

Key takeaways
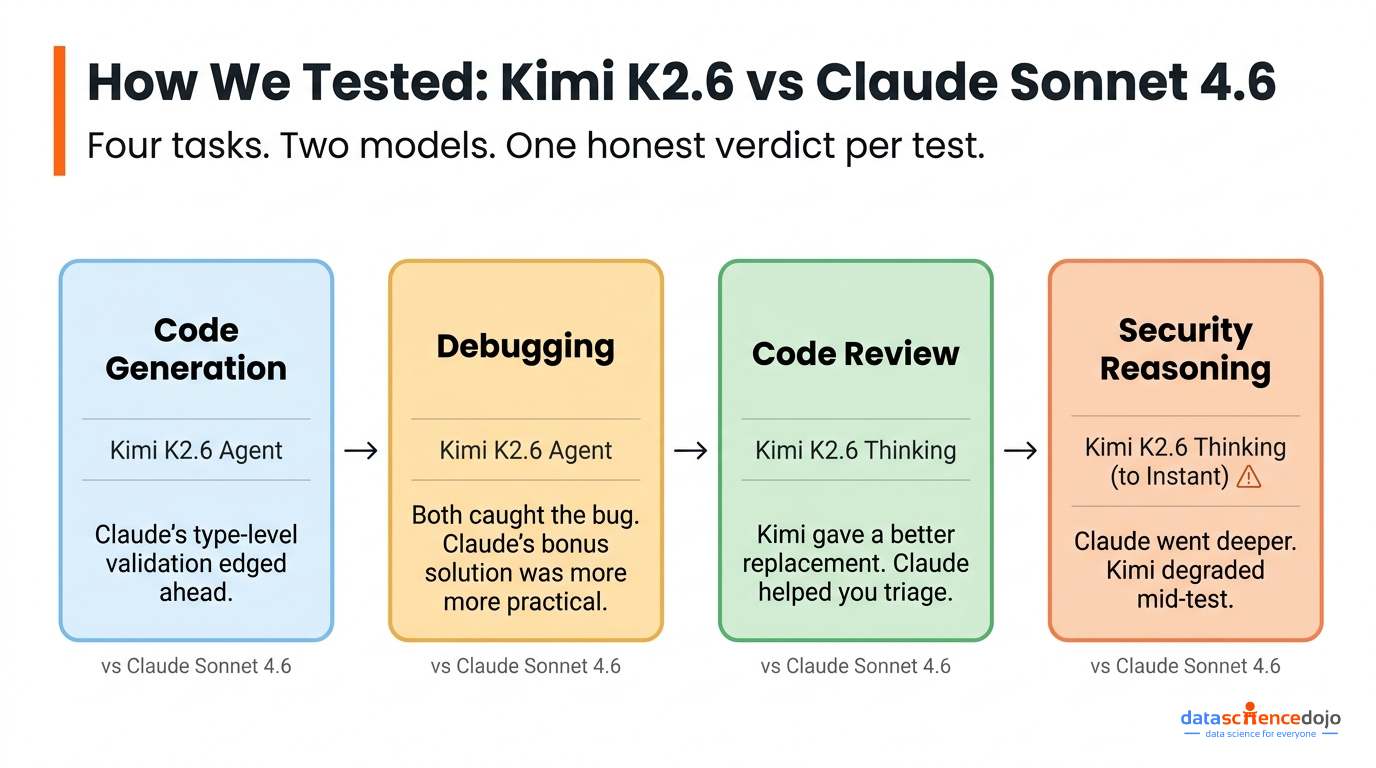
- We ran Kimi K2.6 and Claude Sonnet 4.6 through four real developer tasks: code generation, debugging, code review, and security architecture reasoning.
- Kimi K2.6 has three modes, Agent, Thinking, and Agent Swarm and they behave meaningfully differently, not just faster or slower.
- Claude Sonnet 4.6 was more consistent across tasks and leaned toward production-ready thinking; Kimi K2.6 went deeper on completeness when it ran at full capacity.
