If you’ve spent any time experimenting with large language models (LLMs), you’ve likely encountered terms like queries, keys, and values—the building blocks of transformer attention. Understanding these concepts is the first step toward appreciating a powerful optimization called the KV cache, which is essential for both fast inference and cost efficiency. Today, we’re going to take a deep dive into what KV cache is, why it matters, and how you can optimize your prompts to take full advantage of it. And to take things even further, this post kicks off a 3-part series on modern attention-efficiency techniques. By the end, you’ll not only understand KV cache deeply—you’ll also be ready for the next installments where we break down newer methods like Paged Attention, Radix Attention, and a few emerging ideas reshaping long-context LLMs.
Queries, Keys, and Values: The Building Blocks of Attention
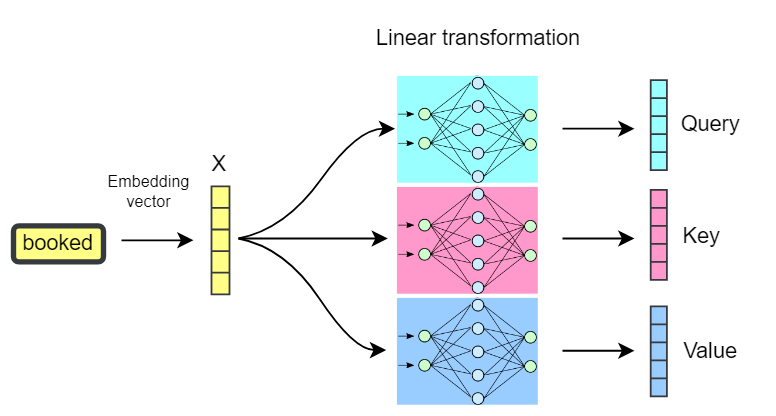
Before we can talk intelligently about KV cache, we need to revisit the basics of attention. In a transformer, every token you feed into the model generates three vectors: Q (query), K (key), and V (value). Each of these plays a distinct role in determining how the model attends to other tokens in the sequence.
Query (Q) represents the token that’s “asking” for information. It’s like a search request, what does this token want to know from the context?
Key (K) represents the token that’s being “indexed.” It’s like the label on a piece of information that queries can match against.
Value (V) represents the content or information of the token itself. Once a query finds a matching key, the corresponding value is returned as part of the output.
source: Medium
Mathematically, attention computes a score between the query and all keys using a dot product, applies a softmax to turn scores into weights, and then calculates a weighted sum of the values. This weighted sum becomes the output representation for that token. Step by step, it looks like this:
Compute for all tokens X.
Compute attention scores:
Apply softmax to get attention weights:>
Compute the weighted sum of values:
source: Medium
It’s elegant, but there’s a catch: during inference, the model repeats this process for every new token in an autoregressive manner, which can become extremely costly, especially for long sequences.
Here’s where the KV cache comes into play. When generating text token by token, the model recalculates keys and values for all previous tokens at each step. This repetition is wasteful because those previous K and V vectors don’t change; only the query for the new token is different. The KV cache solves this by storing K and V vectors for all previous tokens, allowing the model to reuse them instead of recomputing them.
Think of it this way: if you’re reading a long document and want to summarize it sentence by sentence, you wouldn’t reread the first paragraphs every time you process the next sentence. KV cache lets the model “remember” what it already processed.
To appreciate the value of KV cache, it’s worth considering how it affects cost in practice. Many commercial LLM providers charge differently for tokens based on whether they hit the cache:
With Anthropic Claude, cached input tokens are far cheaper than uncached tokens. Cached tokens can cost as little as $0.30 per million tokens, whereas uncached tokens can cost up to $3 per million tokens—a 10x difference.
Similarly, in OpenAI’s GPT models, repeated prefixes in multi-turn chats benefit from KV caching, drastically reducing both time-to-first-token (TTFT) and inference costs.
This cost gap alone makes KV cache a critical optimization for anyone building production systems or agentic AI pipelines.
