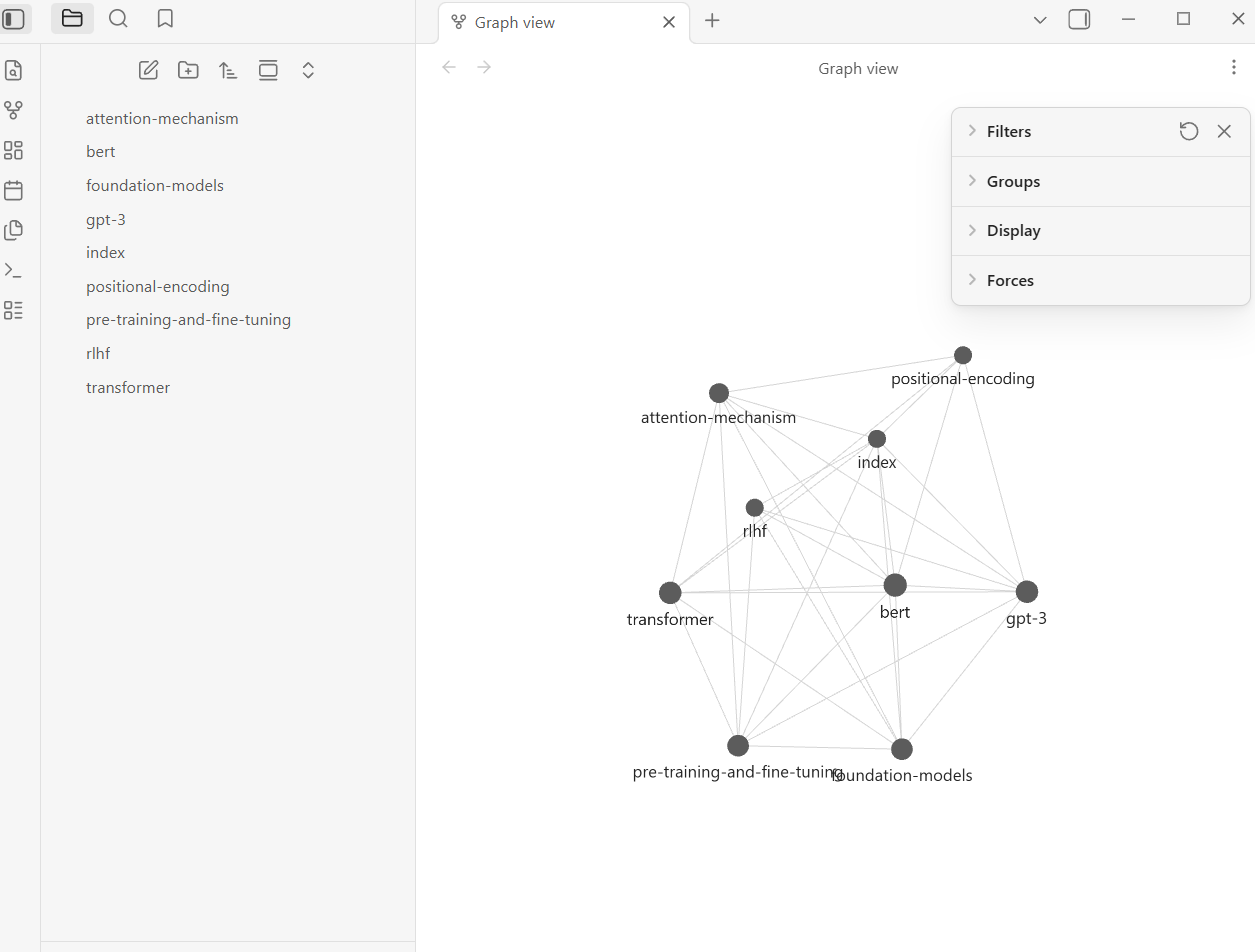
Graph View — press Ctrl+G (or Cmd+G on Mac). You will see your entity pages as nodes, with [[wiki-links]] rendered as edges connecting them. After just five papers, you should see a small but meaningful graph — transformer architecture linking to attention mechanism, BERT linking to fine-tuning, RLHF linking to alignment and GPT.