- Mid-test, Kimi K2.6 dropped from Thinking to Instant mode due to high demand. That’s worth factoring in before you build workflows around it.
The timing of this comparison wasn’t random. The week we ran these tests, a lot of developers were already eyeing Kimi as a Claude alternative — not because of benchmarks, but because Anthropic spooked them on pricing.
On April 21, 2026, Anthropic’s pricing page briefly showed Claude Code removed from the $20/month Pro plan. No email, no changelog entry, just an “X” where the checkmark used to be. Reddit and Hacker News moved fast. Within hours there were hundreds of comments, and the alternatives people were naming most often were Kimi, Minimax, and Qwen. By end of day, Anthropic’s Head of Growth had clarified it was an A/B test on roughly 2% of new signups, and the page was restored the next morning. But the comment he left behind stuck: “Usage has changed a lot and our current plans weren’t built for this.”
The change was reversed but the anxiety wasn’t and the timing happened to coincide almost exactly with the release of Kimi K2.6 on April 20. So we decided to actually test it.
What You’re Actually Comparing Here
We paired Kimi K2.6 against Claude Sonnet 4.6, Anthropic’s mid-tier model, rather than Opus, because that’s the fair fight. Both sit in the everyday-use tier in their respective families. Both are what most developers have running in production right now. Comparing it to Opus would skew the results in ways that don’t reflect how people actually choose between models.
Before we get into the tasks, it’s worth understanding how Kimi K2.6 is structured, because it’s genuinely different from how Claude works.
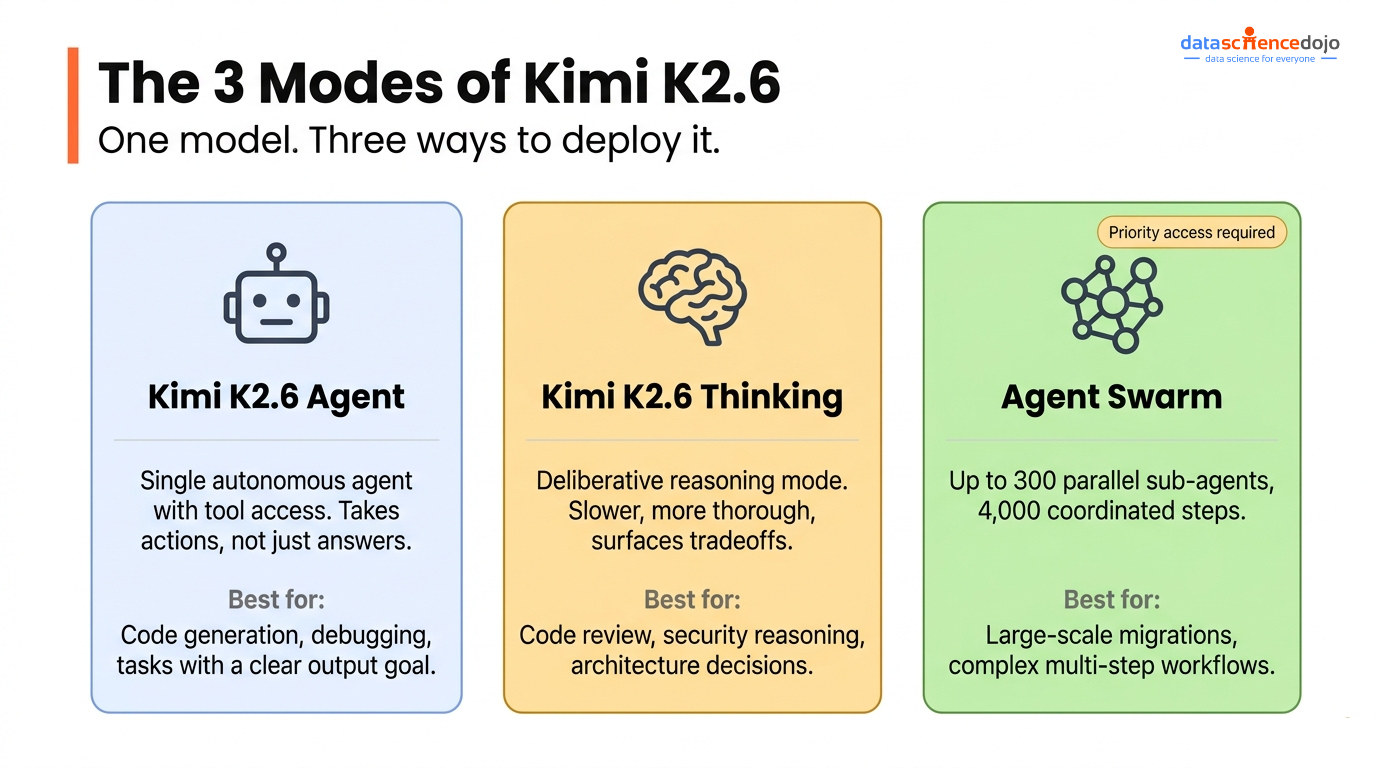
Kimi K2.6 Agent operates as a single autonomous agent with tool access. It takes actions rather than just responding, closer to a coding assistant that can actually do things.