Today, many applications are more than simple Q&A models, they’re agentic systems performing multiple steps of reasoning, tool usage, and observations. Consider an AI agent orchestrating a series of actions:
The agent receives a system prompt describing its objectives.
It ingests a user prompt.
It generates an output, executes actions, observes results, and logs observations.
The agent generates the next action based on all prior context.
In such multi-turn workflows, KV cache hit rate is extremely important. Every token in the prefix that can be reused reduces the compute needed for subsequent reasoning steps. Without caching, the model recalculates K/V for all past tokens at each step—wasting time, compute, and money.
Fortunately, if your context uses identical prefixes, you can take full advantage of KV cache. Whether you’re running a self-hosted model or calling an inference API, caching drastically reduces TTFT and inference costs.
Maximizing KV cache hit rate isn’t magic, it’s about structured, deterministic prompting. The team at Manus highlights several practical strategies for real-world AI agents in their blog “Context Engineering for AI Agents: Lessons from Building Manus” (Manus, 2025).
Here’s a summary of the key recommendations:
Keep your prompt prefix stable
Due to the autoregressive nature of LLMs, even a single-token difference can invalidate the KV cache from that point onward. A common example is including a timestamp at the beginning of the system prompt: while it allows the model to tell the current time, it completely kills cache reuse. Manus emphasizes that stable system prompts are critical for cache efficiency.
Make your context append-only
Avoid modifying previous actions or observations. Many programming languages and serialization libraries do not guarantee stable key ordering, which can silently break the cache if JSON objects or other structured data are rewritten. Manus recommends designing your agent’s context so that all new information is appended, leaving previous entries untouched.
Mark cache breakpoints explicitly
Some inference frameworks do not support automatic incremental prefix caching. In these cases, you need to manually insert cache breakpoints to control which portions of context are reused. Manus notes that these breakpoints should at minimum include the end of the system prompt and account for potential cache expiration.
By following these structured prompting strategies, you maximize KV cache reuse, which leads to faster inference, lower costs, and more efficient multi-turn agent execution—lessons that the Manus team has validated through real-world deployments.
The Basics of LLM Inference: Prefill and Decoding
To understand why prompt caching (KV caching) is such a game-changer, it helps to first see what happens under the hood during LLM inference. Large language models generate text in two distinct phases:
1. Prefill – Understanding the Prompt
In this phase, the model processes the entire input prompt all at once. Each token in the prompt is converted into embeddings, and the model computes hidden states and attention representations across all tokens. These computations allow the model to “understand” the context and produce the first output token. Essentially, the prefill phase is the model setting the stage for generation.
2. Decoding – Generating Tokens Autoregressively
Once the first token is generated, the model enters the decoding phase. Here, it generates one token at a time, using all previous tokens (both the input prompt and already-generated tokens) as context. Each new token depends on the history of what’s been produced so far.