Obsidian graph view of an LLM wiki showing linked entity pages on transformer concepts
After this step you should have: A visual, navigable knowledge graph in Obsidian.
Step 5: Add More Sources and Watch It Compound
Drop a new paper into raw/, any paper related to transformers, language models, or AI alignment works well. Then run the compilation prompt again, this time with a small addition:
This is where the compound effect becomes visible. The new paper does not just create new pages, it enriches the pages already there. A page on “attention mechanism” that had two outgoing links might now have five. A claim that went unchallenged might now have a contradiction flagged.
Every time your wiki reaches roughly 20 new pages, run this maintenance prompt:
This is the self-healing step. It is what keeps the wiki accurate as it grows, rather than slowly drifting into quiet inconsistency.
Tip: “Run linting after every 20 new pages, or any time you add a source that significantly updates a topic already in the wiki.”
After this step you should have: A clean, internally consistent wiki with no orphan pages and all flagged contradictions resolved or noted.
Common Mistakes to Avoid
Putting too much in one page. Each entity page should cover exactly one concept. If a page starts covering two ideas, split it. Dense single-concept pages create better links and better answers.
Never running linting. Small errors propagate fast in a wiki. A wrong claim on one page gets linked to by three others, and now you have organized misinformation. Run the audit pass regularly.
Adding too many unrelated topics at once. The wiki compounds best when sources are topically related. Starting with five papers on the same subject produces a richer graph than five papers on five different subjects.
Frequently Asked Questions
What is an LLM wiki? An LLM wiki is a personal knowledge base made of plain markdown files that an AI agent actively builds and maintains. Unlike RAG systems that search raw documents on every query, an LLM wiki pre-compiles knowledge into structured, interlinked entity pages — so answers compound over time instead of being rediscovered from scratch.
Who created the LLM wiki concept? Andrej Karpathy, co-founder of OpenAI and former Director of AI at Tesla, described the concept in a GitHub Gist published in April 2026. The post went viral in the developer community within days of publication.
Do I need to know how to code to build an LLM wiki? No. The Claude.ai version of this tutorial requires no coding — just uploading PDFs and pasting prompts. Claude Code makes the workflow faster and more automated, but it is not required to get started.
How is an LLM wiki different from Notion or Obsidian alone? Notion and Obsidian are tools for human-written notes — you organize and write everything yourself. An LLM wiki uses those same tools as the viewing interface, but the actual compilation, linking, and maintenance is done by the AI agent. You supply raw sources; the agent builds the structure.
How big can an LLM wiki get? Karpathy’s own wiki reached approximately 100 articles and 400,000 words before he noted that the LLM could still navigate it efficiently using the index and summaries. At that scale, the system was still faster and more accurate than a RAG pipeline for his research use case.
What file types work in the raw/ folder? PDFs work best for research papers. Markdown files work well for articles clipped from the web (the Obsidian Web Clipper browser extension converts any webpage to markdown automatically). Plain text, exported chat conversations, and .md notes all work. The LLM reads whatever you drop in.
What to Build Next
Once your first wiki is running, a few natural next steps:
Add the Obsidian Web Clipper browser extension. It converts any webpage to markdown and saves it directly to your raw/ folder. This makes ingesting articles as fast as bookmarking them.
Try topic-specific wikis. One wiki per research area tends to produce cleaner graphs than one giant wiki. Start a separate one for a new topic rather than mixing everything together.
Fine-tune on your wiki. At 100+ well-maintained pages, the wiki becomes a high-quality training set. You can eventually fine-tune a smaller model on it — turning your personal research into a custom private intelligence.
Ready to build robust and scalable LLM Applications? Explore our LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.