Kimi K2.6 Thinking is the deliberative mode. It takes longer, reasons through more steps before committing, and tends to surface tradeoffs. For review and architecture tasks, this is the right mode to use.
Agent Swarm is Kimi K2.6’s most distinctive offering. Up to 300 parallel sub-agents coordinating across thousands of steps. There’s nothing quite like it in Claude’s current interface. We had planned to test it on an agentic planning task, but Agent Swarm and Agent modes currently require priority access. We couldn’t complete that test, so this comparison covers four tasks instead of five. That access gap is worth noting if you’re evaluating it for production.
For Claude Sonnet 4.6, we used standard mode across all tasks.
Kimi K2.6 vs Claude Sonnet 4.6: Feature Comparison
Before the task results, here’s the side-by-side on specs, pricing, and capabilities so you have the full picture in one place.
| Kimi K2.6 | Claude Sonnet 4.6 | |
|---|---|---|
| API pricing | $0.95 input / $4.00 output per 1M tokens | $3.00 input / $15.00 output per 1M tokens |
| Context window | 256K tokens | 1M tokens (200K standard; 1M in beta) |
| Input modalities | Text, image, video | Text, image |
| Agentic modes | Agent, Thinking, Agent Swarm (waitlisted) | Standard + Claude Code |
| Open source | Yes — Modified MIT, self-hostable | No |
| SWE-Bench Verified | 80.2% | 79.6% |
A few things worth calling out from this table. The pricing gap is real, at $0.95/$4.00 per million tokens versus $3.00/$15.00, Kimi K2.6 is roughly 3–4x cheaper on the API. For teams running high-volume coding agents or processing long contexts regularly, that difference adds up fast. A startup consuming 100M input tokens and 10M output tokens monthly pays around $85 with Kimi K2.6 versus $450 with Claude Sonnet 4.6.
The context window comparison needs a caveat though. Kimi K2.6’s 256K is generous, but Claude Sonnet 4.6’s 1M token beta window is a meaningful advantage for full-codebase analysis and long document workflows. If you need to load an entire repository into a single prompt, Sonnet 4.6 can do it at standard pricing. And while Kimi K2.6 is open source and self-hostable (a real differentiator for teams with data residency requirements or cost constraints at scale), Agent Swarm access currently requires a priority waitlist, so the most powerful mode on paper isn’t yet available to everyone on demand.
Task 1: Code Generation — Building a FastAPI Endpoint
The prompt: build a FastAPI endpoint that takes user_id and action, validates the action against an allowed list, stores events in memory, and returns a summary for that user.
Both models returned working code and neither needed cleanup. That’s the baseline and both passed.
The interesting part was the pattern each one reached for. Kimi K2.6 used a field_validator with Pydantic v2. Totally valid. Claude used Literal[“login”, “logout”, “purchase”] as the type annotation itself, which means FastAPI rejects invalid input at the type level before the handler even runs. It’s a small difference on the surface, but it reflects how you think about where constraints should live — in a method, or in the type system. For Pydantic v2 specifically, the type-level approach is the more idiomatic pattern.