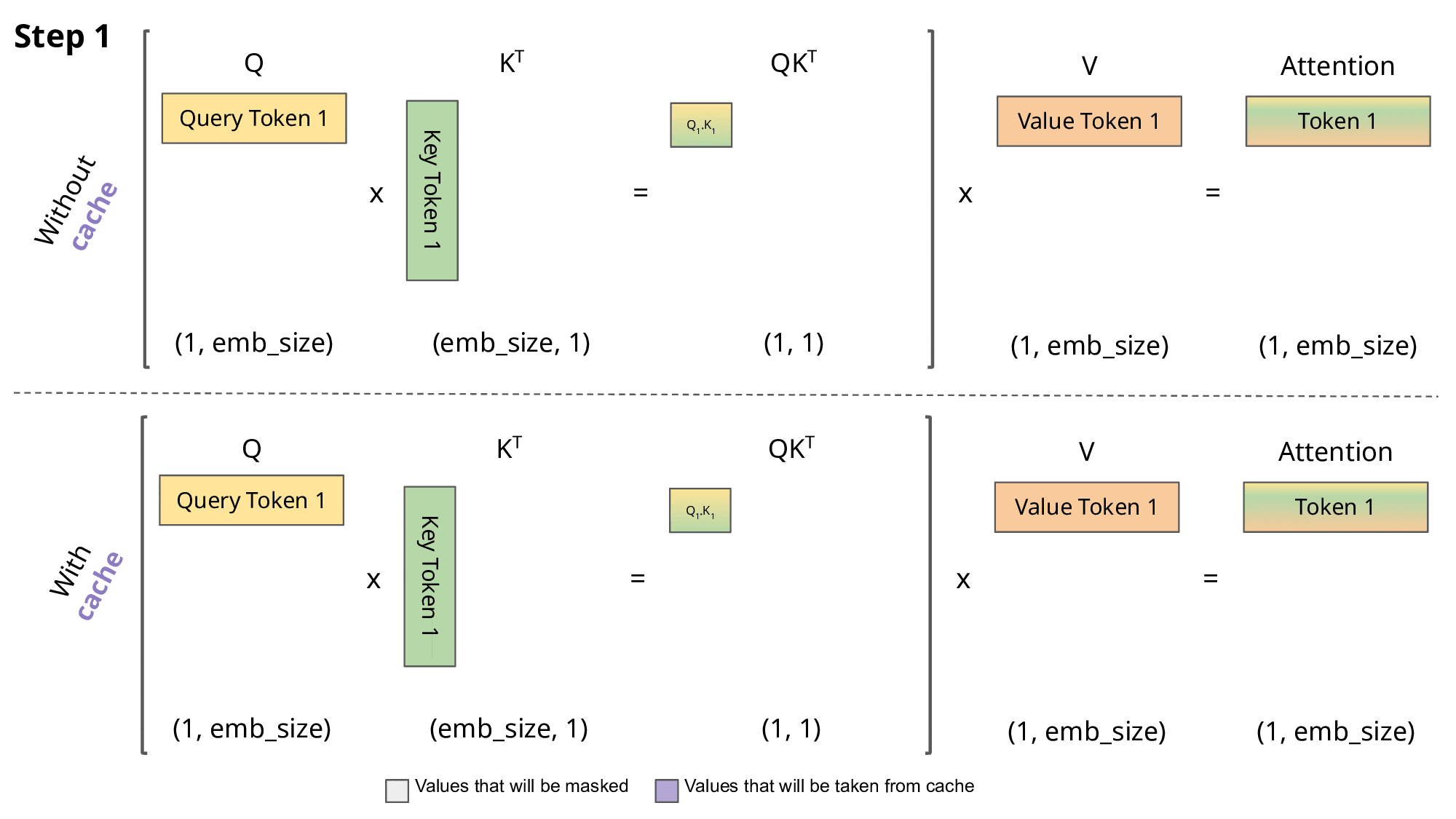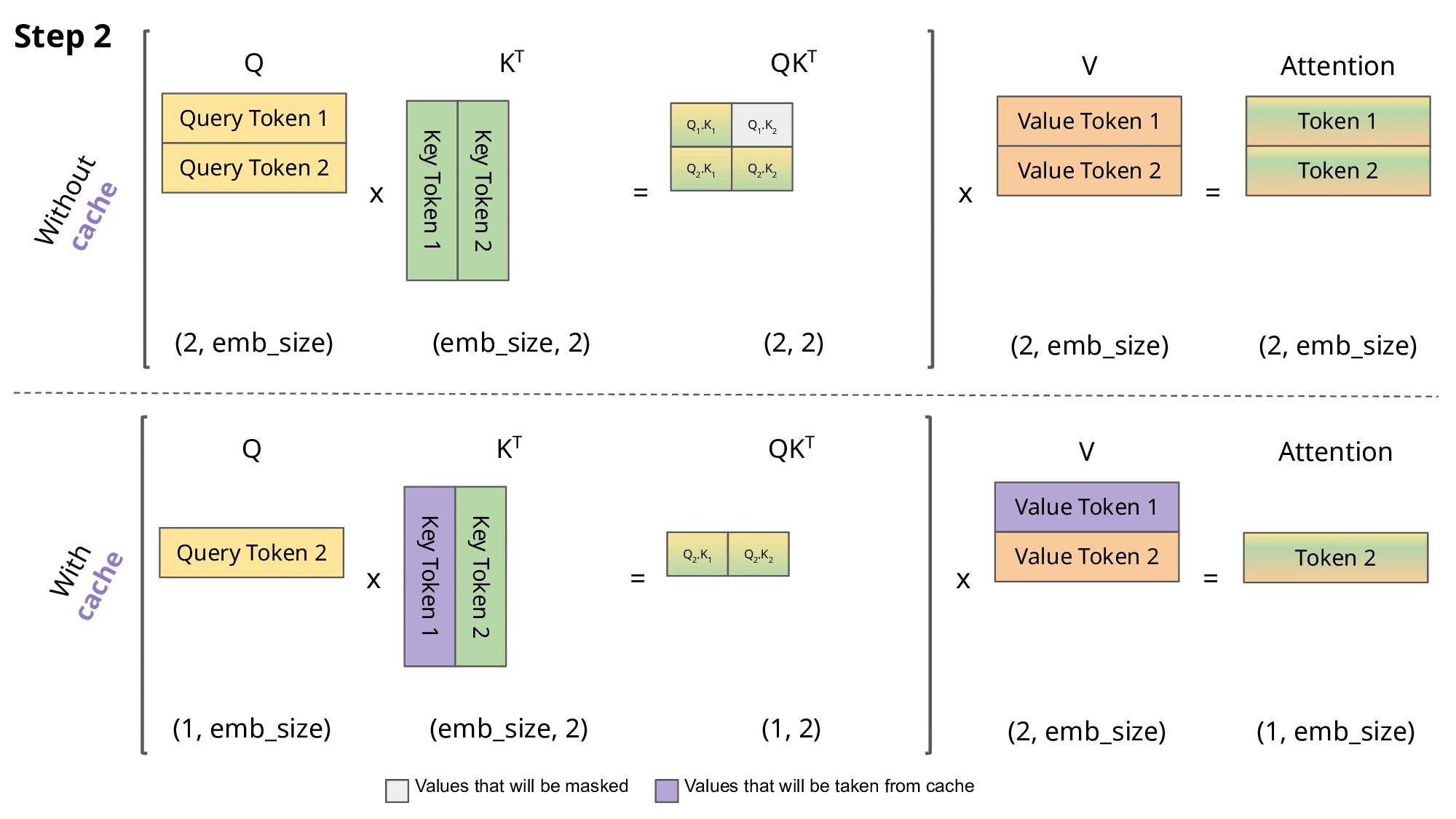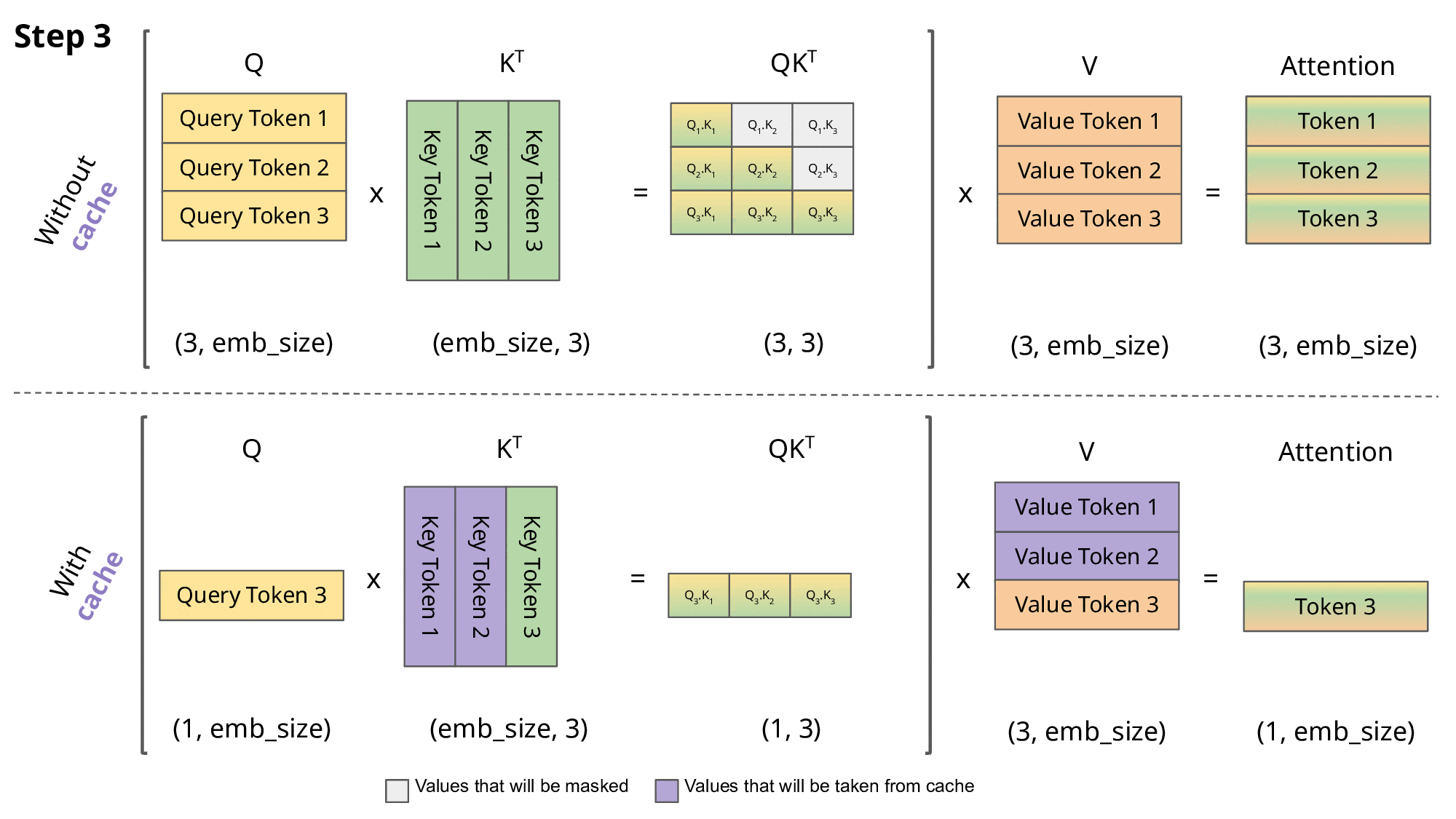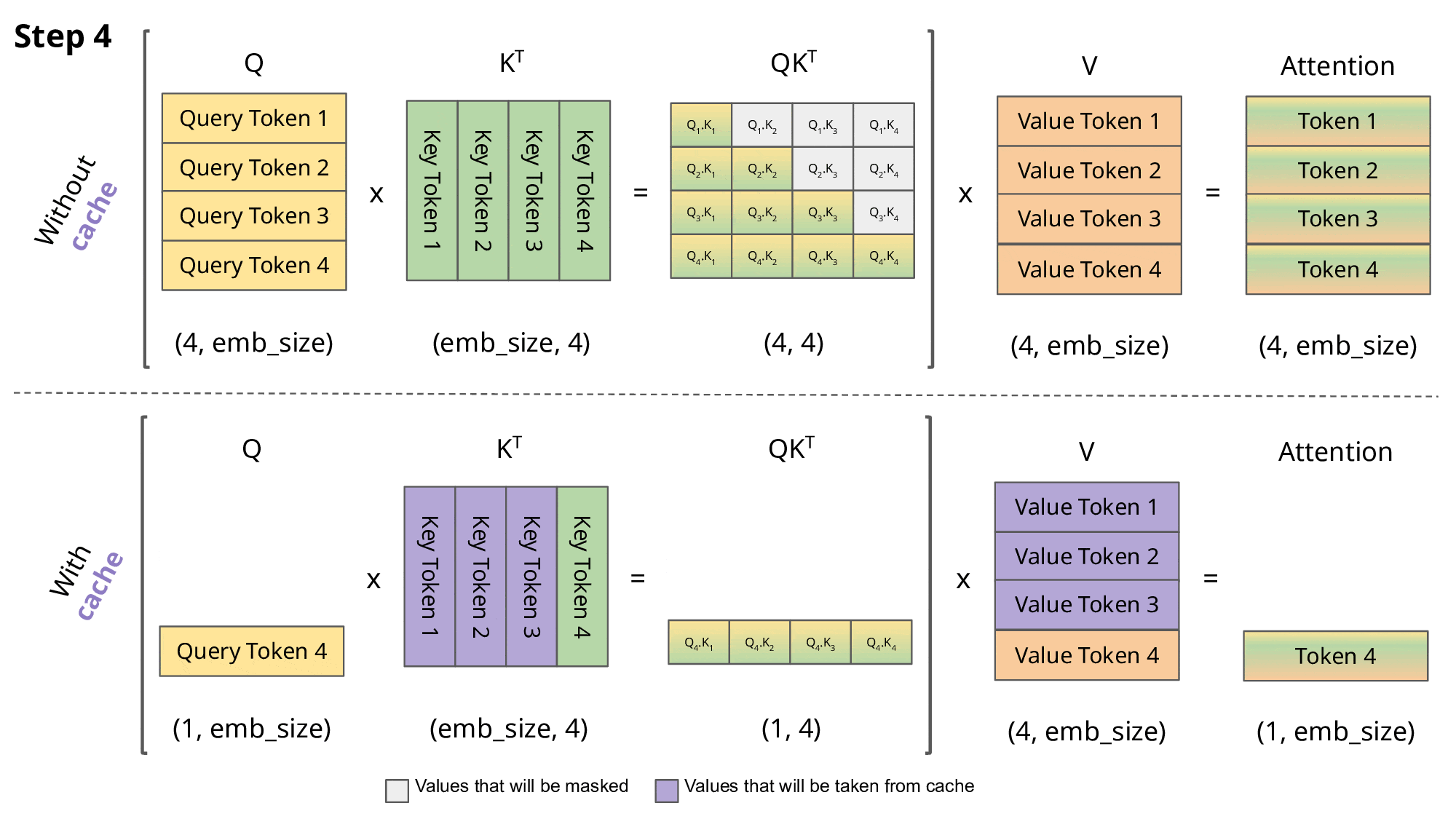