Claude also added a DELETE endpoint without being asked, flagged that the in-memory store should be replaced with Redis in multi-process deployments, and mentioned Swagger UI at /docs. It added a GET endpoint and solid curl examples. Both went beyond the prompt, just in different directions. Claude’s additions were the kind of things that come up in code review. Kimi K2.6’s additions were the kind of things that make the output immediately usable.
One more practical difference: Claude rendered the endpoint as a testable artifact you could interact with inline. With the Agent mode, you copy the code, save the files, and run it locally. For developers iterating quickly, that friction adds up.
Task 2: Debugging — A Logic Bug That Looks Fine on the Surface
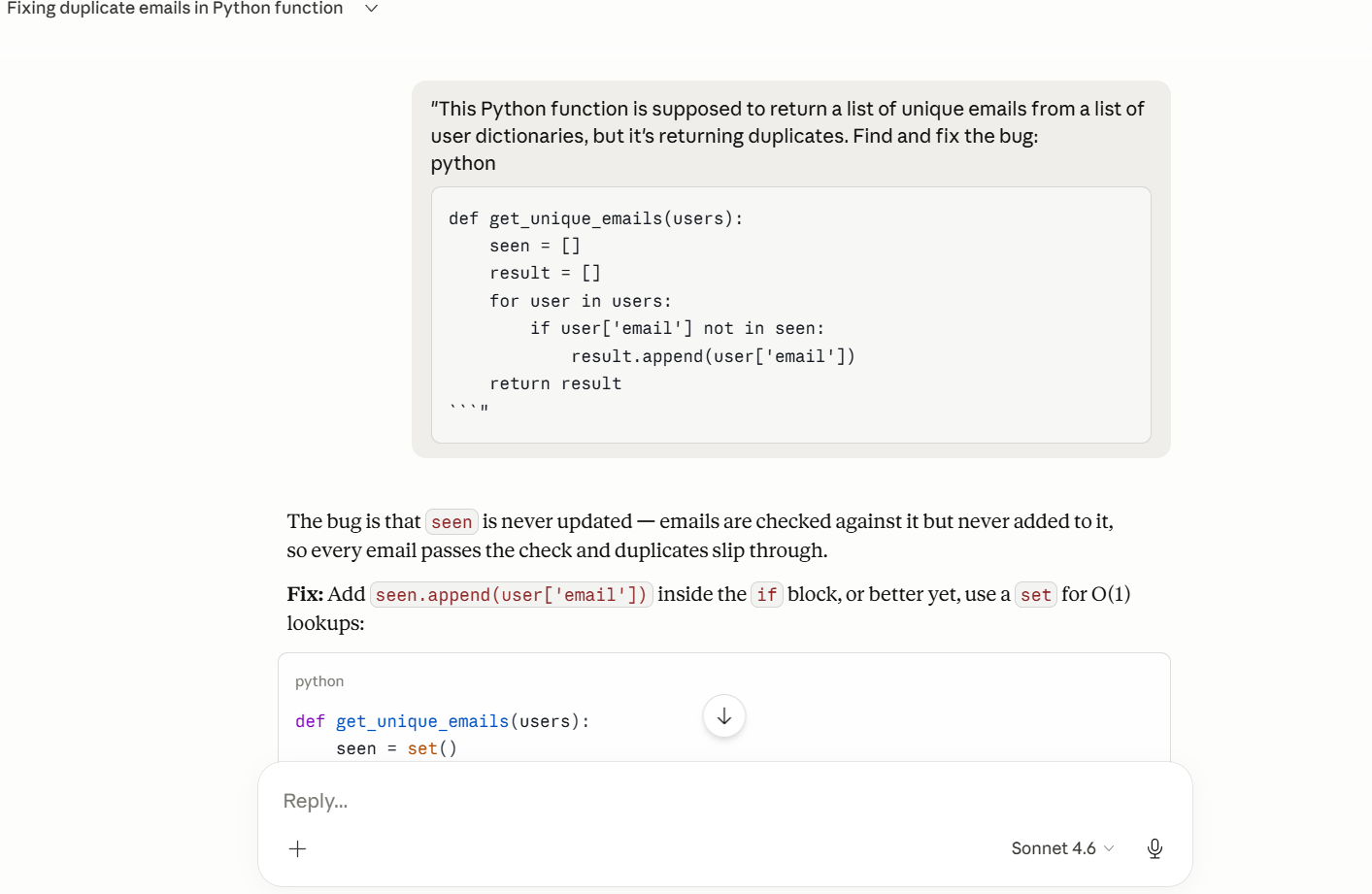
The function was supposed to return unique emails from a list of user dictionaries. The bug: seen was checked on every loop but never populated, so duplicates passed through silently. The code looked syntactically correct. There was nothing to catch in a linter.
Both models found it immediately. Both fixed it and recommended a set for O(1) lookups over the original list. On the core task, they were equal.
The difference showed up in what each model offered next. Kimi K2.6 threw in a one-liner using seen.add() inside a boolean short-circuit expression. It works, and you can see why it’s tempting to include. It’s also the kind of thing that gets flagged in a code review because it trades readability for conciseness in a way that doesn’t pay off in a real codebase.
Claude’s bonus was dict.fromkeys(). It’s a standard library idiom, it preserves insertion order, and any Python developer who reads it knows exactly what it’s doing. The O(n) vs O(1) explanation was also cleaner — not just “use a set” but a brief walkthrough of why the performance difference matters as the input scales.
Both models went beyond what was asked. One went toward showing off, the other went toward teaching.
Task 3: Code Review — A Dangerous Database Function
This one had a classic SQL injection via f-string, a connection that’s never closed, SELECT * pulling every column, no error handling, no input validation, and a hardcoded database path. Six issues stacked in a short function.
Both models found all of them. Neither missed the SQL injection, and neither missed the resource leak. At the level of “does the model know what production code quality looks like,” both cleared the bar.
Where they diverged was in how they organized the findings. Claude led with severity labels, Critical, High, Medium and finished with a summary table. That structure matters in practice: it tells you what to fix before you ship and what can wait for the next sprint. It also framed SELECT * as a security issue rather than just a performance one. Most developers know that pulling all columns is wasteful; fewer think about the fact that it likely returns password hashes, tokens, and admin flags to wherever the result lands. Claude made that explicit.
K2.6 caught two issues Claude didn’t mention — missing docstring and absent type hints — and its refactored version reflected that. The rewrite came back with a full docstring including Args, Returns, and Raises sections, typed parameters using Optional[Tuple[Any, …]], and a ValueError for empty or invalid inputs. If you needed a drop-in replacement you could commit immediately, its output was closer to ready.
The practical split: Claude’s output helps you triage. K2.6’s output gives you the replacement. Depending on what stage you’re at, one of those is more useful than the other.
Task 4: Multi-Step Reasoning — Rate Limiting an Auth Flow

The task: Restructure a six-step login service to add IP-based rate limiting before any database query, identify what new components are needed, and describe what could go wrong if implemented incorrectly.
Before the results, something happened mid-test that’s worth being upfront about. Kimi K2.6 hit high demand during this task and automatically dropped from Thinking to Instant mode. It told us, and offered an upgrade path. The response we got was Instant mode output, not Thinking mode. That matters for interpreting the results below and it matters for anyone evaluating K2.6 for workflows where consistent reasoning depth is a requirement.
The response itself was still solid. K2.6 restructured the flow correctly with the rate limit as the first gate, identified Redis with atomic INCR + EXPIRE as the right approach, flagged race conditions in non-atomic read-then-write patterns, laid out the fail-open vs fail-closed tradeoff, and caught the shared-IP / NAT problem with per-IP rate limiting. It also flagged clock skew in sliding window implementations — a genuinely obscure edge case that a lot of architects wouldn’t think to include.