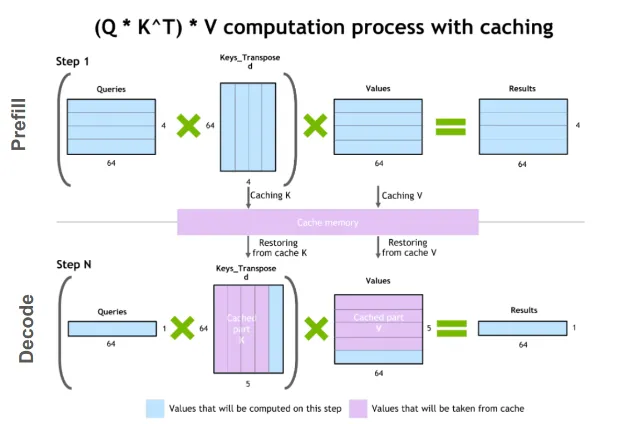
Step-by-Step Example: QKV Computation Without KV Cache
Suppose you have the tokens:
[Alice, went, to, the, market]
At token 5 (“market”), without KV cache:
Compute Q, K, V for “Alice” → store temporarily
Compute Q, K, V for “went”
Compute Q, K, V for “to”
Compute Q, K, V for “the”
Compute Q for “market” and recompute K, V for all previous tokens
Notice that K and V for the first four tokens are recomputed unnecessarily.