Claude covered the same core ground and found a few things on top of it. One was a design decision that’s easy to overlook: should the rate limiter count all login attempts from an IP, or only the failed ones? If you only count failures, an attacker who occasionally succeeds with a throwaway account can keep resetting their counter. Claude called this out explicitly and explained why it matters under adversarial conditions. It also caught a timing side-channel: if the rate limiter sits after the database query, response latency differences can reveal whether a username exists even when the request is ultimately rejected. And it added the Retry-After header — not in the prompt, not something most people think about first, but something that prevents legitimate clients from hammering the endpoint during backoff.
The gap between the outputs here reflects something real: Claude’s response read like it was written by someone thinking about what breaks in production, not just what the correct architecture looks like on a whiteboard. Whether that gap would have been smaller if Kimi K2.6 had stayed in Thinking mode, we can’t say. But the mode degradation itself is part of the result.
What We Actually Took Away From This
Kimi K2.6 is genuinely capable — and in some areas, notably code completeness and certain deep reasoning tasks, it goes further than Sonnet 4.6. Its Thinking mode produces thorough output when it runs at full capacity, and the refactored code it returns is often closer to production-ready than what Claude gives you. The three-mode interface is also a real differentiator: being able to choose between a fast agent, a deliberative reasoner, and a massively parallel swarm depending on the task is something no other model in this comparison class currently offers.
Claude Sonnet 4.6 is more consistent. Across four tasks, it ran without degradation, and its outputs reflected a stronger read on what code needs to be maintainable over time — not just correct at the moment of generation. The things it added unprompted (the Literal type, the Retry-After header, the security framing on SELECT *) were the kind of additions that save you a ticket later.
The mode reliability issue is the most honest thing we can say about the current state of using it in a real workflow. If you’re evaluating a model for something you need to depend on, “it fell back to a different mode under load” is a relevant data point — separate from how good the output is when everything runs as intended.
If you’re building agentic workflows and want to explore what an open-source model purpose-built for long-horizon execution looks like, Kimi K2.6 is worth your time once access opens more broadly. If you need a reliable, production-aware model for everyday developer work right now, Sonnet 4.6 is the more consistent choice today.
FAQs
What is Kimi K2.6? It is Moonshot AI’s latest open-source model, released April 20, 2026. It runs on a Mixture-of-Experts architecture with 1 trillion total parameters (32 billion active per token), supports text, image, and video input, has a 256K context window, and offers three execution modes: Agent, Thinking, and Agent Swarm. It’s built specifically for long-horizon coding and autonomous multi-agent workflows.
What is Claude Sonnet 4.6? Claude Sonnet 4.6 is Anthropic’s mid-tier model in the Claude 4.6 family, released February 17, 2026. It’s the default model on Claude.ai’s free tier and the one most developers are using in production coding workflows today.
Why compare it to Sonnet and not Opus? Both models 4.6 are the practical everyday-use choice in their respective families. Comparing it against Opus 4.6 would tell you less about where these two actually compete — most developers choosing between them aren’t in the Opus pricing tier.
How does it benchmark against Claude on coding tasks? On SWE-Bench Pro at release, K2.6 scores 58.6 vs Claude Opus 4.6’s 53.4. On SWE-Bench Verified, K2.6 scores 80.2 and Claude Sonnet 4.6 scores 79.6 — essentially the same. The benchmarks are close enough that practical output quality, consistency, and workflow fit matter more than the numbers alone.
What is K2.6 Agent Swarm and what is it good for? Agent Swarm is K2.6’s most distinctive mode — it coordinates up to 300 parallel sub-agents across up to 4,000 steps. It’s designed for tasks that can be broken into parallel, specialized workstreams: large-scale codebase migrations, comprehensive research pipelines, multi-format content generation at scale. There’s no direct equivalent in Claude’s current product. Access currently requires a priority waitlist.
Is it free to use? Yes, it is available free at kimi.com. Paid plans unlock higher usage limits and additional features. The model weights are also open-sourced under a Modified MIT License for developers who want to self-host using vLLM or SGLang.