Step-by-Step Example: With KV Cache
With KV cache:
Compute Q, K, V for each token as before once and store K and V
While KV cache provides significant improvements, it’s not perfect:
Memory growth: K/V tensors grow linearly with context length. Long sequences can exhaust GPU memory.
Static cache structure: Simple caching doesn’t handle sliding windows or context truncation efficiently.
Inflexibility with multi-query attention: Models using multi-query attention can reduce KV memory but may require different caching strategies.
These limitations have driven research into more advanced attention techniques.
Beyond Simple KV Cache: Advanced Techniques
As models scale to longer contexts, the simple KV cache runs into practical limits—mainly GPU memory and the cost of attending to every past token. That’s why newer techniques like Paged Attention and Radix Attention were developed. They’re not replacements for KV caching but smarter ways of organizing and accessing cached tokens so the model stays fast even with huge context windows. We’ll break down each of these techniques in the upcoming blogs, so stay tuned for that.
1. Paged Attention
Paged attention divides the model’s context into discrete “pages” of tokens, similar to how a computer manages memory with virtual pages. Instead of keeping every token in GPU memory, only the pages relevant to the current generation step are actively loaded.
Memory efficiency: Older pages that are less likely to impact the immediate token prediction can be offloaded to slower storage (like CPU RAM or even disk) or recomputed on demand.
Scalability: This allows models to process very long sequences—think entire books or multi-hour dialogues—without exceeding memory limits.
Practical example: Imagine a multi-turn chatbot with a 20,000-token conversation history. With naive caching, the GPU memory would balloon as each new token is generated. With paged attention, only the most relevant pages (e.g., the last few turns plus critical context) remain in memory, while earlier parts are swapped out. The model still has access to the full history if needed but doesn’t carry the entire context in GPU memory at all times.
2. Radix Attention
Radix attention takes a fundamentally different approach: it reorganizes tokens hierarchically into a radix-tree structure. Rather than attending to every single token individually, the model computes attention over grouped summaries of tokens.
Logarithmic scaling: By aggregating keys and values in a tree, the number of attention computations grows logarithmically with sequence length, rather than linearly. This dramatically reduces computational cost for extremely long sequences.
Preserving context fidelity: Unlike simple downsampling, radix attention preserves critical information by hierarchically combining tokens, ensuring that higher-level representations still capture the essence of earlier tokens.
Ideal for agentic workflows: In systems where models must maintain reasoning across long interactions—such as multi-step planning agents or memory-augmented AI—radix attention ensures that even very old information can influence current decisions without slowing down generation.
The KV cache is one of the simplest yet most powerful optimizations in modern LLM workflows. It transforms inference from repetitive, expensive computation into fast, cost-efficient generation. In the age of agentic AI—where models are performing multi-step reasoning, tool use, and long-term planning—maximizing KV cache hit rate is no longer optional; it’s foundational.
From a practical standpoint, following prompt engineering best practices—keeping your prefix stable, maintaining an append-only context, and using deterministic serialization—can unlock dramatic savings in compute, memory, and latency. Combined with emerging attention techniques like paged and radix attention, KV cache ensures that your LLM workflows remain both performant and scalable.
In other words, the KV cache isn’t just a nice-to-have; it’s the backbone of fast, efficient, and cost-effective LLM inference.
Ready to build robust and scalable LLM Applications? Explore Data Science Dojo’s LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI systems.
Stay tuned — this is part of a 3-part deep-dive series. In the upcoming posts, we’ll unpack Paged Attention, Radix Attention, and a few other emerging techniques that push context efficiency even further. If you’re serious about building fast, scalable LLM systems, you’ll want to check back in for the next installments.
Subscribe to our newsletter
Monthly curated AI content, Data Science Dojo updates, and more.

 for all tokens X.
for all tokens X.